ribbon
Ribbon详解 - 简书
简介
Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflix Ribbon实现。通过Spring Cloud的封装,可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡的服务调用。Spring Cloud Ribbon虽然只是一个工具类框架,它不像服务注册中心、配置中心、API网关那样需要独立部署,但是它几乎存在于每一个Spring Cloud构建的微服务和基础设施中。因为微服务间的调用,API网关的请求转发等内容,实际上都是通过Ribbon来实现的,包括后续我们将要介绍的Feign,它也是基于Ribbon实现的工具。所以,对Spring Cloud Ribbon的理解和使用,对于我们使用Spring Cloud来构建微服务非常重要。
在这一章中,我们将具体介绍如何使用Ribbon来实现客户端的负载均衡,并且通过源码分析来了解Ribbon实现客户端负载均衡的基本原理。
客户端负载均衡
负载均衡在系统架构中是一个非常重要,并且是不得不去实施的内容。因为负载均衡是对系统的高可用、网络压力的缓解和处理能力扩容的重要手段之一。我们通常所说的负载均衡都指的是服务端负载均衡,其中分为硬件负载均衡和软件负载均衡。硬件负载均衡主要通过在服务器节点之间按照专门用于负载均衡的设备,比如F5等;而软件负载均衡则是通过在服务器上安装一些用于负载均衡功能或模块等软件来完成请求分发工作,比如Nginx等。不论采用硬件负载均衡还是软件负载均衡,只要是服务端都能以类似下图的架构方式构建起来:
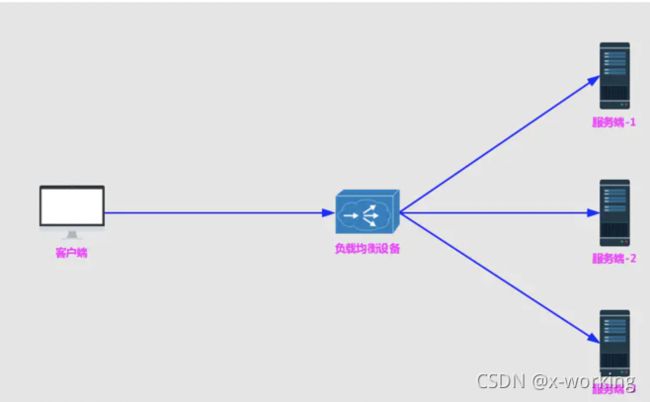
负载均衡架构图
硬件负载均衡的设备或是软件负载均衡的软件模块都会维护一个下挂可用的服务端清单,通过心跳检测来剔除故障的服务端节点以保证清单中都是可以正常访问的服务端节点。当客户端发送请求到负载均衡设备的时候,该设备按某种算法(比如线性轮询、按权重负载、按流量负载等)从维护的可用服务端清单中取出一台服务端端地址,然后进行转发。
而客户端负载均衡和服务端负载均衡最大的不同点在于上面所提到服务清单所存储的位置。在客户端负载均衡中,所有客户端节点都维护着自己要访问的服务端清单,而这些服务端端清单来自于服务注册中心,比如上一章我们介绍的Eureka服务端。同服务端负载均衡的架构类似,在客户端负载均衡中也需要心跳去维护服务端清单的健康性,默认会创建针对各个服务治理框架的Ribbon自动化整合配置,比如Eureka中的org.springframework.cloud.netflix.ribbon.eureka.RibbonEurekaAutoConfiguration,Consul中的org.springframework.cloud.consul.discovery.RibbonConsulAutoConfiguration。在实际使用的时候,我们可以通过查看这两个类的实现,以找到它们的配置详情来帮助我们更好地使用它。
通过Spring Cloud Ribbon的封装,我们在微服务架构中使用客户端负载均衡调用非常简单,只需要如下两步:
▪️服务提供者只需要启动多个服务实例并注册到一个注册中心或是多个相关联的服务注册中心。
▪️服务消费者直接通过调用被@LoadBalanced注解修饰过的RestTemplate来实现面向服务的接口调用。
这样,我们就可以将服务提供者的高可用以及服务消费者的负载均衡调用一起实现了。
前提
在上一章中,我们已经通过引入Ribbon实现了服务消费者的客户端负载均衡功能,读者可用通过查看第3章中的“服务发现与消费”一节来获取实验示例。其中,我们使用了非常有用的对象RestTemplate。该对象会使用Ribbon的自动化配置,同时通过配置@LoadBalanced还能够开启客户端负载均衡。之前我们演示了通过RestTemplate实现了最简单的服务访问,下面我们将详细介绍RestTemplate针对几种不同请求类型和参数类型的服务调用实现。
GET 请求
在RestTemplate中,对GET请求可以通过如下两个方法进行调用实现。
第一种:getForEntity函数。该方法返回的是ResponseEntity,该对象是Spring对HTTP请求响应的封装,其中主要存储了HTTP的几个重要元素,比如HTTP请求状态码的枚举对象HttpStatus(也就是我们常说的404、500这些错误码)、在它的父类HttpEntity中还存储着HTTP请求的头信息对象HttpHeaders以及泛型类型的请求体对象。比如下面的例子,就是访问USER-SERVER服务端/user请求,同时最后一个参数didi会替换url中的{1}占位符,而返回的ResponseEntity对象的body内容类型会根据第二个参数转换为String类型。

若我们希望返回body是一个User对象类型,也可以这样实现:

上面的例子是比较常用的方法,getForEntity函数实际上提供了以下三种不同的重载实现。
▪️getForEntity(String url, Class responseType,Object... urlVariables);
该方法提供了三个参数,其中url为请求的地址,responseType为请求响应体body的包装类型,urlVariables为url中的参数绑定。GET请求的参数绑定通过使用url中拼接的方式,比如http://USER-SERVICE/user?name=didi,我们可以像这样自己将参数拼接到 url中,但更好的方法是在url中使用占位符并配合urlVariables参数实现GET请求的参数绑定,比如url定义为:getForEntity("http://USER-SERVICE/user?name={1}", String.class, "didi"),其中第三个参数didi会替换掉url中的{1}站位符。这里需要注意的是,由于urlVariables参数是一个数组,所以它的顺序会对应url中占位符定义的数字顺序。
▪️getForEntity(String url, Class responseType, Map urlVariables);
该方法提供的参数重,只有urlVariables的参数类型与上面的方法不同。这里使用了Map类型,所以使用该方法进行参数绑定时需要再占位符中指定Map中的参数的key值,比如url定义为http://USER-SERVICE/user?name={name},在Map类型的urlVariables中,我们就需要put一个key为name的参数来绑定url中{name}占位符的值,比如:

▪️getForEntity(URI url, Class responseType)
该方法使用uri对象来代替之前url和urlVariables参数来指定访问地址和参数绑定。URI是JDK java.net包下单一个类,它表示一个统一资源标识符(Uniform Resource Identifier)引用,比如下面的例子:

更多关于如何定义一个URI的方法可以参见JDK文档,这里不做详细说明。
第二种:getForObject函数。该方法可以理解为对getForEntity的进一步封装,它通过HttpMessageConverterExtractor对HTTP的请求响应体body内容进行对象转换,实现请求直接返回包装好的对象内容。比如:
RestTemplate restTemplate = new RestTemplate();
String result = restTemplate.getForObject(uri, String.class);
当body是一个User对象时,可以直接这样实现:
RestTemplate restTemplate = new RestTemplate();
User result = restTemplate.getForObject(uri, User.class);
当不需要关注请求响应除body外的其他内容时,该函数就非常好用,可以少一个从Response中获取body的步骤。它与getForEntity函数类似,也提供了三种不同的重载实现。
