PaddleX API开发模式快速上手文档
目录
- 一. 环境安装
-
- 1.1 PaddlePaddle-gpu安装
- 1.2 PaddleX安装
- 二. 快速训练
-
- 2.1 准备数据集
- 2.2 定义图像预处理与数据增强
- 2.3 定义并装载数据
- 2.4 开始训练
- 2.5 使用Visual查看训练情况
- 三. 部署推理
-
- 3.1 模型加载预测
PaddleX官方文档(以图像分类为例):PaddleX/docs/quick_start_API.md
硬件配置:
CPU:AMD 5800
GPU:NVIDIA GTX1080Ti
操作平台:Windows10 系统
一. 环境安装
1.1 PaddlePaddle-gpu安装
使用PaddleX前需要先安装paddlepaddle-gpu 或者 paddlepaddle(版本大于或等于2.2.0),安装方式(以CUDA10.2为例):
paddlepaddle-gpu:
# CUDA 10.2
pip install paddlepaddle-gpu==2.2.2 -i https://mirror.baidu.com/pypi/simple
paddlepaddle(cpu版):
# CPU only
python -m pip install paddlepaddle==2.2.2 -i https://mirror.baidu.com/pypi/simple
1.2 PaddleX安装
安装PaddleX依赖pycocotools包:
pip install cython
pip install pycocotools
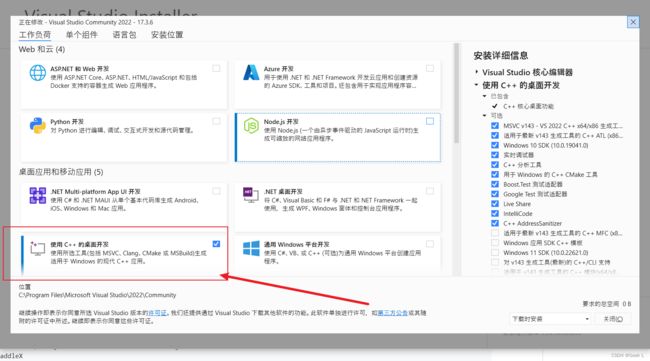
如果win10 已经安装了Visual Studio,则需要先在Visual Studio上安装VC build tools,具体需要先打开Visual Studio installer,然后选择C++桌面开发,如图所示:
如果没有安装Visual Studio,可以单独安装VC build tools:
点击下载VC build tools
VC build tools’安装完毕后,重新打开新的终端命令窗口,再执行如下pip命令:
pip install cython
pip install git+https://gitee.com/jiangjiajun/philferriere-cocoapi.git#subdirectory=PythonAPI
如果未报错则表明安装完毕。
二. 快速训练
2.1 准备数据集
准备数据集,这里以蔬菜分类数据为例,先下载数据, Linux直接在终端输入:
wget https://bj.bcebos.com/paddlex/datasets/vegetables_cls.tar.gz
tar xzvf vegetables_cls.tar.gz
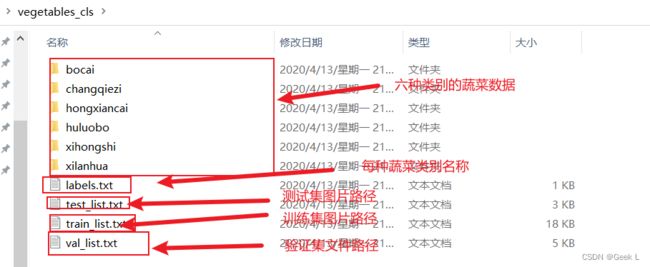
Win10可以把URL复制下来在浏览器下载,下载后的数据集目录格式如下:
2.2 定义图像预处理与数据增强
数据增强部分可以自由选择增强方式,这里使用随机裁剪和随机水平翻转两种脏强方式:
from paddlex import transforms as T
train_transforms = T.Compose([
T.RandomCrop(crop_size=224),
T.RandomHorizontalFlip(),
T.Normalize()])
eval_transforms = T.Compose([
T.ResizeByShort(short_size=256),
T.CenterCrop(crop_size=224),
T.Normalize()
])
2.3 定义并装载数据
定义数据读取路径,pdx.datasets.ImageNet表示读取ImageNet格式的分类数据集:
train_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/val_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=eval_transforms)
2.4 开始训练
加载MobileNetV3预训练模型开始微调训练,所选的预训练模型可以更改(PaddleX 图像分类模型API):
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small(num_classes=num_classes)
model.train(num_epochs=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small',
use_vdl=True)
2.5 使用Visual查看训练情况
进入虚拟环境后,命令行输入:
visualdl --logdir output/mobilenetv3_small --port 8001
启动visualdl,根据生成的URL进入到训练可视化网页:
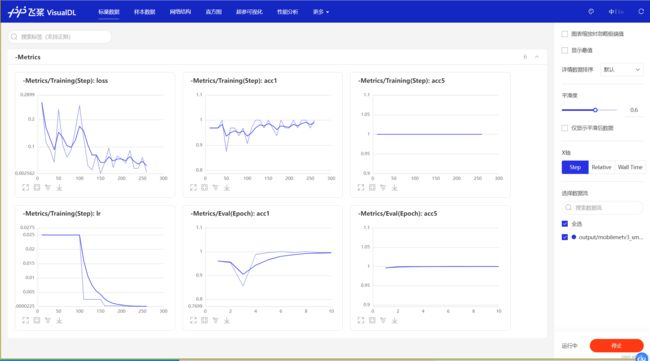
三. 部署推理
3.1 模型加载预测
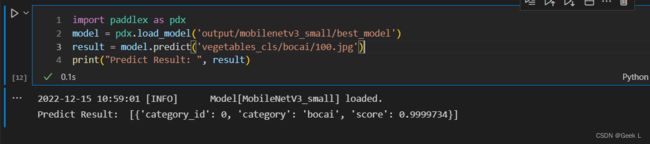
模型在训练过程中,会每间隔一定轮数保存一次模型,在验证集上评估效果最好的一轮会保存在save_dir目录下的best_model文件夹。通过如下方式可加载模型,进行预测:
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small/best_model')
result = model.predict('vegetables_cls/bocai/100.jpg')
print("Predict Result: ", result)