Unet代码详解(三)损失函数和miou计算
所有代码来自博主Bubbliiiing,十分感谢
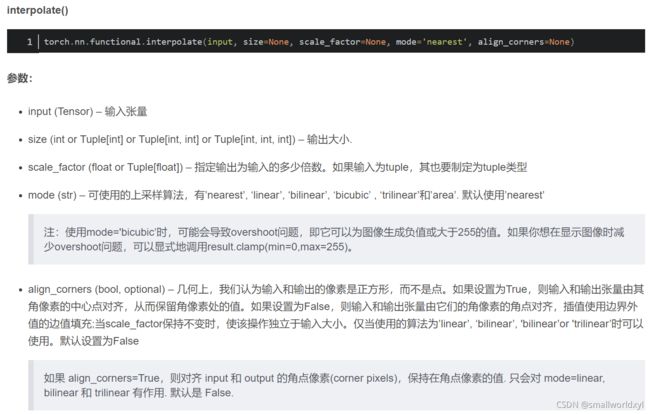
1.相关函数
(1)上采样函数Interpolate
(2)交叉熵损失函数CrossEntropyLoss

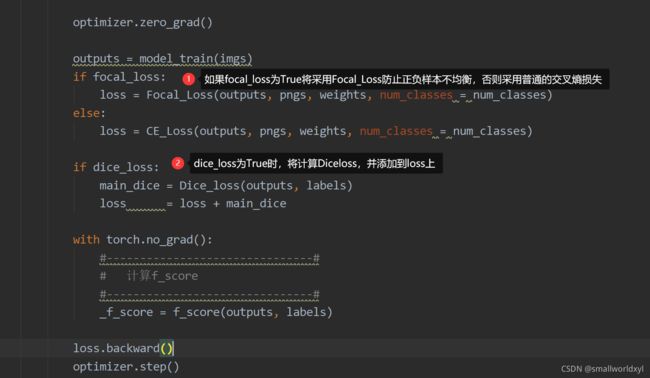
二.损失
先贴一段训练时的损失计算代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import nn
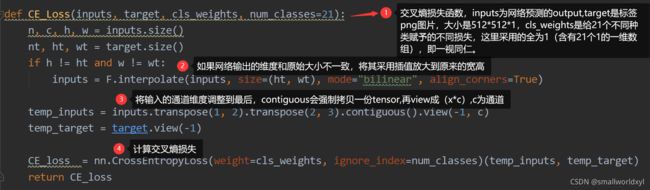
def CE_Loss(inputs, target, cls_weights, num_classes=21):
n, c, h, w = inputs.size()
nt, ht, wt = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = inputs.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
temp_target = target.view(-1)
CE_loss = nn.CrossEntropyLoss(weight=cls_weights, ignore_index=num_classes)(temp_inputs, temp_target)
return CE_loss
def Focal_Loss(inputs, target, cls_weights, num_classes=21, alpha=0.5, gamma=2):
n, c, h, w = inputs.size()
nt, ht, wt = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = inputs.transpose(1, 2).transpose(2, 3).contiguous().view(-1, c)
temp_target = target.view(-1)
logpt = -nn.CrossEntropyLoss(weight=cls_weights, ignore_index=num_classes, reduction='none')(temp_inputs, temp_target)
pt = torch.exp(logpt)
if alpha is not None:
logpt *= alpha
loss = -((1 - pt) ** gamma) * logpt
loss = loss.mean()
return loss
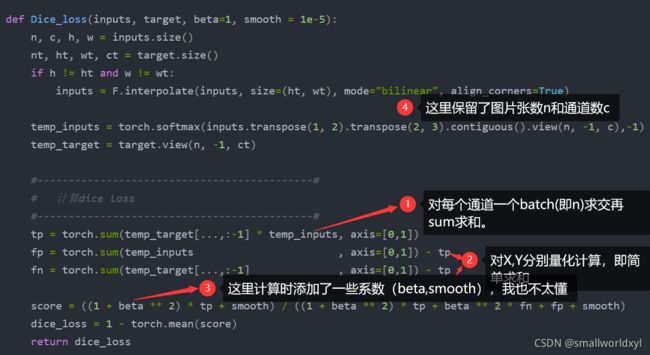
def Dice_loss(inputs, target, beta=1, smooth = 1e-5):
n, c, h, w = inputs.size()
nt, ht, wt, ct = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = torch.softmax(inputs.transpose(1, 2).transpose(2, 3).contiguous().view(n, -1, c),-1)
temp_target = target.view(n, -1, ct)
#--------------------------------------------#
# 计算dice loss
#--------------------------------------------#
tp = torch.sum(temp_target[...,:-1] * temp_inputs, axis=[0,1])
fp = torch.sum(temp_inputs , axis=[0,1]) - tp
fn = torch.sum(temp_target[...,:-1] , axis=[0,1]) - tp
score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
dice_loss = 1 - torch.mean(score)
return dice_loss
def weights_init(net, init_type='normal', init_gain=0.02):
def init_func(m):
classname = m.__class__.__name__
if hasattr(m, 'weight') and classname.find('Conv') != -1:
if init_type == 'normal':
torch.nn.init.normal_(m.weight.data, 0.0, init_gain)
elif init_type == 'xavier':
torch.nn.init.xavier_normal_(m.weight.data, gain=init_gain)
elif init_type == 'kaiming':
torch.nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
torch.nn.init.orthogonal_(m.weight.data, gain=init_gain)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
elif classname.find('BatchNorm2d') != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
print('initialize network with %s type' % init_type)
net.apply(init_func)
Dice系数,是一种集合相似度度量函数,通常用于计算两个样本的相似度(值范围为 [0, 1]):
