PASCAL VOC 2012 数据集解析
目录
一、Introduction
Classification/Detection Competitions
Segmentation Competition
Action Classification Competition
ImageNet Large Scale Visual Recognition Competition
Person Layout Taster Competition
二、Data
三、VOC2012 VS. VOC2011
四、Development Kit
五、Test Data
六、分割数据集
1、VOC2012
2、SBD
3、如何得到训练集10582?
4、语义分割训练数据制作
七、参考资源
一、Introduction
该数据集的主要目的是建立针对实际场景中的视觉目标进行识别的挑战任务。基于标注的图像数据,它是基本的有监督学习问题。数据集中总共有20类目标需要识别:
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
基于上述数据集,有三项视觉目标识别任务:分类(classification),检测(detection),分割(segmentation)。 ImageNet提供了另外一个大规模目标识别数据集,主要用于分类任务。此外,还有一个 Person Layout Taster 数据集,主要识别人体的头、手、脚的位置。
Classification/Detection Competitions
-
Classification: 给定一张测试图片,判别其中每一个目标所属类别,类别必须属于20类之一;
- Detection: 给定测试图片,预测图片中每一个目标的 bounding box(位置) and label(类别);

参赛者可以选择上述的任意一种挑战任务,处理任意类或者全部类目标,该挑战可以允许两类方法:
- 除了测试集,参赛者可以使用任意的方法和数据建立或者训练系统,目的是为了评估当前算法能够达到的基本水平;
- 使用官方提供的训练和验证集建立系统,目的是为了评测不同算法的性能;
Segmentation Competition
Segmentation: 给出图片中每一个像素所属的类别,否则就是背景类。
Action Classification Competition
Action Classification: 判定静态图片中人的活动类别,总共10类。

ImageNet Large Scale Visual Recognition Competition
参考ImageNet官网:http://www.image-net.org/challenges/LSVRC/2012/index
Person Layout Taster Competition
Person Layout: 预测人体部位的矩形框位置,主要是头,手,脚。

二、Data
To download the training/validation data, see the Development Kit section.
- 目标检测中的每一张图片标注信息包括:bounding box and object class label. 需要注意的是,一张图片中可能包含属于多个类别的多个目标。标注的相关规则和注意的细节,参考 guidelines.
- 原始数据中的一部分图像被标注为像素级分割标签,每一个像素都标注了所属类别,提供了语义分割的竞赛挑战数据集。
- 用于动作分类任务的数据集与 classification/detection/segmentation tasks 的数据集是分开的。其中一部分被标注为people、bounding box、reference points and their actions. 标注规则和细节,参考guidelines。
- 用于person layout taster的图像,测试集从主任务中分开,额外的标注了人的每一部分,主要是 head/hands/feet.
- 数据分为两个阶段提供,1、Development Kit 会更新训练集和验证集,以及评估软件(MATLAB)。验证集的目的是为了在提交到官方评测集之前,评估算法的性能。2、测试集用于实际的评估,在VOC2008-2011竞赛中,测试集没有真实标签。
- 数据被分为 training/validation and testing,每一部分数据量差不多,数据的详细分布,参考:Statistics.
三、VOC2012 VS. VOC2011
VOC2012数据集主要是为了增加分割(segmentation)和动作分类(action classification)数据集的数量,classification/detection tasks没有增加标注数据集。下面列举了VOC2012 和 VOC2011的差别:
- Classification/Detection: 没有增加额外标注的数据。
- Segmentation: 在 VOC2008-2011 的基础上,VOC2012 增加了标注数据,数量从7062增加到9993(有这么多?).
- Action Classification: 在VOC2011基础上,增加了额外的标注数据。为了弥补"boxless"的动作分类任务,除了标注 box annotation, 人的身体上被标注了参考点。具体可以参考(development kit)。
- Person Layout Taster: 没有增加额外标注数据。
四、Development Kit
The development kit consists of the training/validation data, MATLAB code for reading the annotation data, support files, and example implementations for each competition.
The development kit is now available:
- Download the training/validation data (2GB tar file)
- Download the development kit code and documentation (500KB tar file)
- Download the PDF documentation (500KB PDF)
- Browse the HTML documentation
- View the guidelines used for annotating the database (VOC2011)
- View the action guidelines used for annotating the action task images
五、Test Data
The test data will be made available according to the challenge timetable. Note that the only annotation in the data is for the action task and layout taster. As in 2008-2011, there are no current plans to release full annotation - evaluation of results will be provided by the organizers.
The test data can be downloaded from the evaluation server. You can also use the evaluation server to evaluate your method on the test data.
六、分割数据集
在学习语义分割系列算法时,经常会看到下面的一段话:
The original dataset contains 1 , 464 ( train), 1 , 449 ( val), and 1 , 456 ( test) pixel-level labeled images for training, validation, and testing, respectively. The dataset is augmented by the extra annotations provided by [29], resulting in 10, 582 ( trainaug) training images.
如上所示,通常语义分割涉及两个数据集官方PASCAL VOC 2012 和 SBD,相应的下载链接如下:
VOC2012:VOCtrainval_11-May-2012.tar(~2GB)
SBD:benchmark.tgz(~1.3G)
1、VOC2012

下载的官方 VOCtrainval_11-May-2012.tar 解压后,目录结构如上图所示,该部分只介绍用于分割的数据集。
ImageSets:该目录下Segmentation文件夹总共有三个文件,train.txt:训练集名字列表,1464个文件,val.txt:验证集名字列表,1449个文件,trainval.txt:训练集和验证集的集合,2913个文件。
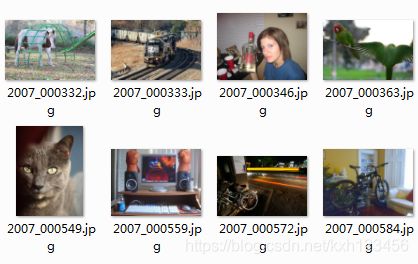
JPEGImages:所有的原始图片,17125个文件,部分示例图片如下右图所示。
SegmentationClass:所有的标签图,2913个文件,部分示例图片如下左图所示。