▪️getForObject(String url, Class responseType, Object ... urlVariables)
▪️getForObject(String url, Class responseType, Map urlVariables)
▪️getForObject(URI url, Class responseType)
POST 请求
在RestTemplate中,对POST请求时可以通过如下三个方法调用实现。
▪️第一种:postForEntity函数。
该方法同GET请求中的getForEntity类似,会在调用后返回ResponseEntity对象,其中T为请求响应的body类型。比如下面这个例子,使用postForEntity提交POST请求到USER-SERVICE服务的/user接口,提交的body内容为user对象,请求响应返回的body类型为String。
postForEntity函数
postForEntity函数也实现了三种不同的重载方法。
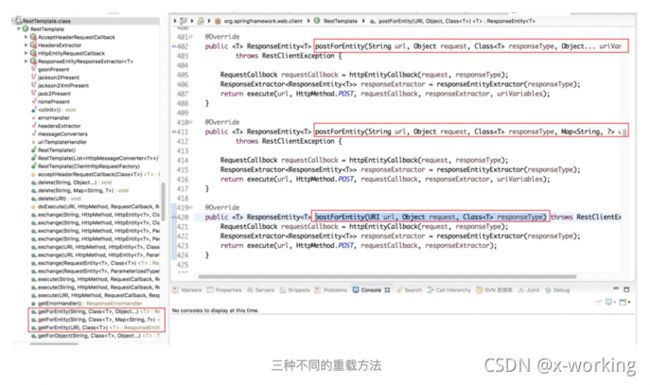
▪️postForEntity(String url, Object request, Class responseType, Object... uriVariables)
▪️postForEntity(String url, Object request, Class responseType, Map uriVariables)
▪️postForEntity(URI url, Object request, Class responseType)
这些函数中的参数用法大部分与getForEntity一致,比如,第一个重载函数和第二个重载函数中的uriVariables参数都用来对url中的参数进行绑定使用;responseType参数是对请求响应的body内容的类型定义。这里需要注意的是新增加的request参数,该参数可以是一个普通对象,也可以是一个HttpEntity对象。如果是普通对象,而非HttpEntity对象的时候,RestTemplate会将请求对象转换为一个HttpEntity对象来处理;其中Object就是request的类型,request内容会呗视作完整的body来处理;而如果request是一个HttpEntity对象,那么就会被当作一个完成的HTTP请求对象来处理,这个request中不仅包含了body的内容,也包含了header的内容。
▪️第二种:postForObject函数。
该方法也跟getForObject的类型类似,它的作用就是简化postForEntity的后续处理。通过直接将请求响应的body内容包装成对象来返回使用,比如下面的例子:
postForObject函数
postForObject函数也实现了三种不同的重载方法:
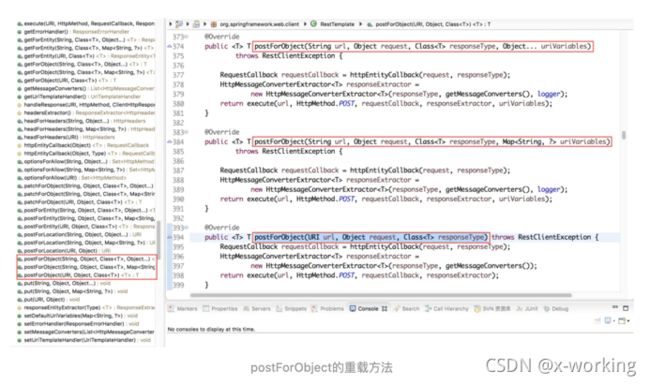
▪️postForObject(String url, Object request, Class responseType, Object... uriVariables)
▪️postForObject(String url, Object request, Class responseType, Map uriVariables)
▪️postForObject(URI url, Object request, Class responseType)
这三个函数除了返回的对象类型不同,函数的传入参数均与postForEntity一致,因此可参考之前postForEntity的说明。
▪️第三种:postForLocation函数。
该方法实现了以POST请求提交资源,并返回新的资源的URI,比如下面的例子:

postForLocation函数也实现了三种不同的重载方法:
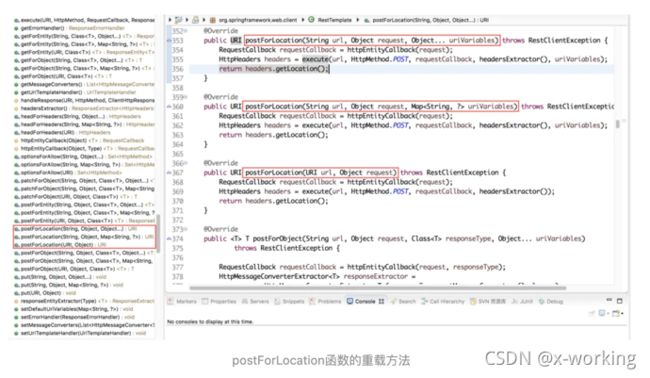
▪️postForLocation(String url, Object request, Object... uriVariables)
▪️postForLocation(String url, Object request, Map uriVariables)
▪️postForLocation(URI url, Object request)
由于postForLocation函数会返回新资源的URI,该URI就相当于指定了返回类型,所以此方法实现的POST请求不需要像postForEntity和postForObject那样指定responseType。其他的参数用法相同。
Ribbon源码分析
相信很多熟悉Spring的读者看到这里一定会产生这样的疑问:RestTemplate不是Spring自己提供的嘛?跟Ribbon的客户端负载均衡又有什么关系呢?在本节中,我们透过现象看本质,探索一下Ribbon是如何通过RestTemplate实现客户端负载均衡的。
首先,回顾一下之前的消费者示例:我们是如何实现客户端负载均衡的?仔细观察一下之前的实现代码,可以发现载消费者的例子中,可能就@LoadBalanced这个注解是之前没有接触过的,并且从命名上来看也与负载均衡相关。我们不妨以此为线索来看看Spring Cloud Ribbon的源码实现。
从@LoadBalanced注解码的注释中,可以知道该注解用来给RestTemplate标记,以使用负载均衡的客户端(LoadBalancerClient)来配置它。
LoadBalancerClient
org.springframework.cloud.client.loadbalancer.LoadBalancerClient
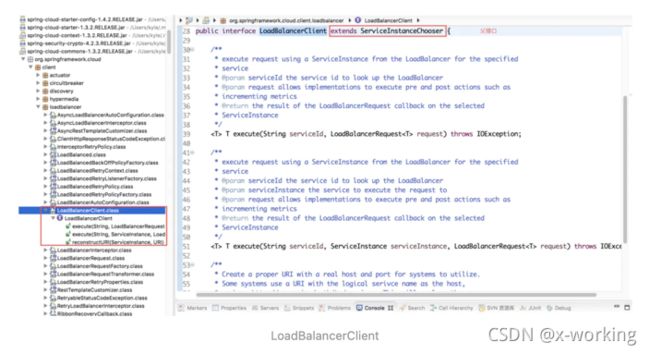
英文释义:
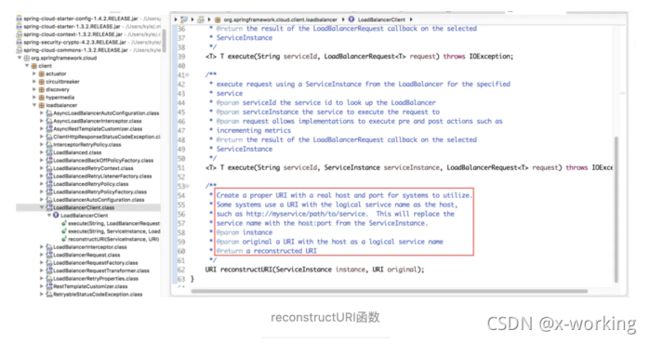
▪️为了给一些系统使用,创建一个带有真实host和port的URI。
▪️一些系统使用带有原服务名代替host的URI,比如http://myservice/path/to/service。
▪️该方法会从服务实例中取出host:port来替换这个服务名。
补充:父接口ServiceInstanceChooser
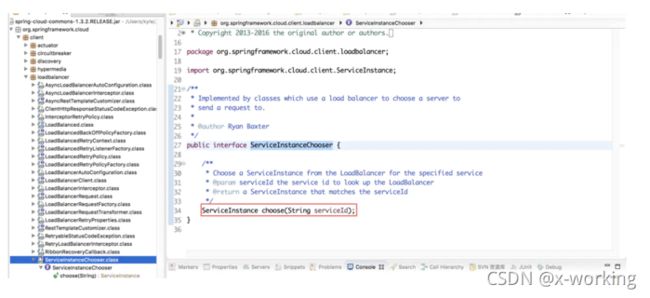
从该接口中,我们可以通过定义的抽象方法来了解到客户端负载均衡器中应具备的几种能力:
▪️ServiceInstance choose(String serviceId):父接口ServiceInstanceChooser的方法,根据传入的服务名serviceId,从负载均衡器中挑选一个对应服务的实例。
▪️ T execute(String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest request):使用从负载均衡器中挑选出的服务实例来执行请求内容。
▪️URI reconstructURI(ServiceInstance instance, URI original):为系统构建一个合适的host:port形式的URI。在分布式系统中,我们使用逻辑上的服务名称作为host来构建URI(替代服务实例的host:port形式)进行请求,比如http://myservice/path/to/service。在该操作的定义中,前者ServiceInstance对象是带有host和port的具体服务实例,而后者URI对象则是使用逻辑服务名定义为host的URI,而返回的URI内容则是通过ServiceInstance的服务实例详情拼接host:port形式的请求地址。
顺着LoadBalancerClient接口的所属包org.springframework.cloud.client.loadbalancer,我们对其内容进行整理,可以得出如下图的关系:
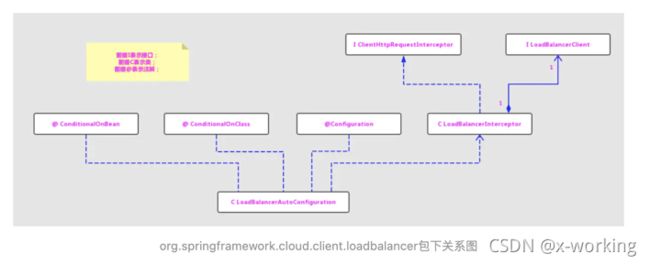