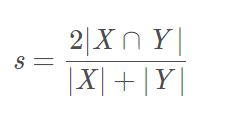
|X⋂Y| - X 和 Y 之间的交集;|X| 和 |Y| 分别表示 X 和 Y 的元素个数. 其中,分子中的系数 2,是因为分母存在重复计算 X 和 Y 之间的共同元素的原因.
语义分割问题而言,X - GT 分割图像, Y - Pred 分割图像.
作为LOSS的话是越小越好,所以使得Dice loss = 1 - Dice,就可以将Loss作为语义分割的损失了。
Dice 系数差异函数(Dice loss):
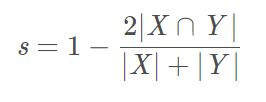
计算Dice 系数的代码一般如下(本文代码进行了修改,见上面或下面代码):
def dice_coeff(pred, target):
smooth = 1.
num = pred.size(0)
m1 = pred.view(num, -1) # Flatten
m2 = target.view(num, -1) # Flatten
intersection = (m1 * m2).sum()
return (2. * intersection + smooth) / (m1.sum() + m2.sum() + smooth)
三.miou计算
关于miou的概念和相关计算可以看我之前的博客,
语义分割指标—MIoU详细介绍(原理及代码)
from os.path import join
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
def f_score(inputs, target, beta=1, smooth = 1e-5, threhold = 0.5):
n, c, h, w = inputs.size()
nt, ht, wt, ct = target.size()
if h != ht and w != wt:
inputs = F.interpolate(inputs, size=(ht, wt), mode="bilinear", align_corners=True)
temp_inputs = torch.softmax(inputs.transpose(1, 2).transpose(2, 3).contiguous().view(n, -1, c),-1)
temp_target = target.view(n, -1, ct)
#--------------------------------------------#
# 计算dice系数
#--------------------------------------------#
temp_inputs = torch.gt(temp_inputs, threhold).float()
tp = torch.sum(temp_target[...,:-1] * temp_inputs, axis=[0,1])
fp = torch.sum(temp_inputs , axis=[0,1]) - tp
fn = torch.sum(temp_target[...,:-1] , axis=[0,1]) - tp
score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
score = torch.mean(score)
return score
# 设标签宽W,长H
def fast_hist(a, b, n):
#--------------------------------------------------------------------------------#
# a是转化成一维数组的标签,形状(H×W,);b是转化成一维数组的预测结果,形状(H×W,)
#--------------------------------------------------------------------------------#
k = (a >= 0) & (a < n)
#--------------------------------------------------------------------------------#
# np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
# 返回中,写对角线上的为分类正确的像素点
#--------------------------------------------------------------------------------#
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
def per_class_iu(hist):
return np.diag(hist) / np.maximum((hist.sum(1) + hist.sum(0) - np.diag(hist)), 1)
def per_class_PA(hist):
return np.diag(hist) / np.maximum(hist.sum(1), 1)
def compute_mIoU(gt_dir, pred_dir, png_name_list, num_classes, name_classes):
print('Num classes', num_classes)
#-----------------------------------------#
# 创建一个全是0的矩阵,是一个混淆矩阵
#-----------------------------------------#
hist = np.zeros((num_classes, num_classes))
#------------------------------------------------#
