学习专栏-关于Python读取数据学习记录
给大家分享一下我学Python的读取数据的学习记录

1.抽取一行代码

import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
data=[[110,110,99],[105,88,115],[109,120,130],[112,115]]
name=['明日','七月流火','高袁圆','二月二']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=name,columns=columns)
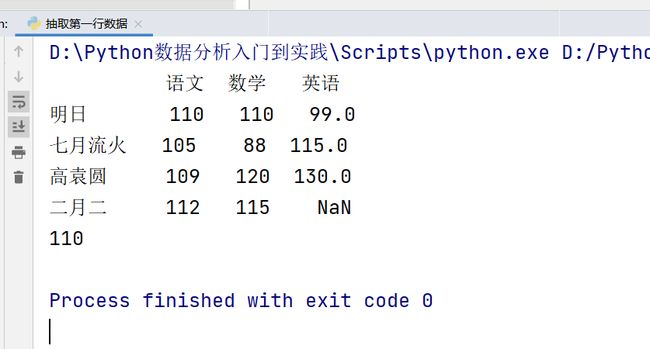
print(df)
print(df.loc['明日','语文'])
结果:
2.抽取多行数据
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
data=[[110,110,99],[105,88,115],[109,120,130],[112,115]]
name=['明日','七月流火','高袁圆','二月二']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df.loc[['明日','高袁圆']]) #抽取多行数据的语法是loc[['例子1','例子2']]
print(df.iloc[[0,2]]) #抽出多行数据的语法2是iloc[['1','2']]
1、连续抽取多行的数据
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
data=[[110,110,99],[105,88,115],[109,120,130],[112,115]]
name=['明日','七月流火','高袁圆','二月二']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df.loc['明日':'二月二']) #从’明日‘到‘二月二’ #这个很好理解。就是:就是一个索引,从明日到二月二
print(df.loc[:'七月流火':]) #从第1行到'七月流火' #这个就是:七月流火: 意思就是从顺序头是第一行,结尾就是中间的字眼"七月流火"
print(df.iloc[0:4]) #从第1行到第4行 #索引0-4的范围内容
print(df.iloc[1::]) #第2行到最后一行 #1代表索引起头 :代表结尾
2、抽取列的的数据
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
data=[[110,110,99],[105,88,115],[109,120,130],[112,115]]
name=['明日','七月流火','高袁圆','二月二']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df[['语文','数学']]) #抽取列数据只需输入列名即可进行抽取
3、使用loc属性和iloc属性

上代码:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
data=[[110,110,99],[105,88,115],[109,120,130],[112,115]]
name=['明日','七月流火','高袁圆','二月二']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print(df.loc[:,['语文','数学']]) #抽取"语文"和"数学" 抽取指定列数据为:df.loc[:,['列名1','列名2']]
print(df.iloc[:,[0,1]]) #抽取第1列和第二列 抽取指定的列序号 df.iloc[:,[列名的序号,列名的序号]]
print(df.loc[:,'语文':]) #抽取从"语文"开始到最后一列 抽取从哪一列到哪一列 df.loc[:,'开始的列名':]
print(df.iloc[:,:2]) #连续抽取从1列开始到第三列 但不包括第3列 抽取开始列到结尾列的数据但是不包括最后一列
print(df)总表的结果
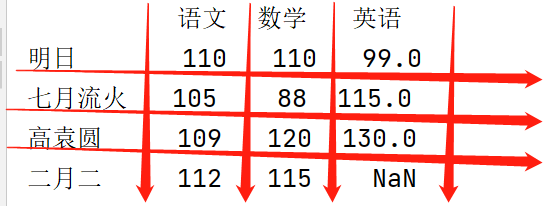
运行代码的结果

5、抽取指定行列数据

代码如下:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
data=[[110,110,99],[105,88,115],[109,120,130],[112,115]]
name=['明日','七月流火','高袁圆','二月二']
columns=['语文','数学','英语']
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
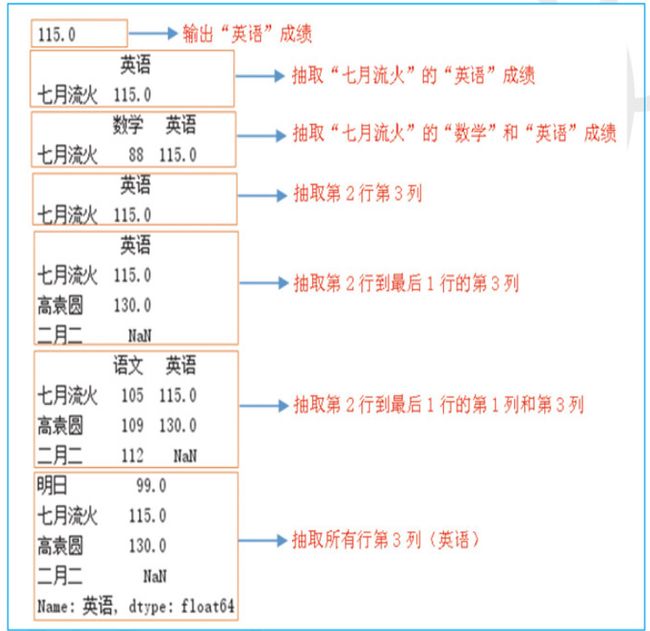
print(df.loc['七月流火','英语']) #英语成绩 直接输出行列 语法为 def.loc['行名','列名']
print(df.loc[['七月流火'],['英语']]) #"七月流火"的"英语"成绩 输出指定的行和列的数据并且带行名和列名
# 语法为 df.loc[['行名','列名']]
print(df.loc[['七月流火'],['数学','英语']]) #"七月流火"的“数学”和"英语"成绩 输出七月流火行的列的成绩
#语法为 df.loc[['行名'],[‘列名1’,'列名2']]
print(df.iloc[[1],[2]]) #第2行第3列 按序号输出行和列 语法为:df.iloc[[1],[2]]
print(df.iloc[1:,[2]]) #第2行到最后一行的第3列 输出指定的行号到最后一行的列名 df.iloc[行序号:,[列序号]]
print(df.iloc[1:,[0,2]]) #第2行到最后一行的第1列和第3列
# 输出指定的行号到最后一行的多个列名 df.iloc[行序号:,[列序号1],[列序号2]]
print(df.iloc[:,2]) #所有行,第3列 输出所有行并输出指定列 语法为:df.iloc[:,列序号]
执行效果

有在学Python的同学看到这篇文章麻烦给我点个赞和关注,谢谢!