从类的命名上可初步判断LoadBalancerAutoConfiguration为实现客户端负载均衡器的自动化配置类。通过查看源码我们可以验证这一点假设:
org.springframework.cloud.client.loadbalancer.LoadBalancerAutoConfiguration
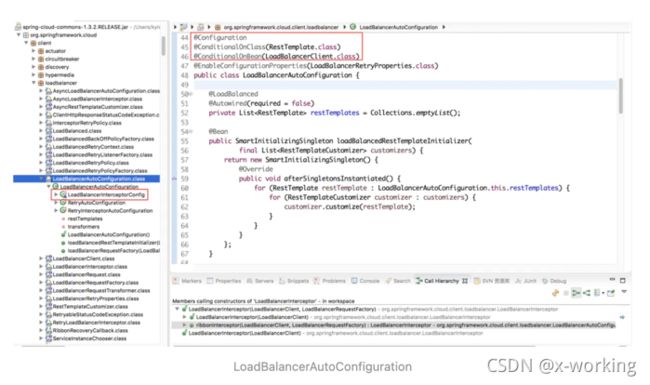
从LoadBalancerAutoConfiguration类上的注解可知,Ribbon实现负载均衡自动化配置需要满足下面两个条件:
▪️@ConditionalOnClass(RestTemplate.class):RestTemplate必须存在于当前工程的环境中。
▪️@ConditionalOnBean(LoadBalancerClient.class):在Spring的Bean工程中必须有LoadBalancerClient的实现bean。
该自动配置类,主要做了下面三件事:
创建了一个LoadBalancerInterceptor的Bean,用于实现对客户端发起请求时进行拦截,以实现客户端负载均衡。
创建了一个RestTemplateCustomizer的Bean,用于给RestTemplate增加LoadbalancerInterceptor
维护了一个被@LoadBalanced注解修饰的RestTemplate对象列表,并在这里进行初始化,通过调用RestTemplateCustomizer的实例来给需要客户端负载均衡的RestTemplate增加LoadBalancerInterceptor拦截器。
接下来,我们看看LoadBalancerInterceptor拦截器是如何将一个普通的RestTemplate
org.springframework.cloud.client.loadbalancer.LoadBalancerInterceptor
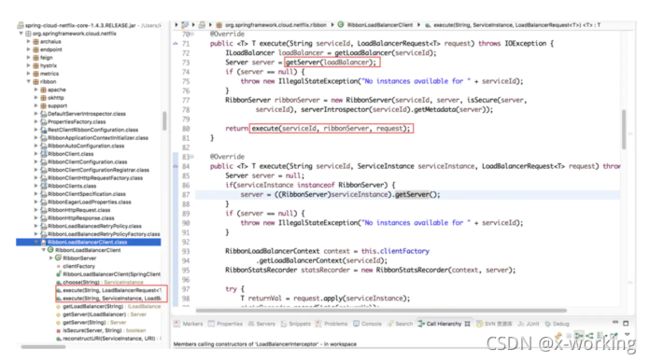
通过源码以及之前的自动化配置类,我们可以看到在拦截器中注入了LoadBalancerInterceptor的实现。当一个被@LoadBalanced注解修饰的RestTemplate对象向外发起HTTP请求时,会被LoadBalancerInterceptor类的intercept函数所拦截。由于我们在使用RestTemplate时候采用了服务名作为host,所以直接从HttpRequest的URI对象中通过getHost()就可以拿到服务名,然后调用execute函数去根据服务名来选择实例并发起实际的请求。
分析到这里,LoadBalancerClient还只是一个抽象的负载均衡器接口,所以我们还需要找到它的具体实现类进一步进行分析,通过查看Ribbon的源码,可以很容易地在org.springframework.cloud.netflix.ribbon包下找到对应的实现类RibbonLoadBalancerClient。
org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient
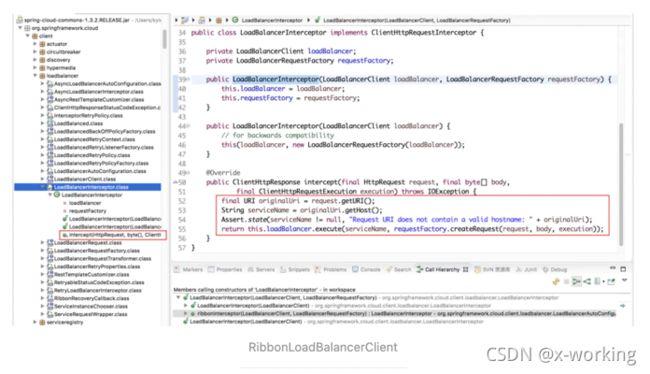
在execute函数的实现中,第一步做的就是通过getServer根据传入的服务名serviceId去获得具体的服务实例:
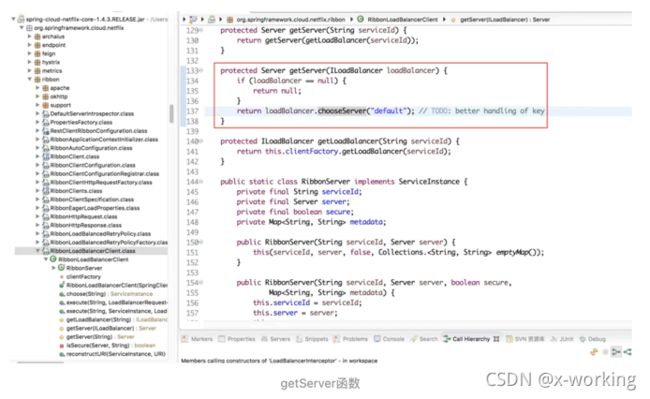
通过getServer函数的实现源码,我们可以看到这里获取具体服务实例的时候并没有使用LoadBalancerClient接口中的choose函数,而是使用了ribbon自身的ILoadBalancer接口中定义的chooseServer函数。
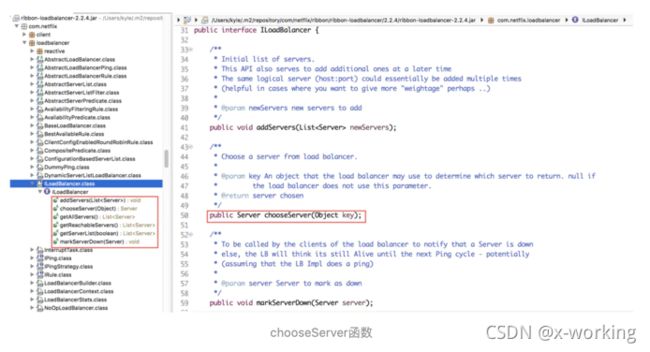
可以看到,在该接口中定义了一个客户端负载均衡器需要的一系列抽象动作:
addServers:向负载均衡器中维护的实例列表增加服务实例。
chooseServer:通过某种策略,从负载均衡器中挑选出一个具体实例。
markServerDwon:用来通知和标识负载均衡器中某个实例已经停止服务,不然负载均衡器在下一次获取服务实例清单前都会认为服务实例均是正常服务的。
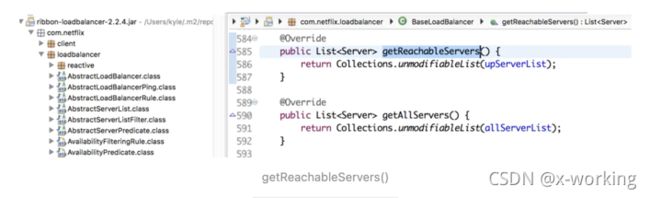
getReachableServers:获取当前正常服务的实例列表。
getAllServers:获取所有已知的服务实例列表,包括正常服务和停止服务的实例。
在该接口定义中涉及到的server对象定义的是一个传统的服务端节点,在该类中存储了服务端节点的一些元数据信息,包括:host,port以及一些部署信息等。
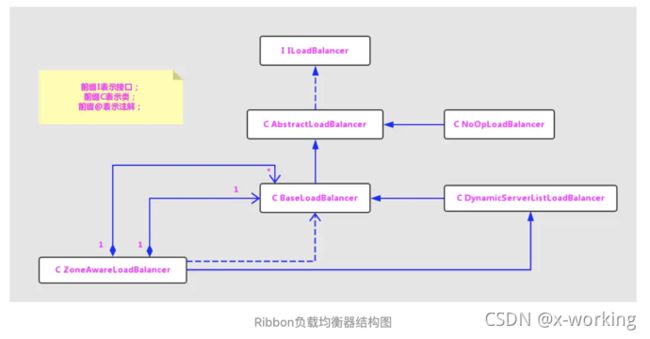
而对于该接口的实现,我们可以整理出如上图所示的结构。我们可以看到BaseloadBalancer类实现了基础的负载均衡,而DynamicServerListLoadBalancer和ZoneAwareLoadBalancer在负载均衡的策略上做了一些功能的扩展。
那么在整合Ribbon的时候Spring Cloud默认采用了那个具体实现呢?
org.springframework.cloud.netflix.ribbon.RibbonClientConfiguration
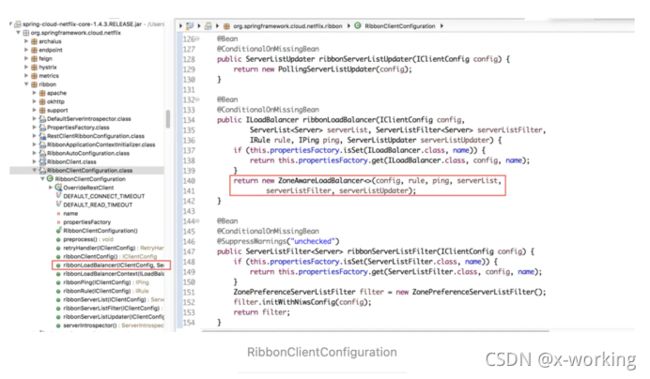
从RibbonClientConfiguration配置类,可以知道在整合时默认采用ZoneAvoidanceRule来实现负载均衡器。
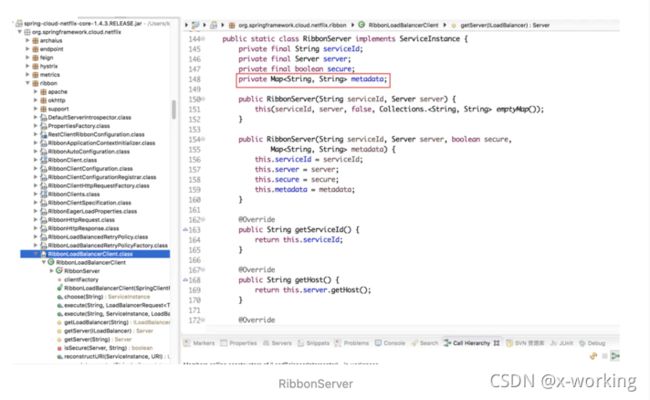
下面,我们再回到RibbonLoadBalancer的execute函数逻辑,在通过ZoneAwareLoaderBalancer的chooseServer函数获取了负载均衡策略分配到的服务实例对象server之后,将其内容包装成RibbonServer对象(该对象除了存储了服务实例的信息之外,还增加了服务名serviceId、是否需要使用HTTPS等其他信息),然后使用该对象再回调LoadBalancerInterceptor请求拦截器中LoadBalancerRequest的apply(final ServiceInstance instance)函数,向一个实际的具体服务实例发起请求,从而实现一开始以服务名为host的URI请求,到实际的host:post形式的具体地址的转换。
apply(ServiceInstance instance)函数中传入的ServiceIntance接口是对服务实例的抽象定义。在该接口中暴露服务治理系统中每个服务实例需要提供的一些基本信息,比如:serviceId、host、port等,具体定义如下:
org.springframework.cloud.client.ServiceInstance;
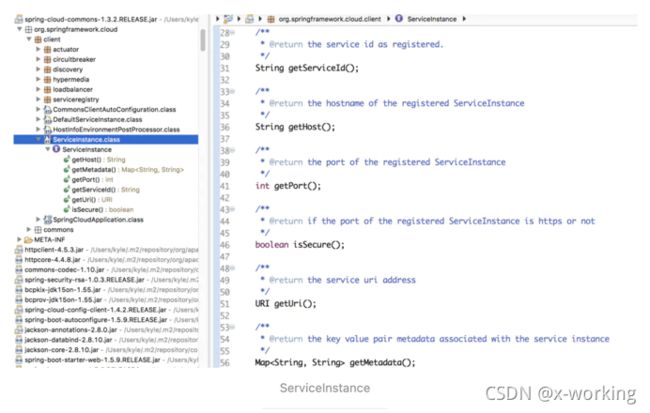
apply(ServiceInstance instance)函数中传入的ServiceIntance接口是对服务实例的抽象定义。在该接口中暴露服务治理系统中每个服务实例需要提供的一些基本信息,比如:serviceId、host、port等,具体定义如下:
org.springframework.cloud.client.ServiceInstance;
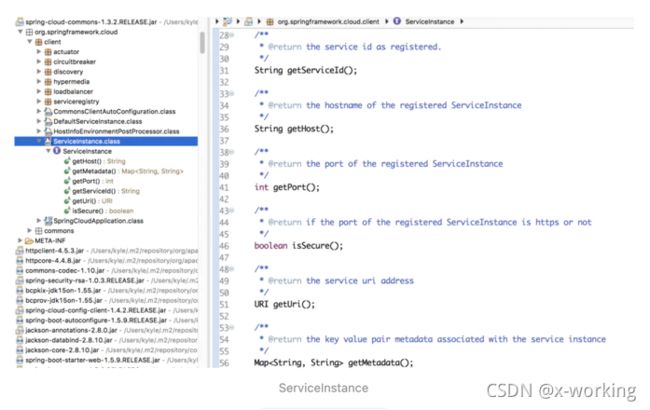
上面提到的具体包装Server服务实例的RibbonServer对象就是ServiceInstance接口的实现,可以看到它除了包含了server对象之外,还存储了服务名、是否使用https标识以及一个map类型的元数据集合。
那么apply(final ServiceInstance instance)函数,在接收到了具体ServiceInstance实例后,是如何通过LoadBalancerClient接口中的reconstructURI操作来组织具体请求地址的呢?