# 获得验证集标签路径列表,方便直接读取
# 获得验证集图像分割结果路径列表,方便直接读取
#------------------------------------------------#
gt_imgs = [join(gt_dir, x + ".png") for x in png_name_list]
pred_imgs = [join(pred_dir, x + ".png") for x in png_name_list]
#------------------------------------------------#
# 读取每一个(图片-标签)对
#------------------------------------------------#
for ind in range(len(gt_imgs)):
#------------------------------------------------#
# 读取一张图像分割结果,转化成numpy数组
#------------------------------------------------#
pred = np.array(Image.open(pred_imgs[ind]))
#------------------------------------------------#
# 读取一张对应的标签,转化成numpy数组
#------------------------------------------------#
label = np.array(Image.open(gt_imgs[ind]))
# 如果图像分割结果与标签的大小不一样,这张图片就不计算
if len(label.flatten()) != len(pred.flatten()):
print(
'Skipping: len(gt) = {:d}, len(pred) = {:d}, {:s}, {:s}'.format(
len(label.flatten()), len(pred.flatten()), gt_imgs[ind],
pred_imgs[ind]))
continue
#------------------------------------------------#
# 对一张图片计算21×21的hist矩阵,并累加
#------------------------------------------------#
hist += fast_hist(label.flatten(), pred.flatten(),num_classes)
# 每计算10张就输出一下目前已计算的图片中所有类别平均的mIoU值
if ind > 0 and ind % 10 == 0:
print('{:d} / {:d}: mIou-{:0.2f}; mPA-{:0.2f}'.format(ind, len(gt_imgs),
100 * np.nanmean(per_class_iu(hist)),
100 * np.nanmean(per_class_PA(hist))))
#------------------------------------------------#
# 计算所有验证集图片的逐类别mIoU值
#------------------------------------------------#
mIoUs = per_class_iu(hist)
mPA = per_class_PA(hist)
#------------------------------------------------#
# 逐类别输出一下mIoU值
#------------------------------------------------#
for ind_class in range(num_classes):
print('===>' + name_classes[ind_class] + ':\tmIou-' + str(round(mIoUs[ind_class] * 100, 2)) + '; mPA-' + str(round(mPA[ind_class] * 100, 2)))
#-----------------------------------------------------------------#
# 在所有验证集图像上求所有类别平均的mIoU值,计算时忽略NaN值
#-----------------------------------------------------------------#
print('===> mIoU: ' + str(round(np.nanmean(mIoUs) * 100, 2)) + '; mPA: ' + str(round(np.nanmean(mPA) * 100, 2)))
return mIoUs
这里对于compute_mIoU函数的参数进行一些解释
gt_dir:VOCdevkit/VOC2007/SegmentationClass/ 是分割的png标签图片目录
pred_dir:miou_out是输出miou结果的目录,没有时会创建
png_name_list:是读取的验证集的png图片的名称序列

num_classes:21分类的个数
name_classes:每个分类的名称
name_classes = ["background","aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
参考博客:
https://blog.csdn.net/qq_41375609/article/details/103447744
https://blog.csdn.net/CSDN_of_ding/article/details/111515226
https://blog.csdn.net/weixin_44791964/article/details/120113686
https://blog.csdn.net/JMU_Ma/article/details/97533768