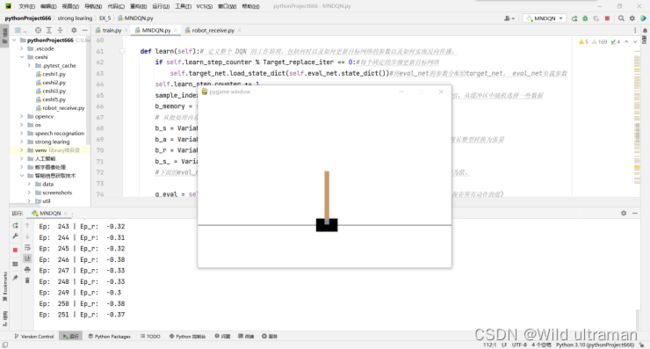
使用DQN来进行Gym中的CartPole-v1游戏
算法原理:
算法输入:迭代轮数T,状态特征向量维度n, 动作集A, 步长α,衰减因子γ , 探索率ϵ, Q网络结构, 批量梯度下降的样本数m。
输出:Q网络参数
1. 随机初始化Q网络的所有参数w,基于w初始化所有的状态和动作对应的价值Q。清空经验回放的集合D。
2. for i from 1 to T,进行迭代。
a) 初始化S为当前状态序列的第一个状态, 拿到其特征向量ϕ(S)
b) 在Q网络中使用ϕ(S)作为输入,得到Q网络的所有动作对应的Q值输出。用ϵ−贪婪法在当前Q值输出中选择对应的动作A
c) 在状态S执行当前动作A, 得到新状态S'对应的特征向量ϕ(S')和奖励R, 是否为终止状态 is_end
d) 将{ϕ(S),A,R,ϕ(S'),is_end}这个五元组存入经验回放集合D
e) S=S'
f) 从经验回放集合D中采样m个样本{ϕ(Sj),Aj,Rj,ϕ(Sj'),is_endj}, j=1,2,...,m, 计算当前目标Q值yj (TD target): 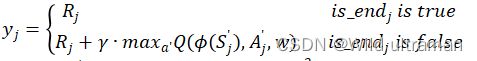
g) 使用均方差损失函数![]() , 通过神经网络的梯度反向传播来更新Q网络的所有参数w.
, 通过神经网络的梯度反向传播来更新Q网络的所有参数w.
h) 如果S'是终止状态,当前轮迭代完毕,否则转到步骤b)
使用OpenAI Gym中的CartPole-v0游戏来作为我们算法应用。CartPole-v1游戏基本要求就是控制下面的cart移动使连接在上面的pole保持垂直不倒。这个任务只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个cart的位置和速度, pole的角度和角速度,4维的特征(连续)。坚持到200分的奖励则为过关。
代码如下:
import torch
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
import torch.nn as nn
import numpy as np
import gym
Batch_size = 32
Lr = 0.01
Epsilon = 0.9
Gamma = 0.9
Target_replace_iter = 100
Memory_capacity = 2000
env = gym.make('CartPole-v1',render_mode="human")
env = env.unwrapped
N_actions = env.action_space.n
N_states = env.observation_space.shape[0]
ENV_A_SHAPE = 0 if isinstance(env.action_space.sample(), int) else env.action_space.sample().shape
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(N_states,50)
self.fc1.weight.data.normal_(0,0.1)
self.out = nn.Linear(50,N_actions)
self.out.weight.data.normal_(0,0.1)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
actions_value =self.out(x)
return actions_value
class DQN(object):
def __init__(self):
self.eval_net,self.target_net = Net(),Net()
self.learn_step_counter = 0
self.memory_counter = 0
self.memory = np.zeros((Memory_capacity,N_states*2 + 2))
self.optimizer = optim.Adam(self.eval_net.parameters(),lr=Lr)
self.loss_func = nn.MSELoss()
def choose_action(self,x):
x = Variable(torch.unsqueeze(torch.FloatTensor(x),0))
if np.random.uniform() < Epsilon:
action_value = self.eval_net.forward(x)
action = torch.max(action_value, 1)[1].data.numpy()
action = action[0] if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
else:
action = np.random.randint(0,N_actions)
action = action if ENV_A_SHAPE == 0 else action.reshape(ENV_A_SHAPE)
return action
def store_transition(self,s,a,r,s_):
transition = np.hstack((s,[a,r],s_))
index = self.memory_counter % Memory_capacity
self.memory[index,:] = transition
self.memory_counter += 1
def learn(self):
if self.learn_step_counter % Target_replace_iter == 0:
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step_counter += 1
sample_index = np.random.choice(Memory_capacity,Batch_size)
b_memory = self.memory[sample_index,:]
b_s = Variable(torch.FloatTensor(b_memory[:,:N_states]))
b_a = Variable(torch.LongTensor(b_memory[:,N_states:N_states+1].astype(int)))
b_r = Variable(torch.FloatTensor(b_memory[:,N_states+1:N_states+2]))
b_s_ = Variable(torch.FloatTensor(b_memory[:,-N_states:]))
q_eval = self.eval_net(b_s).gather(1,b_a)
q_next = self.target_net(b_s_).detach()
q_target = b_r +Gamma * q_next.max(1)[0].view(Batch_size, 1)
loss = self.loss_func(q_eval,q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def main():
dqn = DQN()# 创建DQN类的对象
print('\nCollecting experience...')
