利用Python进行数据分析中 DataFrame轴的应用分类
DataFrame轴可分为:
行索引:index/axis=0(默认)
列索引:columns/axis=1
一.正相关(axis=0则在每行上操作,axis=1则在每列上操作)
1.行或列的删除
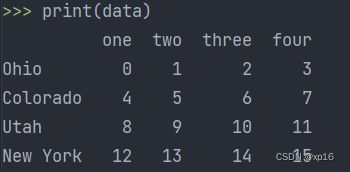
data=pd.DataFrame(np.arange(16).reshape((4,4)),
index=['Ohio','Colorado','Utah','New York'],
columns=['one','two','three','four'])
data.drop(['Colorado','Utah'])#删除行
print(data)
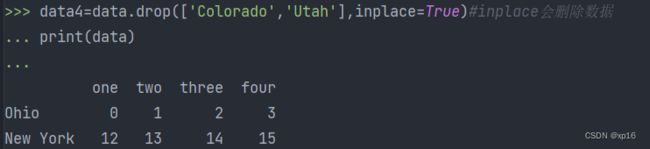
data4=data.drop(['Colorado','Utah'],inplace=True)#inplace会删除数据
print(data)
data2=data.drop('two',axis=1)#删除1列 或axis='columns'
print(data)
data3=data.drop(['two','three'],axis='columns',inplace=True)#删除多列
print(data)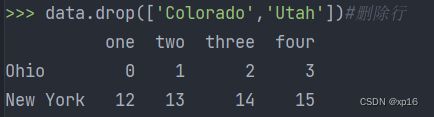
上面删除的数据仍存在
删除的数据已不存在
2.按行列索引排序
frame=pd.DataFrame(np.arange(8).reshape((2,4)),
index=['three','one'],
columns=['d','a','b','c'])
print(frame)
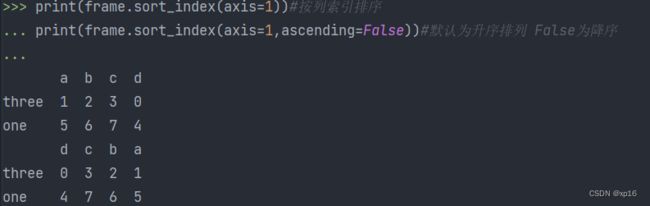
print(frame.sort_index(axis=0))#按行索引排序
print(frame.sort_index(axis=1))#按列索引排序
print(frame.sort_index(axis=1,ascending=False))#默认为升序排列 False为降序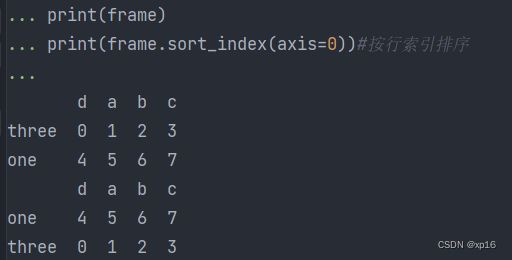
二.反相关(axis=0则在每列上操作,axis=1则在每行上操作)
1.按各行列中的值大小排列
frame=pd.DataFrame({'b':[4,7,-3,2],'a':[0,1,0,1]},index=['one','two','three','four'])
frame.sort_values(axis=1,by=['one','two','three','four'])#按行中的值大小排序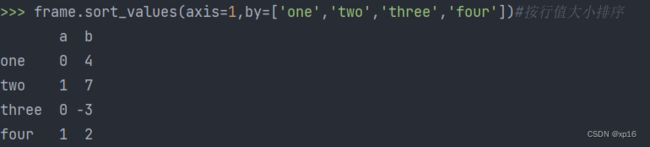
也可添加inplace属性,保存排序结果
2. 函数应用和映射
frame=pd.DataFrame(np.random.randn(4,3),columns=list('bde'),index=['Utah','Ohio','Texas','Oregon'])
print(frame)
#print(np.abs(frame))#取绝对值
f=lambda x: x.max()-x.min()
#lambda 函数是一种小的匿名函数。
#lambda 函数可接受任意数量的参数,但只能有一个表达式
print(frame.apply(f))#每列调用一次
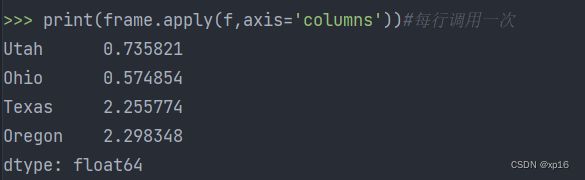
print(frame.apply(f,axis='columns'))#每行调用一次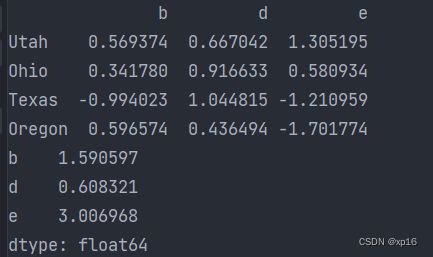
以上内容仅为本人记忆技巧
也可记忆为:
要对表中每一个值进行操作时,需另一个轴进行辅助定位。(如函数应用和映射,按各行列中的值大小排列等)
对各行进行操作时同一行中的不同列才可对应不同值,所以axis=1
反之,仅需要索引就可完成的操作,则使用对应索引类型即可。(如行列的删除,按行列索引排序等)
行:axis=0/'index'
列:axis=1/'columns'