深度学习框架拾遗:【Pytorch(三)】——Pytorch结构化数据建模流程
import os
import datetime
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset
## 打印时间
def printbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"========"*8+"%s"%nowtime)
Step 1.数据准备
从https://github.com/lyhue1991/eat_pytorch_in_20_days下载titanic数据集,titanic数据集的目标是根据乘客信息预测他们在Titanic号撞击冰山沉没后能否生存。结构化数据一般会使用Pandas中的DataFrame进行预处理。
dftrain_raw = pd.read_csv('../data/titanic/train.csv')
dftest_raw = pd.read_csv('../data/titanic/test.csv')
dftrain_raw.head(10)
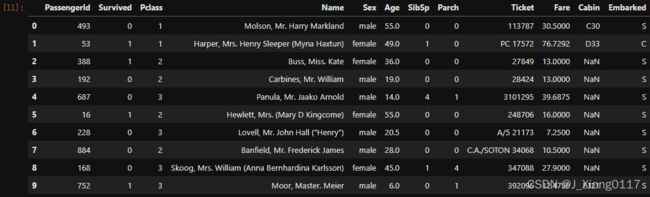
字段说明:
- Survived:0代表死亡,1代表存活【y标签】
- Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
- Name:乘客姓名 【舍去】
- Sex:乘客性别 【转换成bool特征】
- Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
- SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
- Parch:乘客父母/孩子的个数(整数值)【数值特征】
- Ticket:票号(字符串)【舍去】
- Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
- Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
- Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
Step 2.数据分析
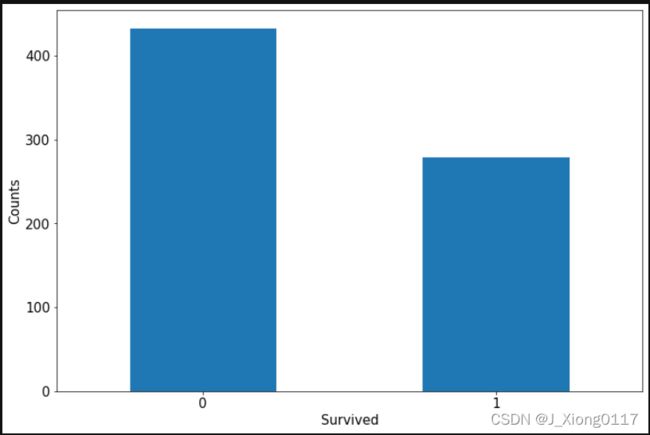
1)label分布情况
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Survived'].value_counts().plot(kind='bar',figsize=(12,8),fontsize=15,rot=0)
ax.set_ylabel('Counts',fontsize=15)
ax.set_xlabel('Survived',fontsize=15)
plt.show()
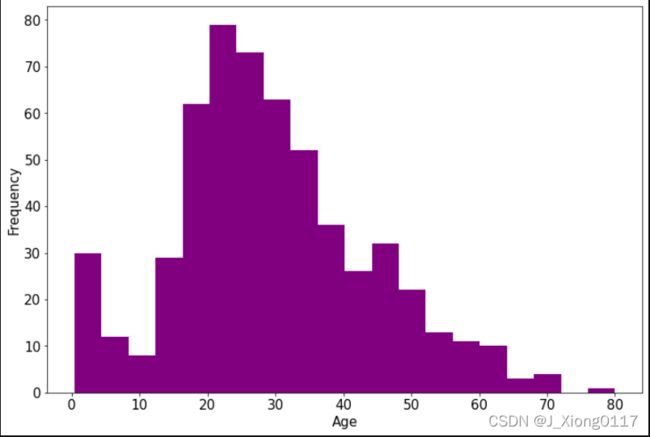
2)年龄分布情况
ax = dftrain_raw['Age'].plot(kind='hist',bins=20,color='purple',figsize=(12,8),fontsize=15)
ax.set_ylabel('Frequency',fontsize=15)
ax.set_xlabel('Age',fontsize=15)
plt.show()
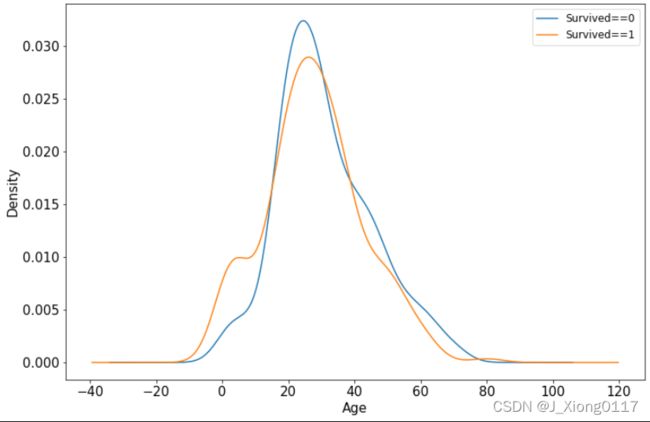
3)年龄和label的相关性
ax = dftrain_raw.query("Survived==0")['Age'].plot(kind='density',figsize=(12,8),fontsize=15)
dftrain_raw.query("Survived==1")['Age'].plot(kind='density',figsize=(12,8),fontsize=15)
ax.legend(['Survived==0','Survived==1'],fontsize=12)
ax.set_ylabel('Density',fontsize=15)
ax.set_xlabel('Age',fontsize=15)
plt.show()
Step 3.数据预处理