apply(ServiceInstance instance)的两个实现
LoadBalancerClient的实现类
org.springframework.cloud.client.loadbalancer.AsyncLoadBalancerInterceptor
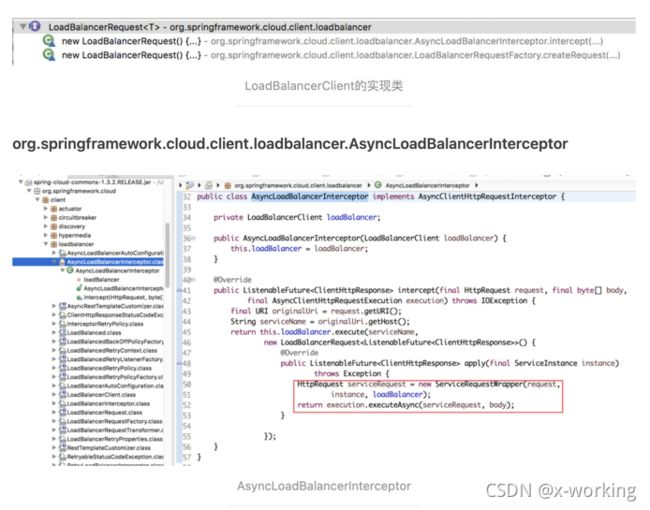
org.springframework.cloud.client.loadbalancer.LoadBalancerRequestFactory
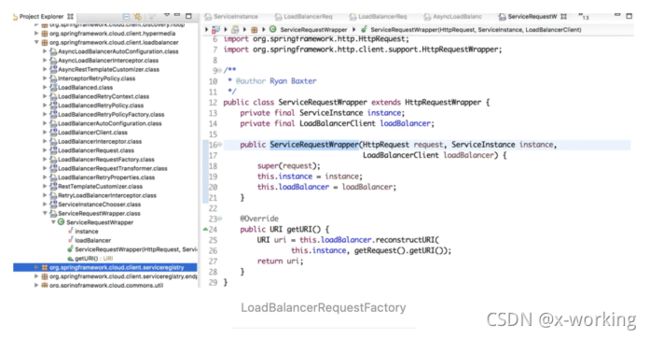
从apply的实现中,我们可以看到它具体执行的时候,还创建了ServiceRequestWrapper对象,该对象继承了HttpRequestWrapper并重写了getURI函数,重写后的getURI会通过调用LoadBalancerClient接口的reconstructURI函数来重新构建一个URI进行访问。
org.springframework.cloud.client.loadbalancer.ServiceRequestWrapper
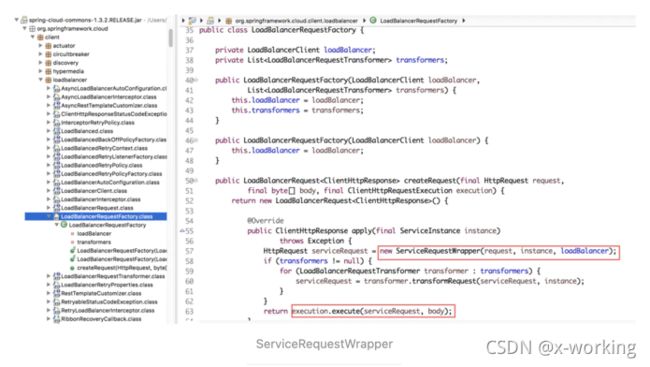
在LoadBalancerInterceptor拦截器中,InterceptingRequestExecution的实例具体执行exection.execute(serviceRequest,body)时,会调用InterceptingClientHttpRequest的内部类InterceptingRequestExecution类的execute函数,具体实现如下:
org.springframework.http.client.InterceptingClientHttpRequest的内部类
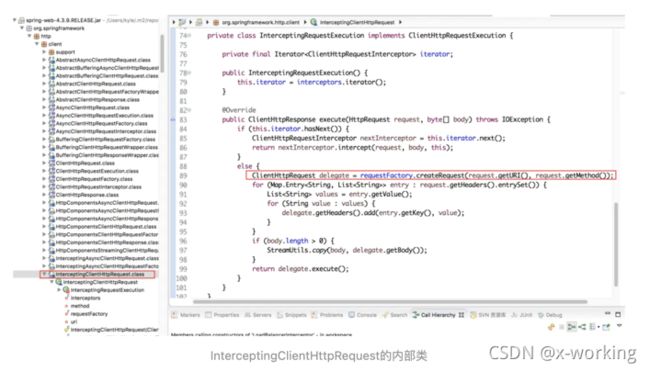
可以看到在创建请求的时候requestFactory.createRequest(request.getURI,request.getMethod),这里的会调用之前介绍的ServiceRequestWrapper对象中重写的getURI函数。
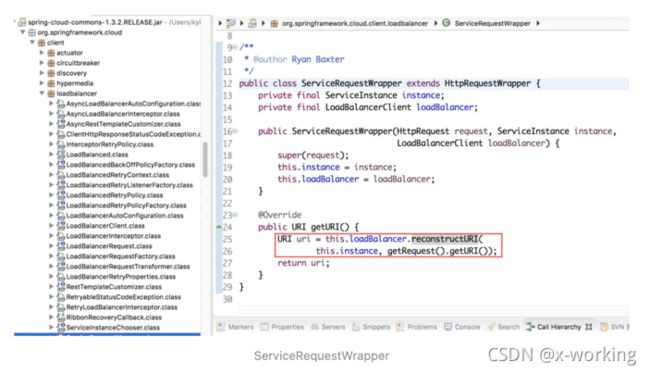
此时,它就会使用RibbonLoadBalancerClient中实现的reconstructURI来组织具体请求的服务实例地址。
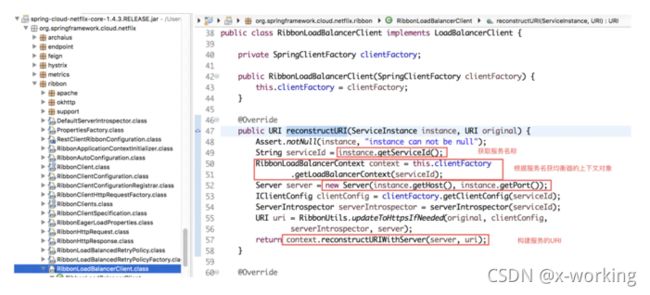
从reconstructURI函数中,我们可以看到,它通过ServiceInstance实例对象的servicId,从SpringClientFactory类的clientFactory对象中获取对应serviceId的负载均衡器的上下文RibbonLoadBalancerContext对象。然后根据ServiceInstance中的信息来构建具体服务实例信息的server对象,并使用RibbonLoadBalancerContext对象的reconstructURIWithServer函数来构建服务实例等URI。
为了帮助理解,简单介绍一下上面提到的SpringClientFactory和RibbonLoadBalancerContext:
▪️SpringClientFactory类是一个用来创建客户端负载均衡器的工厂类,该工厂类会为每一个不同名的Ribbon客户端生成不同的Spring上下文。
▪️RibbonLoadBalancerContext类是LoadBalancerContext的子类,该类用于存储一些被负载均衡使用的上下文内容和API操作(reconstructURIWithServer就是其中之一)
com.netflix.loadbalancer.LoadBalancerContext;
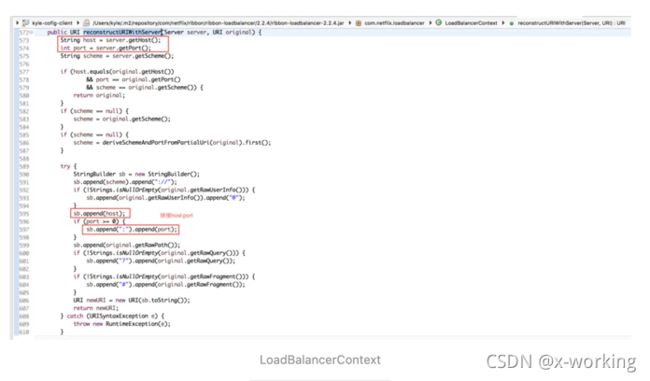
从LoadBalancerContext的reconstructURIWithServer函数中我们可以看到,它同reconstructURI的定义类似。只是reconstructURI的第一个保存具体服务实例的参数使用了Spring Cloud定义的ServiceInstance,而reconstructURIWithServer中使用了Netflix中定义的server,所以在RibbonLoadBalancerClient实现reconstructURI时候,做了一次转换,使用ServiceInstance的host和port信息来构建了一个Server对象来给reconstructURIWithServer使用。从reconstructURIWithServer的实现逻辑中,我们可以看到,它从Server对象中获取host和port信息,然后根据以服务名为host的URI对象original中获取其他请求信息 ,将两者内容进行拼接整合,形成最终要访问的服务实例等具体地址。
另外,从RibbonLoadBalancerClient的execute的函数逻辑中,我们还能看到在回调拦截器中,执行具体的请求后,ribbon还通过RibbonStatsRecorder对象对服务的请求还进行了跟踪记录,有兴趣的读者可以继续研究。
分析到这里,我们已经可以大致理清Spring Cloud Ribbon中实现客户端负载均衡的基本脉络,了解了它是如何通过LoadBalancerInterceptor拦截器对RequestTemplate的请求进行拦截,并利用Spring Cloud的负载均衡器LoadBalancerClient将以服务名为host的URI转换成具体的服务实例地址的过程。同时通过分析LoadBalancerClient的Ribbon实现RibbonLoadBalancerClient,可以知道在使用Ribbon实现负载均衡器的时候,实际使用的还是Ribbon中定义ILoadBalancer接口的实现,自动化配置会采用ZoneAwareLoadBalancer的实例来实现客户端负载均衡。
负载均衡器
通过之前的分析,我们已经对Spring Cloud如何使用有了基本的了解。虽然Spring Cloud中定义了LoadBalancerClient为负载均衡器等接口,并且针对Ribbon实现了RibbonLoadBalancerClient,但是它在具体实现客户端负载均衡时,则是通过Ribbon的ILoadBalancer接口实现。下面我们根据ILoadBalancer接口的实现类逐个看看它都是如何实现客户端负载均衡的。
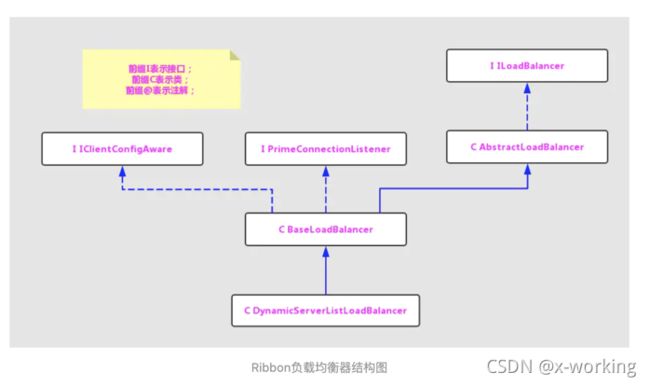
▪️AbstractLoadBalancer
com.netflix.loadbalancer.AbstractLoadBalancer
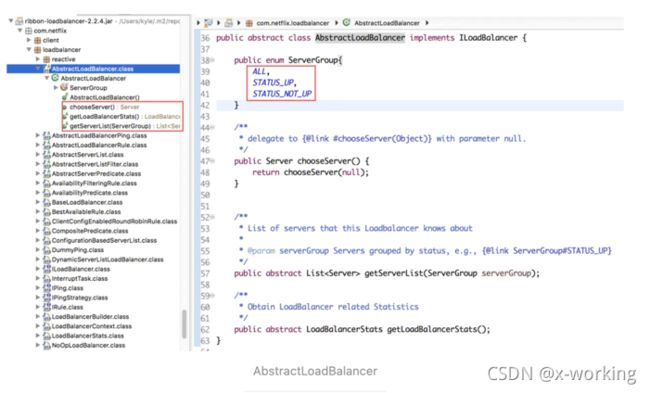
AbstractLoadBalancer是ILoadBalancer接口的抽象实现。在该抽象类中定义了一个关于测试服务实例的分组枚举类ServerGroup,它包含了三种不同类型:
ALL:所有服务实例
STATUS_UP:正常服务的实例
STATUS_NOT_UP:停止服务的实例
另外,还实现了一个chooseServer()函数,该函数通过调用接口中的chooseServer(Object key)实现,其中参数key为null,表示在选择具体服务实例时忽略key的条件判断。
最后还定义了两个抽象函数:
getServerList(ServerGroup serverGroup):定义了根据分组类型来获取不同的服务实例列表
getLoadBalancerStats():定义了获取LoadBalancerStats对象的方法,loadBalancerStats对象被用来存储负载均衡器中各个服务实例当前的属性和统计信息,这些信息非常有用,我们可以利用这些信息来观察负载均衡的运行情况,同时这些信息也是用来制定负载均衡策略的重要依据。
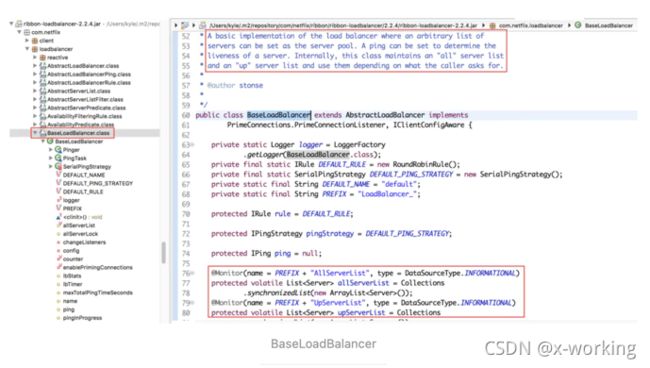
▪️BaseLoadBalancer
com.netflix.loadbalancer.BaseLoadBalancer
英文释义:
▪️一个负载均衡器的基础实现,该负载均衡器的作用是维护一张可以将服务设置到服务池的任意表。
一个ping能觉得一个服务的活性。本质上,这个类保存一个“all”服务列表和一个“up”服务列表,还有支持消费者使用它们。
BaseLoadBalancer类是Ribbon负载均衡器的基础实现类,在该类中定义很多关于均衡负载相关的基础内容:
定义并维护了两个存储服务实例server对象的列表。一个用于存储所有服务实例的清单,一个用于存储正常服务的实例清单。
定义了之前我们提到的用来存储负载均衡器各服务实例属性和统计信息的LoadBalancerStats对象。
定义了检查服务实例是否正常服务的ping对象,在BaseLoadBalancer中默认为null,需要在构造时注入它的具体实现。
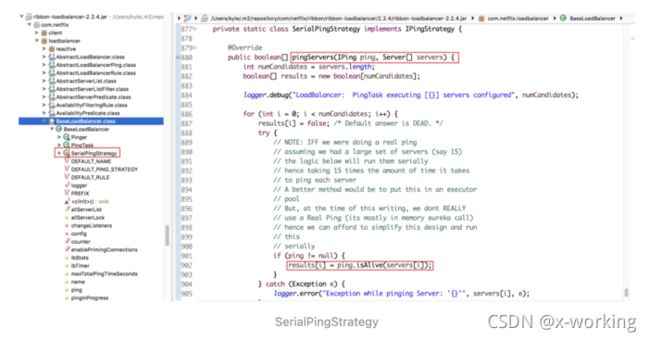
定义了检查服务实例操作的执行策略对象IPingStrategy,在BaseLoadBalancer中默认使用了该类中定义的静态内部类SerialPingStrategy实现。根据源码,我们可以看到该策略采用线性遍历ping服务实例等方式实现检查。该策略在当IPing当实现速度不理想,或是Server列表过大时,可能会影响系统性能,这时候需要通过实现IPingStrategy接口并重写pingServers(IPing ping, Server[] servers)函数去扩展ping的执行策略。
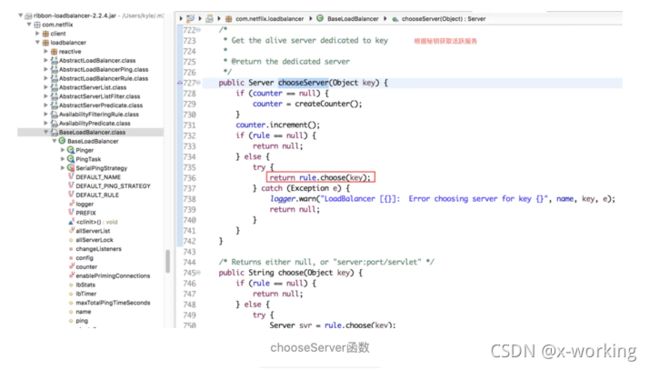
定义了负载均衡的处理规则IRule对象,从BaseLoadBalancer中chooseServer(Object key)的实现源码,我们可以知道负载均衡器实际进行服务实例选择任务是委托给了IRule实现中的choose函数中实现而在这里,默认初始化了RoundRobinRule为IRule的实现对象。RoundRobinRule实现了最基本且常用的线性负载均衡规则。
启动ping任务:在BaseLoadBalancer的默认构造函数中,会直接启动一个用于定时检查server是否健康的任务。该任务默认的执行间隔为:10秒。
实现了ILoadBalancer接口定义的负载均衡器应具备的一系列基本操作:
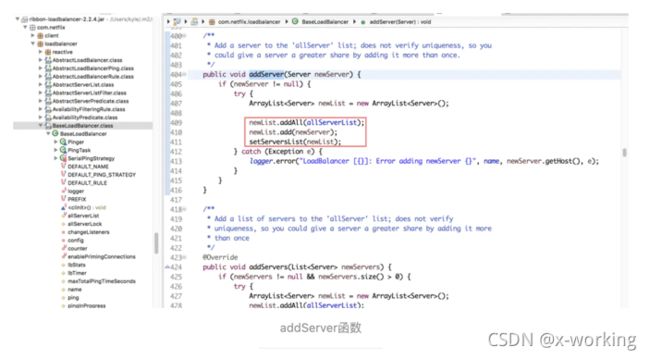
addServer(List newServer):向负载均衡器中增加新的服务实例列表,该实现将原本已经维护着的所有服务实例清单allServerList和新传入的服务实例清单newServers都加入到newList进行处理,在BaseLoadBalancer中实现的时候会使用新的列表覆盖旧的列表。而之后介绍的几个扩展实现类对于服务实例清单更新的优化都是通过对setServersList函数的重写来实现的。
chooseServer(Object key):挑选一个具体的服务实例,在上面介绍IRule的时候,已经做了说明。
markServerDown(Server server):标记某个服务实例暂停服务。
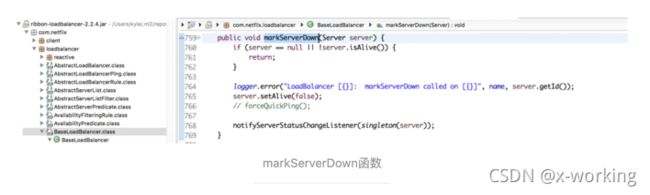
getReachableServers():获取可用的(可达的)实例列表。由于BaseLoadBalancer中单独维护了一个正常服务的实例清单,所以直接返回即可。
getAllServer():获取所有的服务实例列表。由于BaseLoadBalancer中单独维护了一个所有服务的实例清单,所以也直接返回它即可。
DynamicServerListLoadBalancer
com.netflix.loadbalancer.DynamicServerListLoadBalancer
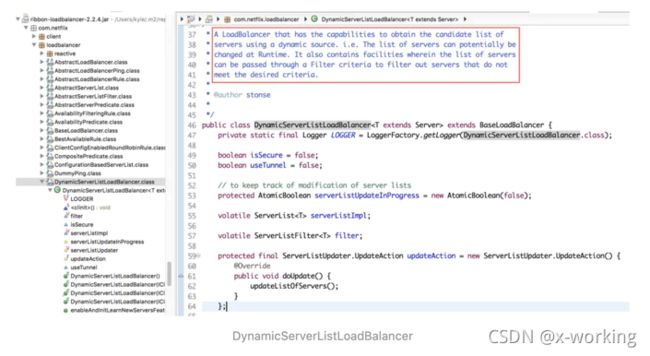
英文释义:
▪️这是一个负载均衡器,它有从动态源获取候选服务列表的能力。
▪️这个服务列表能够在运行期间动态的改变。
▪️它也包含一些场所,列表中的服务在这些场所中被筛选出符合标准的服务。
DynamicServerListLoadBalancer类继承于BaseLoadBalancer类,它是对基础负载均衡器的扩展。在该负载均衡器中,实现了服务实例清单的在运行期的动态更新能力;同时,它还具备了对服务实例清单的过滤功能,也就是说我们可以通过过滤器来选择性的获取一批服务实例清单。
▪️ServerList
从DynamicServerListLoadBalancer的成员定义中,我们马上可以发现新增了一个关于服务列表的操作对象:ServerList serverListImpl。其中范型T从类名中对于T的限定DynamicServerListLoadBalancer可以获知它是一个server的子类,即代表了一个具体的服务实例的扩展类。而Server接口定义如下所示:
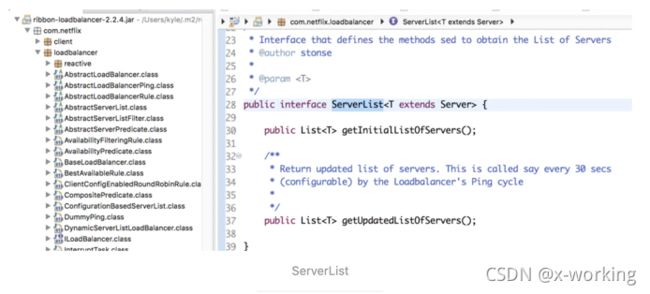
ServerList
它定义了两个抽象方法:getInitialListOfServers用于获取初始化的服务实例清单,而getUpdatedListOfServers用于获取更新的服务实例清单。那么该接口的实现有哪些呢?通过搜索源码,我们可以整出如下图的结构:
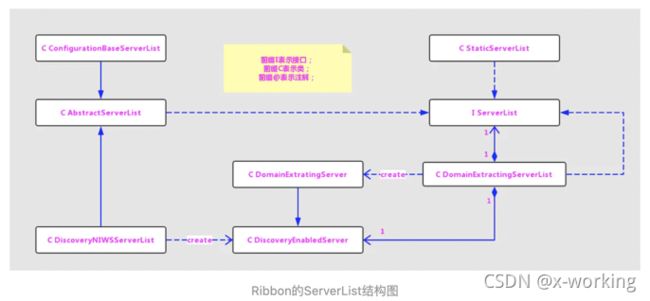
从图中我们可以看到有很多个ServerList的实现类,那么在DynamicServerListLoadBalancer中的ServerList默认配置到底使用了哪个具体实现呢?既然在该负载均衡器中需要实现服务实例的动态更新,那么势必需要ribbon具备访问eureka来获取服务实例的能力,所以我们从Spring Cloud整合ribbon与eureka的EurekaRibbonClientConfiguration,在该类中可以找到下面创建ServerList实例的内容。
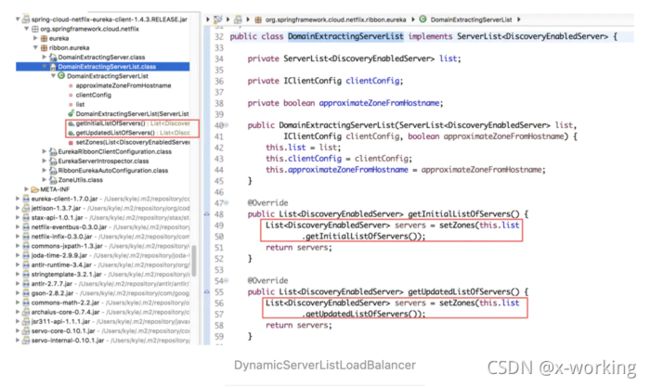
那么DiscoveryEnabledNIWSServerList是如何实现这两个服务实例的获取的呢?从源码中可以看到这两个方法都是通过该类中的私有函数obtainServersViaDiscovery来通过服务发现机制来实现服务实例的获取。
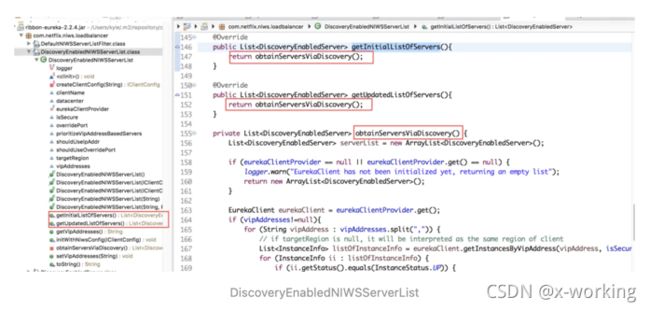
而obtainServersViaDiscovery的实现逻辑如下,主要依靠EurekaClient从服务注册中心中获取到具体的服务实例InstanceInfo列表(EurekaClient的具体实现,这里传入的vipAddress可以理解为逻辑上的服务名,比如“USER-SERVICE”)。接着,对这些服务实例进行遍历,将状态为“UP”(正常服务)的实例转换成DiscoveryEnabledServer对象,最后将这些实例组织成列表返回。