2、SBD
通常语义分割论文使用的 trainaug dataset 是SBD和官方VOC2012合并而来,其中SBD数据集分布:8498 (train), 2857 (val)。
img:该目录包含了所有的原始图片,11355个JPG文件。
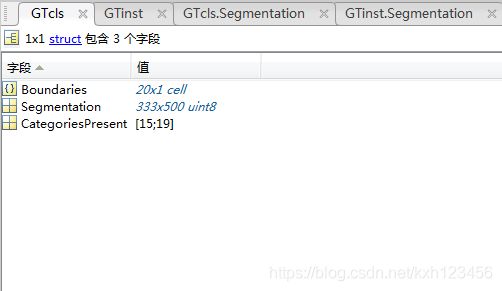
cls:该目录包含111355个mat标签文件,与img的JPG一一对应。每一个mat文件指定了类别和目标的边界,mat文件结构如下:
- GTcls.Segmentation is a single 2D image containing the segmentation. Pixels that belong to
category k have value k, pixels that do not belong to any category have value 0.
- GTcls.Boundaries is a cell array. GTcls.Boundaries{k} contains the boundaries of the k-th category.
These have been stored as sparse arrays to conserve space, so make sure you convert them to full arrays
when you want to use them/visualize them, eg : full(GTcls.Boundaries{15})
- GTcls.CategoriesPresent is a list of the categories that are present.

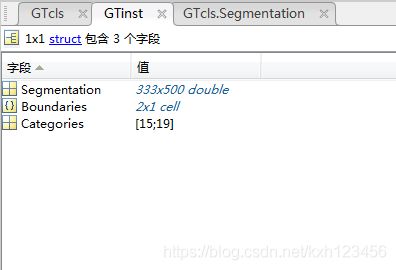
inst:该目录的每一个mat文件包含了像素级分割和边界标签,mat文件结构如下:
- GTinst.Segmentation is a single 2D image containing the segmentation. Pixels belonging to the
i-th instance have value i.
- GTinst.Boundaries is a cell array. GTinst.Boundaries{i} contains the boundaries of the i-th instance.
Again, these are sparse arrays.
- GTinst.Categories is a vector with as many components as there are instances. GTinst.Categories(i) is
the category label of the i-th instance.
3、如何得到增强训练集10582?
如上面陈述,通常 trainaug 的数量为10582,该数字获取方式如下:
VOC数据集分布:
- voc_trainval:2913
- voc_train:1464
- voc_val:1449
SBD数据集分布:
- sbd_train:8498
- sbd_val:2857
通过对比其中图片文件名重合情况(具体如何比对,可以写代码或者直接文件复制粘贴),可以得到:
sbd_train(8498) = 和voc_train重复的图片(1133) + 和voc_val重复的图片(545) + sbd_train真正补充的图片(6820)
sbd_val(2857) = 和voc_train重复的图片(1) + 和voc_val重复的图片(558) + sbd_val真正补充的图片(2298)
所以可以得到的最大的扩充数据集应为:
12031张标注图 = voc_train(1464) + voc_val(1449) + sbd_train真正补充的图片(6820) + sbd_val真正补充的图片(2298)
用原来的voc_val(1449)作为验证集,剩下的12031-voc_val(1449)=10582都可以用作训练,就是trainaug(10582)。
4、语义分割训练数据制作
该部分主要介绍如何制作用于语义分割的训练数据制作,制作的基本流程如下:
- VOC2012标签制作
- SBD mat数据转图片
- 合并VOC和SBD,保存文件名 trainval.txt
- 根据原始图片,生成 tfrecord文件
(a)VOC2012 标签制作
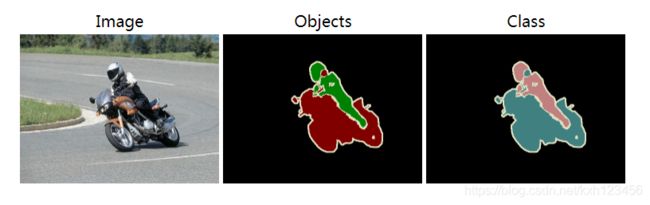
下面左图为原始图片,中间的图是官方提供的标注图,参考 download_and_convert_voc2012.sh,可以将中间的图片处理为右边的图片。右图中,背景像素值为 0,人的区域像素值为 15(人属于第15类),飞机区域的像素值为 1(飞机为第1类)。



(b)SBD mat 数据转换
数据转换工具 Mat2PNG,可以将mat标签转为灰度图,具体命令为:
python mat2png.py $DATASETS/VOC_aug/dataset/cls $DATASETS/VOC_aug/dataset/cls_png
(c)合并数据集
参考(3、如何得到训练集10582?)中介绍,合并后的名字列表为trainval.txt,也可以从(b)中的链接中直接下载名字列表。
(d)生成TFRecord
参考TensorFlow官网代码 build_voc2012_data.py,可以生成相应的TFRecord文件。
七、参考资源
- https://blog.csdn.net/lscelory/article/details/98180917
- http://home.bharathh.info/pubs/codes/SBD/download.html
- https://blog.csdn.net/iamoldpan/article/details/79196413
- http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
- https://blog.csdn.net/cncyww/article/details/89188506
- https://blog.csdn.net/zz2230633069/article/details/84769339