def preprocessing(dfdata):
dfresult= pd.DataFrame()
#Pclass
dfPclass = pd.get_dummies(dfdata['Pclass'])
dfPclass.columns = ['Pclass_' +str(x) for x in dfPclass.columns ]
dfresult = pd.concat([dfresult,dfPclass],axis = 1)
#Sex
dfSex = pd.get_dummies(dfdata['Sex'])
dfresult = pd.concat([dfresult,dfSex],axis = 1)
#Age
dfresult['Age'] = dfdata['Age'].fillna(0)
dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')
#SibSp,Parch,Fare
dfresult['SibSp'] = dfdata['SibSp']
dfresult['Parch'] = dfdata['Parch']
dfresult['Fare'] = dfdata['Fare']
#Carbin
dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')
#Embarked
dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
return(dfresult)
x_train = preprocessing(dftrain_raw).values
y_train = dftrain_raw[['Survived']].values
x_test= preprocessing(dftest_raw).values
y_test = dftest_raw[['Survived']].values
print("x_train.shape",x_train.shape)
print("y_train.shape",y_train.shape)
print("x_test.shape",x_test.shape)
print("y_test.shape",y_test.shape)
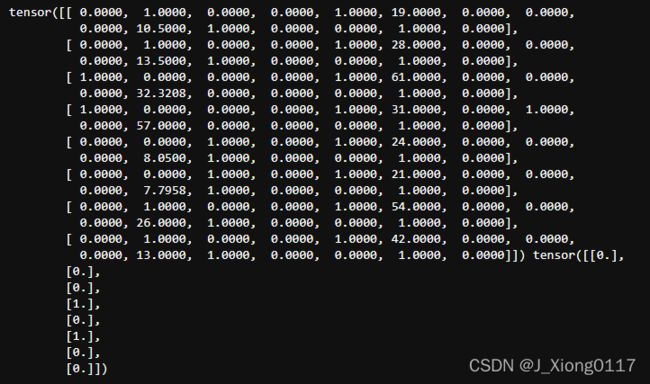
进一步使用DataLoader和TensorDataset封装成可以迭代的数据管道
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()),shuffle=True,batch_size=8)
dl_valid = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()),shuffle=False,batch_size=8)
# 测试数据管道
for features,labels in dl_train:
print(features,labels)
break
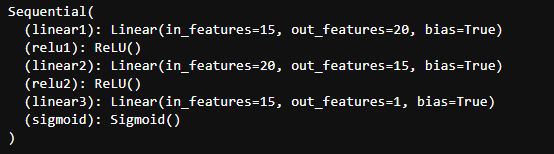
Step 4.定义模型
def creat_net():
net = nn.Sequential()
net.add_module("linear1",nn.Linear(15,20))
net.add_module("relu1",nn.ReLU())
net.add_module("linear2",nn.Linear(20,15))
net.add_module("relu2",nn.ReLU())
net.add_module("linear3",nn.Linear(15,1))
net.add_module("sigmoid",nn.Sigmoid())
return net
net = creat_net()
print(net)
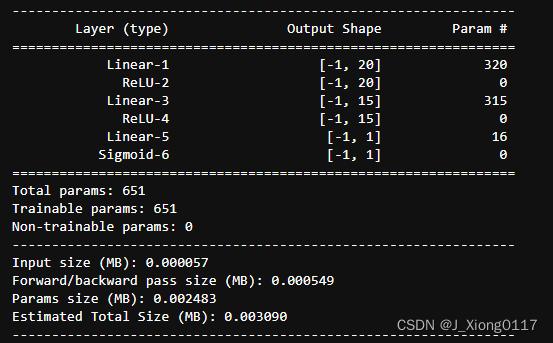
模型结构打印
from torchkeras import summary
summary(net,input_shape=(15,))
Step 5.训练模型
1)定义相关函数
from sklearn.metrics import accuracy_score
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(),lr=0.01)