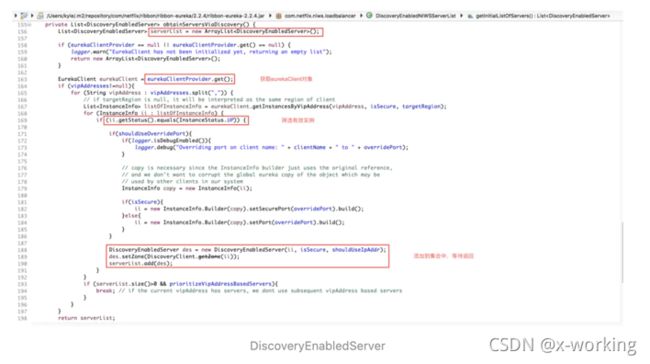
在DiscoveryEnabledNIWSServerList中通过EurekaClient从服务注册中心获取到最新的服务实例清单后,返回的List到了DomainExtractingServerList类中,将继续通过setZones函数进行处理。而这里的处理具体内容如下所示,主要完成将DiscoveryEnabledNIWSServerList返回的List列表中的元素,转换成内部定义的DiscoveryEnabledServer的子类对象DomainExtractingServer,在该对象的构造函数中将为服务实例对象设置一些必要的属性,比如id、zone、isAliveFlag、readyToServe等信息。
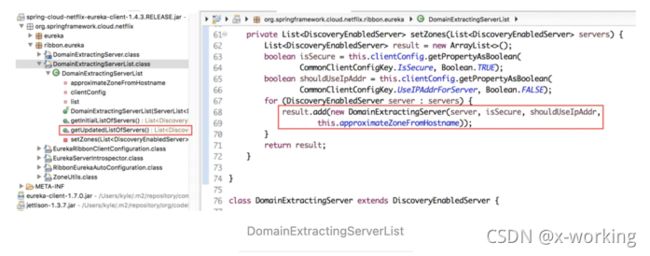
▪️ServerListUpdater
通过上面的分析我们已经知道了Ribbon与Eureka整合后,如何实现从Eureka Server中获取实例清单。那么它又是如何触发向Eureka Server去获取服务实例清单以及如何在获取到服务实例清单后更新本地的服务实例清单的呢?继续来看DynamicServerListLoadBalancer中的实现内容,我们可以很容易地找到下面定义的关于ServerListUpdater的内容:
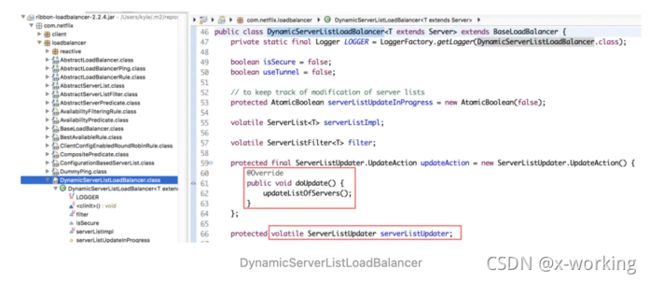
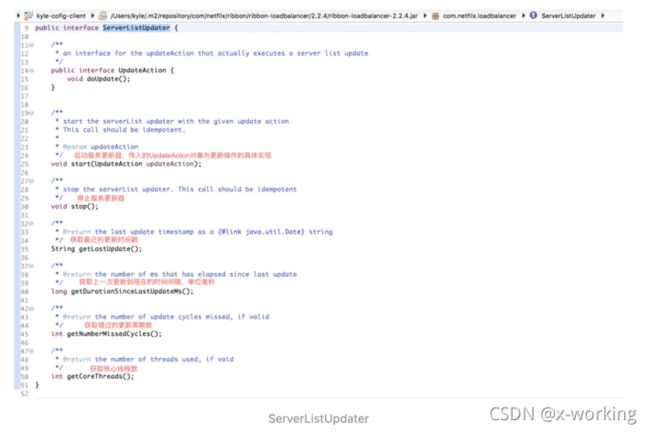
根据该接口的命名,我们基本就能猜到,这个对象实现的是对ServerList的更新,所以可以称它为“服务更新器”。从下面的源码中可以看到,在ServerListUpdater内部还定义了一个UpdateAction接口,上面定义的updateAction对象就是以匿名内部类的方式创建了一个它的具体实现,其中doUpdate实现的内容就是对ServerList的具体更新操作。除此之外,“服务更新器”中还定义了一系列控制它和获取它的信息的操作。
而ServerListUpdater的实现类不多,具体如下所示。
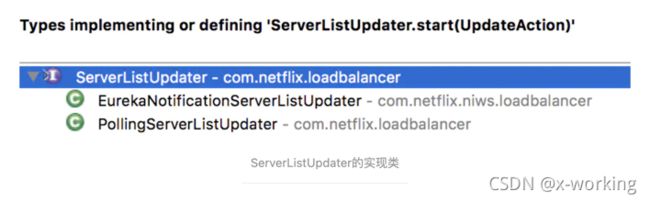
根据两个类的注释,我们可以很容易地知道它们的作用。
PollingServerListUpdater:动态服务列表更新的默认策略,也就是说,DynamicServerListLoadBalancer负载均衡器中的默认实现就是它,它通过定时任务的方式进行服务列表的更新。
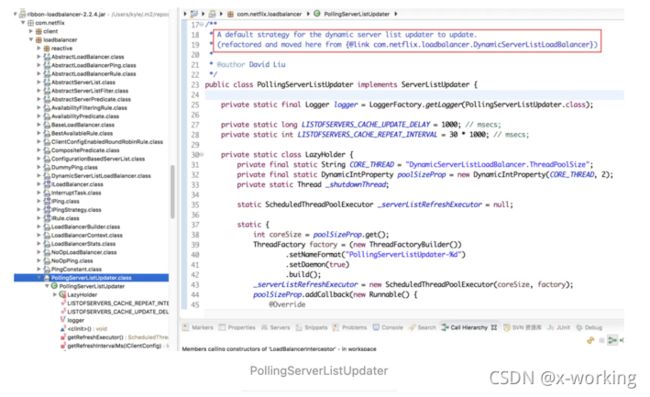
PollingServerListUpdater
EurekaNotificationServerListUpdater:该更新器也可服务于DynamicServerListLoadBalancer负载均衡器,但是它的触发机制与PollingServerListUpdater不同,它需要利用Eureka的事件监听器驱动服务列表的更新操作。
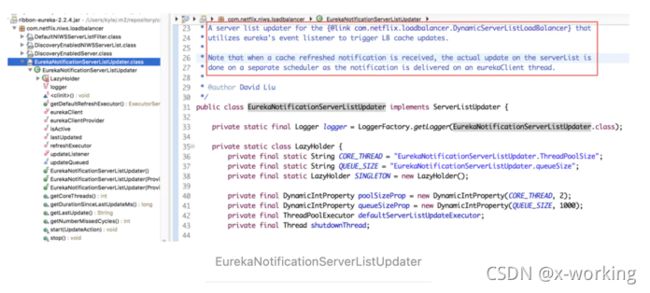
EurekaNotificationServerListUpdater
下面我们来详细看看它默认实现的PollingServerListUpdater。先从用于启动“服务更新器”的start函数源码看起,具体如下。我们可以看到start函数的实现内容验证了之前提到的:以定时任务的方式进行服务列表的更新。它先创建了一个Runnable的线程实现,在该实现中调用了上面提到的具体更新服务实例列表的方法updateAction.doUpdate(),最后再为这个Runnable线程实现启动了一个定时任务执行。
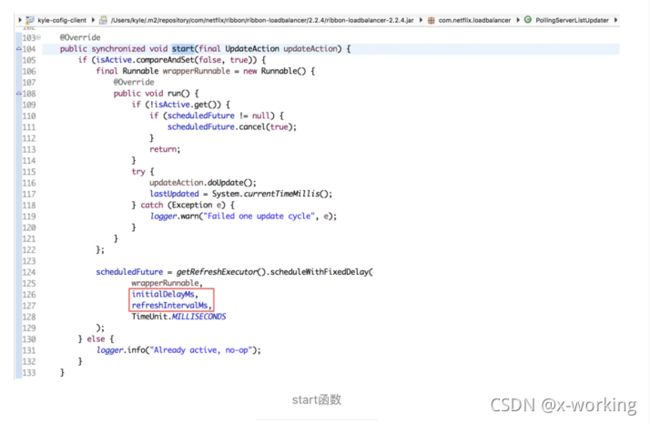
继续看PollingServerListUpdater的其他内容,我们可以找到用于启动定时任务的两个参数initialDelayMs和refreshIntervalMs的默认定义分别为1000和30*1000,单位为毫秒。也就是说,更新服务实例在初始化之后延迟1秒后开始执行,并以30秒为周期重复执行。除了这些内容之外,还能看到它还会记录最后更新时间、是否存活等信息,同时也实现了ServerListUpdater中定义的一些其他操作内容,这些操作相对比较简单,这里不再具体说明,有兴趣的读者可以自己查看源码了解实现原理。
▪️ServerListFilter
在了解了更新服务实例等定时任务是如何启动的之后,我们回到updateAction,doUpdate()调用的具体实现位置,在DynamicServerListLoadBalancer中,它的实际委托给了updateListOfServers函数,具体实现如下:
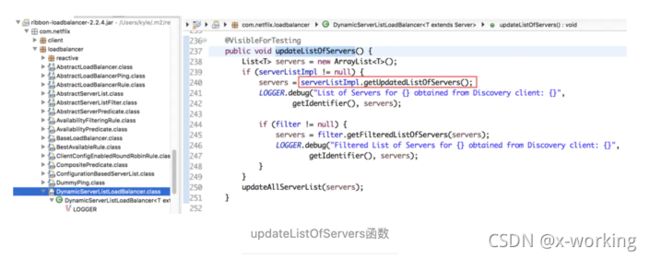
可以看到,这里终于用到了之前提到的ServerList的getUpdateListOfServers(),通过之前的介绍已经知道了这一步实现了从Eureka Server中获取服务可用实例等列表。在获得了服务实例列表之后,这里又将引入一个新的对象filter,追溯该对象的定义,我们可以找到它是ServerListFilter定义的。
ServerListFilter接口非常简单,该接口中定义了一个方法List getFilteredListOfServers(List servers),主要用于实现对服务实例列表的过滤,通过传入的服务实例清单,根据一些规则返回过滤后的服务实例清单。该接口的实现如下图所示。
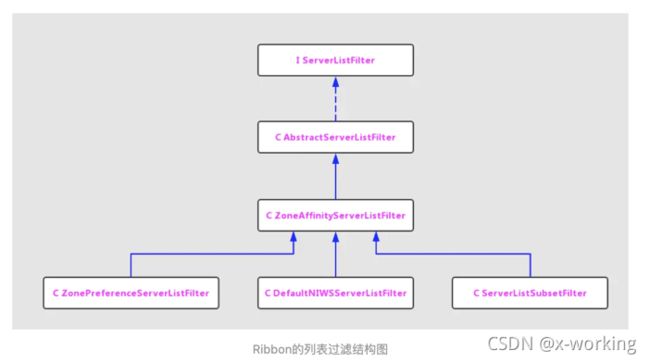
其中,除了ZonePreperenceServerListFilter的实现是Spring Cloud Ribbon中对Netflix Ribbon的扩展实现外,其他均是Netflix Ribbon中对原生实现类。下面,我们可以分别看看这些过滤器都有说明特点。
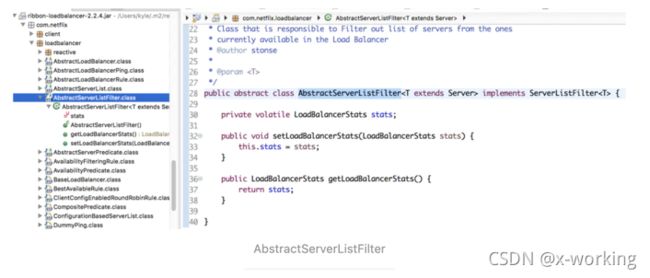
AbstractServerListFilter:这是一个抽象过滤器,在这里定义了过滤时需要的一个重要依据对象LoadBalancerStats,我们在之前介绍过,该对象存储了关于负载均衡器的一些属性和统计信息等。
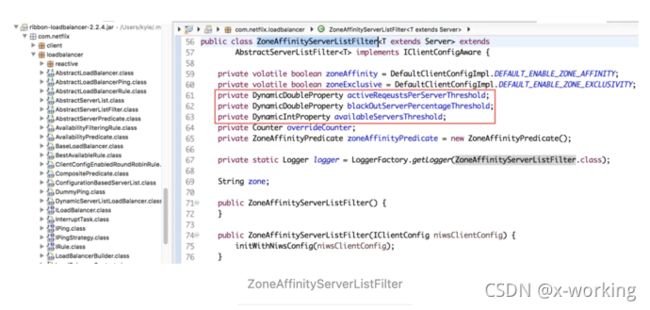
ZoneAffinityServerListFilter:该过滤器基于“区域感知(Zone Affinity)”的方式实现服务实例等过滤,也就是说,它会根据提供服务的实例所处的区域(Zone)与消费者的所处区域(Zone)进行比较,过滤掉那些不是同处一个区域的实例。
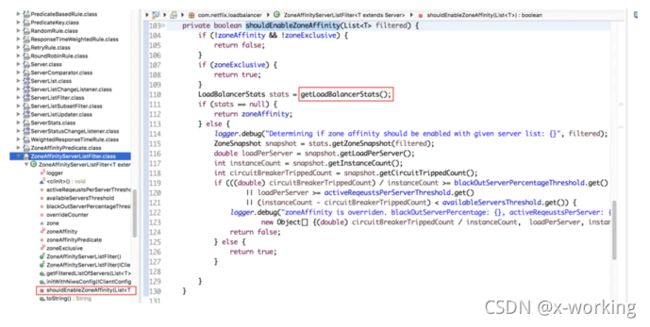
从上面的源码中我们可以看到,对于服务实例列表的过滤是通过Iterables.filter(servers,this.zoneAffinityPredicate.getServerOnlyPredicate())来实现的,其中判断依据由ZoneAffinityPredicate实现服务实例与消费者的Zone比较。而在过滤之后,这里并不会马上返回过滤的结果,而是通过shouldEnableZoneAffinity函数来判断是否要启用“区域感知”的功能。从下面shouldEnableZoneAffinity的实现中,我们可以看到,它使用了LoadBalancerStats的getZoneSnapshot方法来获取这些过滤后的同区域实例等基础指标(包含实例数量、断路器断开数、活动请求数、实例平均负载等),根据一系列的算法求出下面的几个评价价值并与设置的阀值进行对比(下面的为默认值),若有一个条件符合,就不启用“区域感知”过滤掉服务实例清单。这一算法实现为集群出现区域故障时,依然可以依靠其他区域的实例进行正常服务提供了完善的高可用保障。同时,通过这里的介绍,我们也可以关联着来理解之前介绍Eureka的时候提到的对于区域分配设计来保证区域故障的高可用问题。
