【毕业设计_课程设计】基于特征熵值分析的网站分类系统实现(源码+论文)
文章目录
- 0 项目说明
- 1 研究目的
- 2 研究方法
- 3 研究结论
- 4 各模块介绍
-
- 4.1 爬虫模块功能与技术
- 4.2 网页处理模块功能与技术
- 4.3 特征提取与文本特征表示模块功能与技术
- 4.4 分类器模块功能与技术
- 5 项目源码
0 项目说明
基于特征熵值分析的网站分类系统实现
提示:适合用于课程设计或毕业设计,工作量达标,源码开放
1 研究目的
本设计对KNN 算法的缺陷产生原因进行详细地分析,并针对缺陷对算法进行了引入属性熵值等一系列的改进,使得改进的 KNN 算法达到高速、高精度的性能,并且基于改进后的新 KNN 算法,搭建一个真正实用性强的网站分类系统。
2 研究方法
采用了语言 Python(Python 2.7.5)来对系统进行全方面设计,系统实现的平台是 Unix 操作系统。基础的爬虫搭建和页面处理涉及的分词技术均非设计重点,且稳定性要求较高, 所以这两者分别采用了目前相对稳定强大的开源工具 Scrapy 和 Jieba 分词。
3 研究结论
最终本系统利用个 3578 个真实网站内容作为测试集对系统进行了性能测试,最终的成绩是分类精度达到 85.05%,平均一个网页的分类速度是 0.88 秒。

4 各模块介绍
4.1 爬虫模块功能与技术
爬虫模块的功能:简而言之就是依照给出的 URL 去下载对应的 HTML 文档进 而用于下一步分析。从使用者的角度看,用户输入 URL,如果该 URL 尚未被收录, 那么下载对应 HTML 文档;从构建分类器的角度看,训练集的建立需要各个类别 下大量真实的网站,需要对每个类别下的 URL 进行下载 HTML 文档作为训练集的 生成。 涉及的技术实现:这个模块相对简单,需要编写一个高效的爬虫,下载页面内 容存入 HTML 文档即可。但是,由于目前中文网站编码良莠不齐,下载页面内容 存入 HTML 文档时可能遇到网页编码不统一而导致的下载页面乱码问题,我们需 要注意设计的爬虫应该由对各种网页编码的转换处理能力。
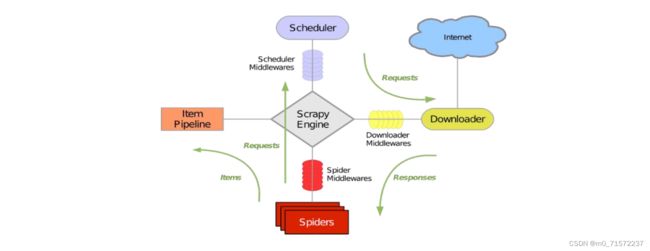
4.2 网页处理模块功能与技术
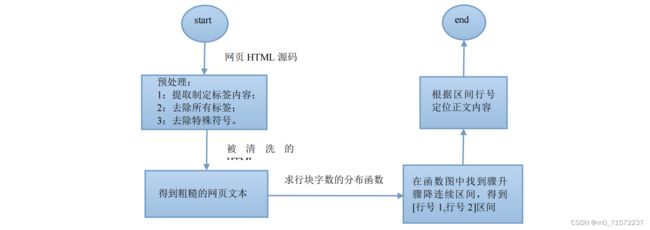
网页处理模块的功能:为了提取出可以反映、暗示网站类别或者对网站所属类 别有指导性的一些标签内容,需要对网页进行某些标签内容的提取,比如 HTML 文档的标题提取、META 元标签的提取、正文提取等。提取出这些内容组合成一 个短文本并分词后作为网站内容的简写形式,以便特征提取模块进行特征提取。 涉及的技术实现:对于HTML文档中的标题TITLE标签、元数据META标签, 使用正则表达式技术可以高效、无误差地提取;而正文提取不是很容易,需要设 计或者参考一种正文提取方法,在本设计中,最终参考了一种线性时间复杂度的基于行块分布函数的正文提取方法。之后,需要一种分词技术来把短文本切分为 词的集合。
4.3 特征提取与文本特征表示模块功能与技术
特征提取和模块的功能:对于训练网页集经过页面处理模块生成的短文本词集 合形态,本模块需要根据训练集中所有词在每个类别下的分布情况利用一种特征 提取方法进行特征的提取,找出最能代表和支持类别的那些词作为特征项,然后 用数学的形式将这些训练数据保存,形成最终的训练集用于分类器的训练。而对 于测试页面或者用户输入的未标注类别 URL 经页面处理模块生成的短文本词集合 形态,本模块也需要将其转化为数学表示形式以作为分类器输入。 涉及的技术实现:我们需要在目前成熟的特征提取技术中选取一个最适合的方 法,在目前已有的特征提取方法中,本设计选择了卡方检验(CHI)方法,并且在 分析了这个方法的缺陷产生原因后,提出了一种改进的卡方检验方法。文本特征 的数学化表示方法中,本设计考虑到向量空间模型(VSM)在目前的文本分类中 效果较好,于是采用了 VSM 表示方法。而且为了反映每个特征项的权重,引入了 TF*IDF 方法来计算在每个文本向量中每个维度(即每个特征项)的向量值。
4.4 分类器模块功能与技术
分类器模块功能:顾名思义,分类器就是用来分类的,用户输入的 URL 经过 上述几个模块的处理后生成的文本向量 VSM 作为分类器的输入,分类器进行计算 后输出自己对输入的类别猜测作为该 URL 的最终判定类别。 涉及的技术实现:由于 K 邻近算法(KNN)在文本向量模型下是最好的文本 分类算法之一,本设计中的分类器基于 KNN 算法。在对传统 KNN 算法进行缺陷 研究后,本文罗列出 KNN 算法运行时间慢和分类精度不高的主要原因,在运行时 间上结合 Rocchio 算法、建立倒排索引、建立“位置向量”等思路,同时在分类精 度上结合了属性熵值分析、类别加权、类别平均相似度、共有特征个数等因素改 进分类策略,从而设计出一种新的改进 KNN 算法,这个算法拥有高效、高精度的 特性。
