python取对数及作对数差在绘制散点图中的作用
文章目录
- 前言
- 一、diff()运算
- 二、三种情况下的散点图
-
- 1.取数据
- 2.绘制散点图
- 总结
前言
问题背景:在做两变量散点图分析其相关性时,在某本书上看到了如下操作:
trans_data = np.log(data).diff().dropna()
这行代码中,data是一个DataFrame格式的数据,这行代码的作用是,对每个数据取对数,再作差分(本行减去前一行作为本行的值,因此与原数据相比,第一行均为NAN),再去掉数据中为NAN的行。
这行代码运用在我的数据上,出现了貌似很好的效果:
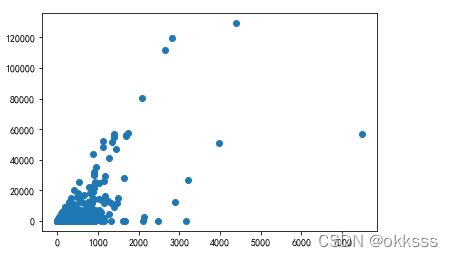
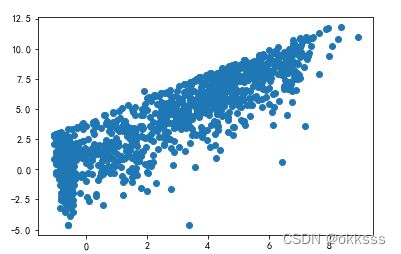
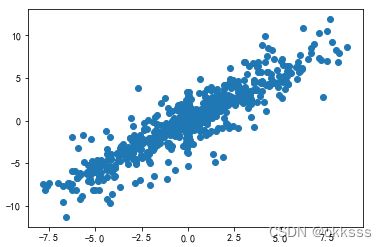
从上到下依次为直接作散点图、取对数后作散点图、取对数差后作散点图,可以看出:
- 直接作散点图时,由于两数据的数据范围比较大,数据分布不均匀,导致它们之间的关系不清晰,大概可以看出是正相关的;
- 取对数作散点图时,两数据的范围得到压缩,呈现比较明显的正相关;
- 取对数差之后,两数据是明显的正线性相关,于是我很怀疑书上为什么要先作对数差再作散点图。难道取对数差可以提取出数据的相关性吗?
- 由于我不太了解统计方面的说法,于是通过查阅网上信息和做一个简单的小实验证明:
(1)取对数可以压缩数据尺度,同时不改变相关性,方便观察数据之间的关系;
(2)取对数差是在取对数的基础上作差分运算,这其实可以看作近似增长率,也就是说如果取对数差,这时候研究的不是x与y的相关关系,而是x增长率与y增长率的相关关系。
于是取两组数据都是增长的,但增长率不规律变化
一、diff()运算
diff()函数用于作差分运算,它作的运算是,本行值减上一行值作为新的本行值,于是作diff()运算的DataFrame比原来的DataFrame少一行,体现新数据第一行均为NAN。
如下:
df1=np.random.randint(10,size=10)
df2=np.random.randint(10,size=10)
df3=np.random.randint(10,size=10)
df4=np.random.randint(10,size=10)
df = pd.DataFrame([df1,df2,df3,df4])
print(df)
print("作差分之后:")
df1 = df.diff()
print(df1)

二、三种情况下的散点图
1.取数据
(手动取的TAT):
df1 = {'1':[1000,2000,3500,5000,8000,10000,15000,20000,20001,20002,20003,22000,22020,22100,22300,22350,22450,22500],\
'2':[1,2,3,4,5,6,7,8,9,10,11,12,14,20,30,40,66,80]}
df = pd.DataFrame(df1)
print(df)
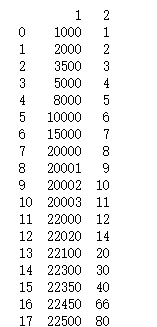
*注意两种创建DataFrame的方式,一中是列表套列表,这样属于按行创建,不能规定列索引。这里是字典转DF,属于按列创建,字典的键就是索引
可以看出上面两列数据,1和2都是增长的,1的增长率先快后慢,2的增长率先不变后快,总而言之数据有一定相关性但是它们增长率没什么关系
2.绘制散点图
代码如下(示例):
print("直接绘制散点图:")
plt.scatter(data=df,x='2',y='1')
plt.show()
print("取对数后绘制散点图:")
df_1 = np.log(df)
plt.scatter(data=df_1,x='2',y='1')
plt.show()
print("取对数差之后绘制散点图:")
df_2 = np.log(df).diff().dropna()
plt.scatter(data=df_2,x='2',y='1')
plt.show()



总结
研究两变量相关性的时候常作散点图,但是很多时候直接作散点图不易观察出数据相关性,取对数的好处是:由于对数函数的递增性,取对数不改变数据之间的相关性;由于对数运算可以压缩数据尺度,更加易于观察;还有一些统计学上的说法。
取对数差研究的是变量增长率之间的关系,它没有提取相关性的作用。