for i_episode in range(400):
s = env.reset()[0]
while True:
env.render()
ep_r = 0
a = dqn.choose_action(s)
s_,r,done,info,_ = env.step(a)
# 根据环境状态修改得分
x , x_dot ,theta ,theta_dat = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) /env.theta_threshold_radians - 0.5
r = r1 + r2
dqn.store_transition(s,a,r,s_)
ep_r += r
if dqn.memory_counter > Memory_capacity:
dqn.learn()
if done:
print('Ep: ', i_episode,
'| Ep_r: ', round(ep_r, 2))
if done:
break
s = s_
env.close()
if __name__ == '__main__':
main()
运行结果:
收集经验:
Collecting experience...
开始学习:
Ep: 202 | Ep_r: -0.39
Ep: 203 | Ep_r: -0.47
Ep: 204 | Ep_r: -0.41
Ep: 205 | Ep_r: -0.63
Ep: 206 | Ep_r: -0.57
Ep: 207 | Ep_r: -0.48
Ep: 208 | Ep_r: -0.49
Ep: 209 | Ep_r: -0.35
Ep: 210 | Ep_r: -0.46
Ep: 211 | Ep_r: -0.44
Ep: 212 | Ep_r: -0.55
Ep: 213 | Ep_r: -0.36
Ep: 214 | Ep_r: -0.35
Ep: 215 | Ep_r: -0.39
Ep: 216 | Ep_r: -0.38
Ep: 217 | Ep_r: -0.57
Ep: 218 | Ep_r: -0.75
Ep: 219 | Ep_r: -0.48
Ep: 220 | Ep_r: -0.39
Ep: 221 | Ep_r: -0.37
Ep: 222 | Ep_r: -0.37
Ep: 223 | Ep_r: -0.41
Ep: 224 | Ep_r: -0.41
Ep: 225 | Ep_r: -0.42
Ep: 226 | Ep_r: -0.37
Ep: 227 | Ep_r: -0.37
Ep: 228 | Ep_r: -0.61
Ep: 229 | Ep_r: -0.37
Ep: 230 | Ep_r: -0.96
Ep: 231 | Ep_r: -0.66
Ep: 232 | Ep_r: -0.38
Ep: 233 | Ep_r: -0.87
Ep: 234 | Ep_r: -0.51
Ep: 235 | Ep_r: -0.95
Ep: 236 | Ep_r: -0.59
Ep: 237 | Ep_r: -0.32
Ep: 238 | Ep_r: -0.33
Ep: 239 | Ep_r: -0.36
Ep: 240 | Ep_r: -0.33
Ep: 241 | Ep_r: -0.3
Ep: 242 | Ep_r: -0.34
Ep: 243 | Ep_r: -0.32
Ep: 244 | Ep_r: -0.31
Ep: 245 | Ep_r: -0.32
Ep: 246 | Ep_r: -0.38
Ep: 247 | Ep_r: -0.33
Ep: 248 | Ep_r: -0.33
Ep: 249 | Ep_r: -0.3
Ep: 250 | Ep_r: -0.38
Ep: 251 | Ep_r: -0.37
在学习了251次之后趋于稳定: