resnest中split-attention代码实现步骤解析
split-attention
先看看原论文的模型图,这里不讲论文的模型图,讲实际代码实现流程。

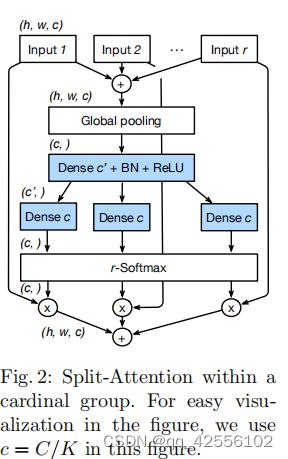
当我看完代码后发觉,代码实现步骤跟论文原图中的步骤是有差别的,当然内部实际计算是一样的。
下面我会以举例的形式呈现代码实现split-attention模块的计算步骤。
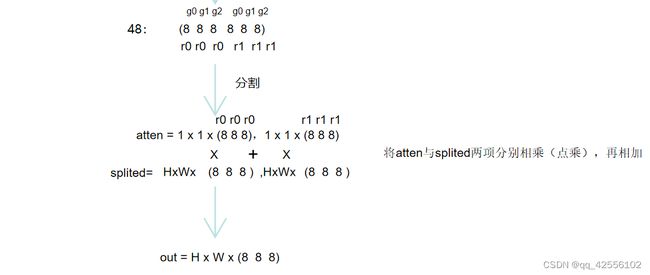
1.下面的步骤得到了splited元组,可以看到分组是radix组为大组,groups反倒是小组,这是为了方便代码操作才这样分。

2.下面的步骤由splited元组经过一系列分组卷积与池化得到初步的atten。

3.下面的步骤就是r-softmax的步骤,reshape确实将1*1*C的数据变成cardinal *radix * -1的数据

4.最后将splited与atten进行点乘相加,得到的out与input是相同的维度大小。
下面是split-attention代码
"""Split-Attention"""
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn import Conv2d, Module, Linear, BatchNorm2d, ReLU
from torch.nn.modules.utils import _pair
__all__ = ['SplAtConv2d']
class SplAtConv2d(Module):
"""Split-Attention Conv2d
基数cardinality =groups= 1 groups对应nn.conv2d的一个参数,即特征层内的cardinal组数
基数radix = 2 用于SplAtConv2d block中的特征通道数的放大倍数,即cardinal组内split组数
reduction_factor =4 缩放系数用于fc2和fc3之间减少参数量
"""
def __init__(self, in_channels, channels, kernel_size, stride=(1, 1), padding=(0, 0),
dilation=(1, 1), groups=1, bias=True,
radix=2, reduction_factor=4,
rectify=False, rectify_avg=False, norm_layer=None,
dropblock_prob=0.0, **kwargs):
super(SplAtConv2d, self).__init__()
# padding=1 => (1, 1)
padding = _pair(padding)
self.rectify = rectify and (padding[0] > 0 or padding[1] > 0)
self.rectify_avg = rectify_avg
# reduction_factor主要用于减少三组卷积的通道数,进而减少网络的参数量
# inter_channels 对应fc1层的输出通道数 (64*2//4, 32)=>32
inter_channels = max(in_channels*radix//reduction_factor, 32)
self.radix = radix
self.cardinality = groups
self.channels = channels
self.dropblock_prob = dropblock_prob
# 注意这里使用了深度可分离卷积 groups !=1,实现对不同radix组的特征层进行分离的卷积操作
if self.rectify:
from rfconv import RFConv2d
self.conv = RFConv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, average_mode=rectify_avg, **kwargs)
else:
self.conv = Conv2d(in_channels, channels*radix, kernel_size, stride, padding, dilation,
groups=groups*radix, bias=bias, **kwargs)
self.use_bn = norm_layer is not None
if self.use_bn:
self.bn0 = norm_layer(channels*radix)
self.relu = ReLU(inplace=True)
self.fc1 = Conv2d(channels, inter_channels, 1, groups=self.cardinality)
if self.use_bn:
self.bn1 = norm_layer(inter_channels)
self.fc2 = Conv2d(inter_channels, channels*radix, 1, groups=self.cardinality)
if dropblock_prob > 0.0:
self.dropblock = DropBlock2D(dropblock_prob, 3)
self.rsoftmax = rSoftMax(radix, groups)
def forward(self, x):
# [1,64,h,w] = [1,128,h,w]
x = self.conv(x)
if self.use_bn:
x = self.bn0(x)
if self.dropblock_prob > 0.0:
x = self.dropblock(x)
x = self.relu(x)
# rchannel通道数量
batch, rchannel = x.shape[:2]
if self.radix > 1:
# [1, 128, h, w] = [[1,64,h,w], [1,64,h,w]]
if torch.__version__ < '1.5':
splited = torch.split(x, int(rchannel//self.radix), dim=1)
else:
splited = torch.split(x, rchannel//self.radix, dim=1)
# [[1,64,h,w], [1,64,h,w]] => [1,64,h,w]
gap = sum(splited)
else:
gap = x
# [1,64,h,w] => [1, 64, 1, 1]
gap = F.adaptive_avg_pool2d(gap, 1)
# [1, 64, 1, 1] => [1, 32, 1, 1]
gap = self.fc1(gap)
if self.use_bn:
gap = self.bn1(gap)
gap = self.relu(gap)
# [1, 32, 1, 1] => [1, 128, 1, 1]
atten = self.fc2(gap)
atten = self.rsoftmax(atten).view(batch, -1, 1, 1)
# attens [[1,64,1,1], [1,64,1,1]]
if self.radix > 1:
if torch.__version__ < '1.5':
attens = torch.split(atten, int(rchannel//self.radix), dim=1)
else:
attens = torch.split(atten, rchannel//self.radix, dim=1)
# [1,64,1,1]*[1,64,h,w] => [1,64,h,w]
out = sum([att*split for (att, split) in zip(attens, splited)])
else:
out = atten * x
# contiguous()这个函数,把tensor变成在内存中连续分布的形式
return out.contiguous()
class rSoftMax(nn.Module):
def __init__(self, radix, cardinality):
super().__init__()
self.radix = radix
self.cardinality = cardinality
def forward(self, x):
batch = x.size(0)
if self.radix > 1:
# [1, 128, 1, 1] => [1, 2, 1, 64]
# 分组进行softmax操作
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
# 对radix维度进行softmax操作
x = F.softmax(x, dim=1)
# [1, 2, 1, 64] => [1, 128]
x = x.reshape(batch, -1)
else:
x = torch.sigmoid(x)
return x
代码原文链接:https://blog.csdn.net/Forrest97/article/details/109009203
总结
代码操作确实挺复杂的,也不是太懂为啥就这么做,其中split-attention中其实有两次radix分组,看我上面的步骤就能看到,并且只有groups(cardinal)组之间是没有进行交互的,radix组之间是存在交互且进行softmax的。最后我只想问(认真),这样子将通道搞来搞去真的有啥深意吗?说是模型比resnet及其多种变种都有更好的效果,但我怎么觉得很大的功劳是resnest训练时用的那些个提高准确度与泛化能力的tricks,这些tricks倒是可以学学。如果有明白模型深意的可以讨论讨论。