blackOutServerPercentage:故障实例百分比(断路器断开数/实例数量)>=0.8。
activeRequestsPerServer:实例平均负载>=0.6。
availableServers:可用实例数(实例数量-断路器断开数)<2。
DefaultNIWSServerListFilter:该过滤器也继承自ZoneAffinityServerListFilter,是默认的NIWS(Netflix Internal Web Service)过滤器。
ServerListSubsetFilter:该过滤器也继承自ZoneAffinityServerListFilter,它非常适用于拥有大规模服务器集群(上百或更多)的系统。因为它可以产生一个“区域感知”结果的子集列表,同时它还能够通过比较服务实例等通信失败数量和并发连接数来判定该服务是否健康来选择性地从服务实例列表中剔除那些相对不够健康的实例。
ZonePerferenceServerListFilter:Spring Cloud整合时新增的过滤器。若使用Spring Cloud整合Eureka和Ribbon时会默认使用该过滤器。它实现了通过配置或者Eureka实例元数据的所属区域(Zone)来过滤出同区域的服务实例。如下面的源码所示,它的实现非常简单,首先通过父类ZoneAffinityServerListFilter的过滤器来获得“区域感知”的服务实例列表,然后遍历这个结果,取出根据消费者配置预设的区域Zone来进行过滤,如果过滤掉结果是空就直接返回父类获取的结果,如果不为空就返回通过消费者配置的Zone过滤后的结果。
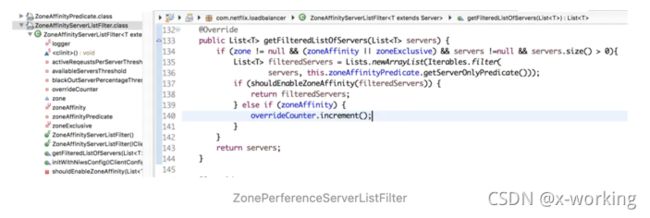
ZoneAwareLoadBalancer
ZoneAwareLoadBalancer负载均衡器是对DynamicServerListLoadBalancer的扩展。在DynamicServerListLoadBalancer中,我们可以看到它并没有重写选择具体服务实例等chooseServer函数,所以它依然会采用在BaseLoadBalancer中实现的算法。使用RoudRobinRule规则,以线性轮询的方式选择调用的服务实例,该算法实现简单并没有区域(Zone)的概念,所以它会把所有实例视为一个Zone下的节点来看待,这样就会周期性地产生跨区域(Zone)访问的情况,由于跨区域会产生更高的延迟,这些实例主要以防止区域性故障实现高可用为目的而不能作为常规访问的实例,所以在多区域部署的情况下会有一定的性能问题,而该负载均衡器则可以避免这样的问题。那么它是如何实现的呢?
首先,在ZoneAwareLoadBalancer中,我们可以发现,它并没有重写setServerList,说明实现服务实例清单的更新主逻辑没有修改。但是我们可以发现你重写了这个函数setServerListForZones(Map> zoneServersMap)。看到这里可能会有一些陌生,因为它并不是借口中定义的必备函数,所以我们不妨去父类DynamicServerListLoadBalancer中寻找一下该函数,我们可以找到下面的定义:
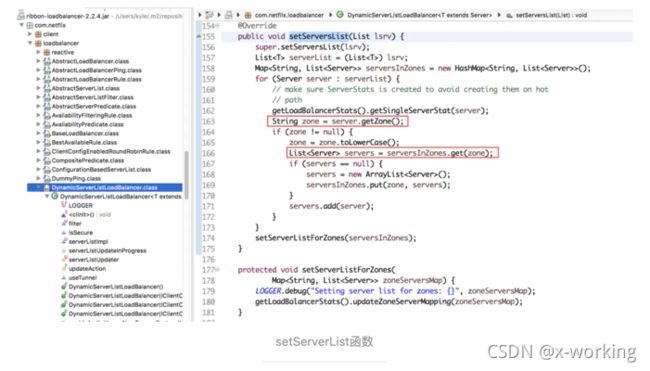
setServerListForZones函数的调用位于更新服务实例清单函数setServersList的最后,同时从其实现的内容来看,它在父类DynamicServerListLoadBalancer中的作用是根据按区域Zone分组的实例列表,为负载均衡器中的LoadBalancerStats对象创建ZoneStats并放入Map zoneStatsMap集合中,每一个区域Zone对应一个ZoneStats,它用于存储每个Zone的一些状态和统计信息。
在ZoneAwareLoadBalancer中对setServerListForZones的重写如下:
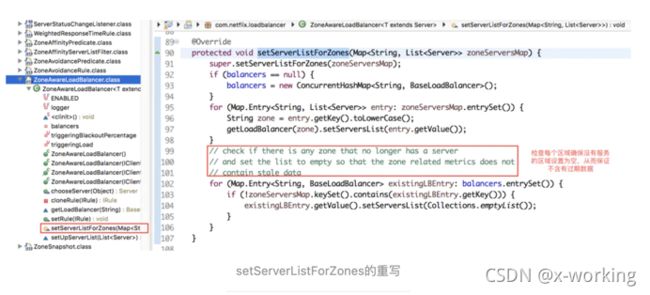
可以看到,在该实现中创建了一个ConcurrentHashMap()类型的balancers对象,它将用来存储每个Zone区域对应的负载均衡器。而具体的负载均衡器的创建则是通过在下面的第一个循环中调用getLoadBalancer函数来完成,同时在创建负载均衡器的时候会创建它的规则(如果当前实现中没有IRule的实例,就创建一个AvailabilityFilteringRule规则;如果一件有具体实例,就克隆一个)。在创建完负载均衡器后又马上调用setServersList函数为其设置对应Zone区域的实例清单。而第二个循环则是对Zone区域中实例清单的检查,看看是否有Zone区域下已经没有实例了,是的话就将balancers中对应Zone区域的实例列表清空,该操作的作用是为了后续选择节点时间,防止过期的Zone区域统计信息干扰具体实例等选择算法。
在了解了该负载均衡器是如何扩展服务实例清单的实现后,我们具体看看它是如何挑选服务实例,来实现对区域的识别的:
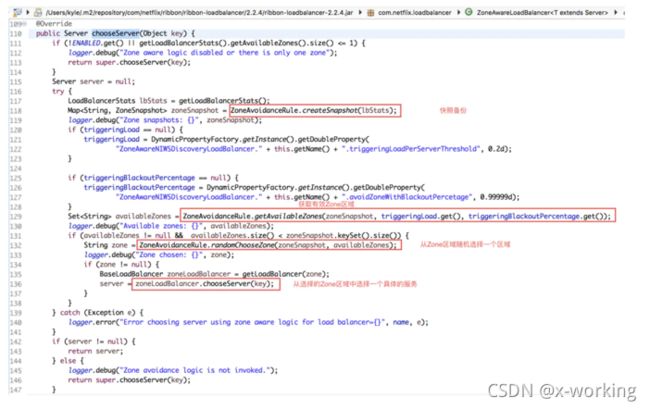
从源码中我们可以看到,只有负载均衡器中维护的实例所属的Zone区域个数大于1的时候才会执行这里的选择策略,否则还是将使用父类的实现。当Zone区域的个数大于1的时候,它的实现步骤如下所示。
▪️调用ZoneAvoidanceRule中静态方法createSnapshot(lbStats),为当前负载均衡器中所有的Zone区域分别创建快照,保存在Map zoneSnapshot中,这些快照中的数据将用于后续的算法。
▪️调用ZoneAvoidanceRule中的静态方法getAvailableZones(zoneSnapshot, triggeringLoad.get(), triggeringBlackoutPercentage.get()),来获取可用的Zone区域集合,在该函数中会通过Zone区域快照中的统计数据来实现可用区的挑选。
首先它会剔除符合这些规则的Zone区域:所属实例数位零的Zone区域;Zone区域内实例等平均负载小于零,或者实例故障率(断路器断开次数/实例数)大于等于阀值(默认为0.99999)。
然后根据Zone区域等实例平均负载计算出最差的Zone区域,这里的最差指的是实例平均负载最高的Zone区域。
如果在上面的过程中没有符合剔除要求的区域,同时实例最大平均负载小于阀值(默认为20%),就直接返回所有Zone区域为可用区域。否则,从最坏Zone区域集合中随机选择一个,将它从可用Zone区域集合中剔除。
▪️当获得的可用Zone区域集合不为空,并且个数小于Zone区域总数,就随机选择一个Zone区域。
▪️在确定了某个Zone区域后,则获取了对应Zone区域的服务均衡器,并调用chooseServer来选择具体的服务实例,而在chooseServer中将使用IRule接口的choose函数来选择具体的服务实例。在这里,IRule接口的实现会使用ZoneAvoidanceRule来挑选出具体的服务实例。
关于ZoneAvoidanceRule的策略以及其他一些还未提到的负载均衡策略,我们将在下一节更近详细的解读。
负载均衡策略
通过上面的源码解读,我们已经对Ribbon实现的负载均衡器以及其中包含的服务实例过滤器、服务实例信息的存储对象、区域的信息快照等都有了深入的认识和理解,但是对于负载均衡器中的服务实例选择策略只是讲解了几个默认实现的内容,而对于IRule的其他实现还没有详细解读,下面我们来看看在Ribbon中都提供了哪些负载均衡的策略实现。
如下图所示,可以看到在Ribbon中实现了非常多的选择策略,其中也包含了我们在前面内容中提到过的RoudRobinRule和ZoneAvoidanceRule。下面我们来详细可读一下IRule接口的各个实现。
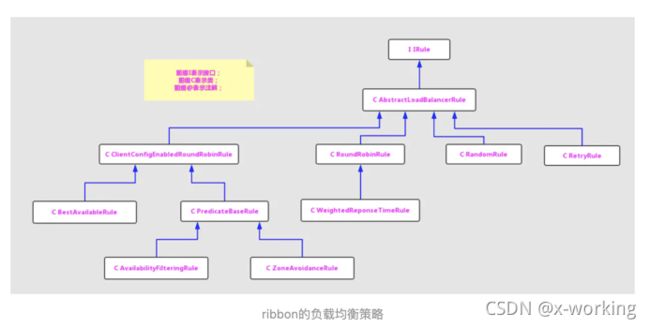
▪️AbstractLoadBalancerRule
负载均衡策略的抽象类,在该抽象类中定义了负载均衡器ILoadBalancer对象,该对象能够在具体实现选择服务策略时,获取到一些负载均衡器中维护的信息来作为分配依据,并以此设计一些算法来实现针对特定场景的高效策略。
▪️RandomRule
该策略实现了从服务实例清单中随机选择一个服务实例的功能。具体的选择逻辑在一个while(server==null)循环之内,而根据选择逻辑的实现,正常情况下每次选择都应该选出一个服务实例,如果出现死循环获取不到服务实例,如果出现死循环获取不到服务实例时,则很有可能存在并发的Bug。
▪️RoundRobinRule
该策略实现了按照线性轮询的方式的方式一次选择每个服务实例的功能。它的具体实现如下,其详细结构与RandomRule非常类似。除了循环条件不同外,就是从可用列表中获取所谓的逻辑不通。从循环条件中,我们可以看到增加了一个count计数变量,该变量会在每次循环之后累加,也就是说,如果一直选择不到server超过10次,那么就会结束尝试,并打印一个警告信息No available alive servers after 10tries from load balancer : ... 。
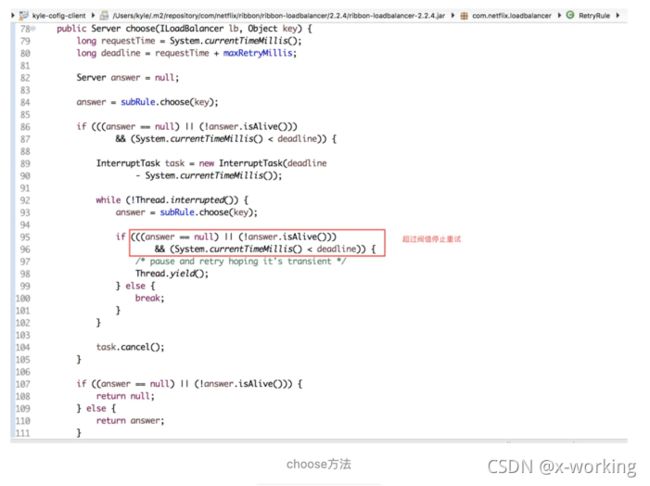
▪️RetryRule
该策略实现了一个具备重试机制的实例选择功能。从下面的实现中我们可以看到,在其内部还定义了一个IRule对象,默认使用了RoudRobinRule实例。而在choose方法中则实现了对内部定义的策略进行反复尝试的策略,若期间能够选择到具体的服务实例就反悔,若选择不到就根据设置结束时间为阀值(maxRetryMillis参数定义的值+choose方法开始执行的时间戳),当超过该阀值就返回null。
▪️WeightedResponseTimeRule
该策略是对RoundRobinRule的扩展,增加了根据实例等运行情况来计算权重,并根据权重来挑选实例,以达到更优的分配效果,它的实现主要有三个核心内容。
定时任务
权重计算
实例选择
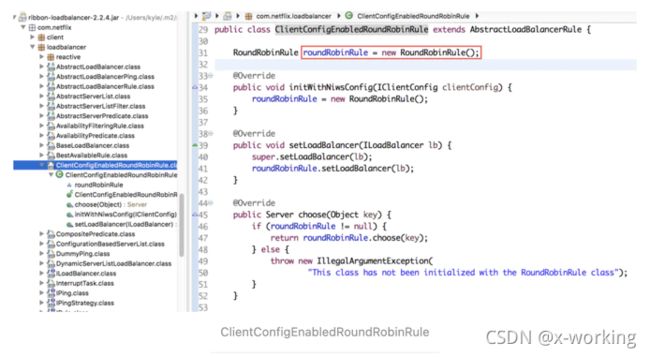
▪️ClientConfigEnabledRoundRobinRule
该策略较为特殊,我们一般不直接使用它,因为它本身并没有实现什么特殊的处理逻辑,正如下面的源码所示,在它的内部定义了一个RoundRobinRule策略,而choose函数的实现也正是使用了RoundRobinRule的线性轮询机制,所以它实现的功能实际上与RoundRobinRule相同,那么定义它有什么特殊的用处呢?
虽然我们不会直接使用该策略,但是通过继承该策略,默认的choose就实现了线性轮询机制,在子类中做一些高级策略时通常有可能会存在一些无法实施的情况,那么久可以用父类的实现作为备选。在后面中我们将继续介绍的高级策略均是基于ClientConfigEnabledRoundRobinRule的扩展。
▪️BestAvailableRule
该策略继承自ClientConfigEnabledRoundRobinRule,在实现中它注入了负载均衡器的统计对象LoadBalancerStats,同时在具体的choose算法中利用LoadBalancerStats保存的实例统计信息来选择满足要求的实例。从如下源码中我们可以看到,它通过遍历负载均衡器中维护的所有服务实例,会过滤掉故障的实例,并找出并发请求数最小的一个,所以该策略的特性是可选出最空闲的实例。
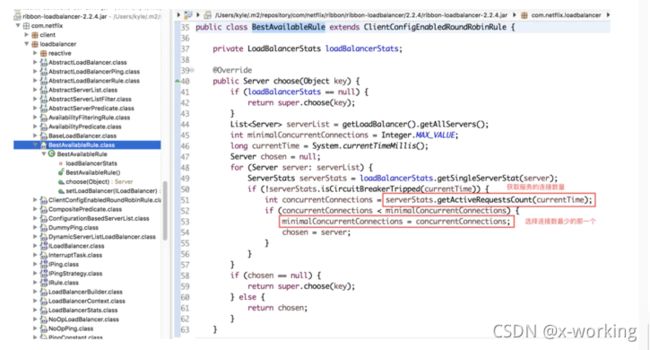
同时,由于该算法的核心依据是统计对象LoadBalancerStats,当其为空的时候,该策略是无法执行的。所以从源码中我们可以看到,当loadBalancerStats为空的时候,它会采用父类的线性轮询策略,正如我们在介绍ClientConfigEnabledRoundRobinRule时那样,它的子类在无法满足实现高级策略的时候,可以使用线性轮询策略的特性。后面将要介绍的策略因为也都继承自ClientConfigEnabledRoundRobinRule,所以它们都会具有这样的特性。
▪️PredicateBasedRule
这是一个抽象策略,它也继承了ClientConfigEnabledRoundRobinRule,从其命名中可以猜出这是一个基于Predicate实现的策略,Predicate是Google Guava Collections工具对集合进行过滤掉条件接口。
Google Guava Collections是一个对Java Collections Framework增强和扩展的开源项目。虽然Java Collections Framework已经能够满足我们大多数抢空下使用集合的要求,但是当遇到一些特殊情况时,我们的代码会比较冗长且容易出错。Google Guava Collections可以帮助我们让集合操作代码更为简短精炼并大大增强代码的可读性。
▪️AvailabilityFilteringRule
该策略继承自上面介绍的抽象策略PredicateBasedRule,所以它也继承了“先过滤清单,再轮询选择”的的基本处理逻辑,其中过滤条件使用了AvailabilityPredicate。简单地说,该策略通过线性抽样的方式直接尝试寻找可用且较空闲的实例来使用,优化了父类每次都要遍历所有实例的开销。
▪️ZoneAvoidanceRule
该策略我们在介绍负载均衡器ZoneAwareLoadBalancer时已经提到过,它也是PredicateBasedRule的具体实现类,在之前的介绍中主要针对ZoneAvoidanceRule中用于选择Zone区域策略的一些静态函数,比如createSnapshot(LoadBalancerStats lbStats)、getAvailableZones(Map snapshot, double triggeringLoad,double triggeringBlackoutPercentage)。在这里我们将详细看看ZoneAvoidanceRule作为服务实例过滤条件的实现原理。从下面ZoneAvoidanceRule的源码片段中可以看到,它使用了CompositePredicate来进行服务实例清单的过滤。这是一个组合过来条件,在其构造函数中,它以ZoneAvoidanceRule为主过滤条件,AvailabilityPredicate为次过滤条件初始化了组合过滤条件的实例。
如果需要給我修改意见的发送邮箱:[email protected]
本博客的代码示例已上传GitHub:Spring Cloud Netflix组件入门
资料参考:《Spring Cloud 微服务实战》
转发博客,请注明,谢谢。