metric_func = lambda y_pred,y_true:accuracy_score(y_true.data.numpy(),y_pred.data.numpy()>0.5)
metric_name = "accuracy"
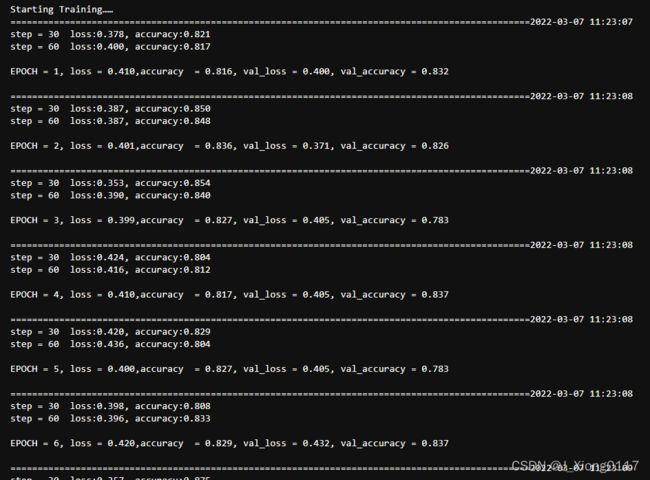
2)模型训练循环
epochs = 10
log_step_freq = 30
dfhistory = pd.DataFrame(columns=["epoch","loss",metric_name,"val_loss","val_"+metric_name])
print("Starting Training……")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("============"*8 + "%s"%nowtime)
for epoch in range(1,epochs+1):
# 1,---------------训练循环----------------
net.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step,(features,labels) in enumerate(dl_train,1):
# 梯度清零
optimizer.zero_grad()
# 正向传播求损失
predictions = net(features)
loss = loss_func(predictions,labels)
metric = metric_func(predictions,labels)
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
print(f"step = {step} loss:{(loss_sum/step):.3f}, {metric_name}:{(metric_sum/step):.3f}")
# 2,---------------验证循环----------------
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step,(features,labels) in enumerate(dl_valid,1):
# 关闭梯度计算
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions,labels)
val_metric = metric_func(predictions,labels)
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 3,---------------记录日志----------------
info = (epoch,loss_sum/step,metric_sum/step,val_loss_sum/val_step,val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"============"*8+"%s"%nowtime)
print("Finished Training!")
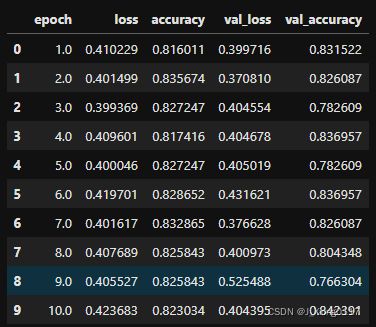
Step 6.评估模型
dfhistory
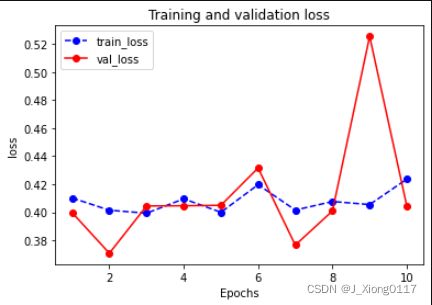
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(dfhistory,"loss")
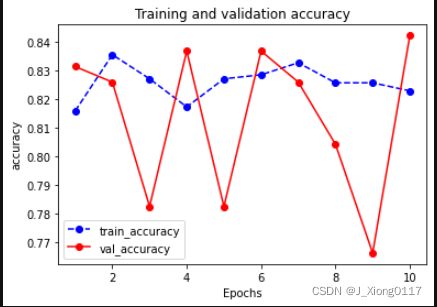
plot_metric(dfhistory,"accuracy")
Step 7.保存模型
torch.save(net.state_dict(),"../data/net_parameter.pkl")
Step 8.加载模型
net_clone = creat_net()
net_clone.load_state_dict(torch.load("../data/net_parameter.pkl"))
net_clone.forward(torch.tensor(x_test[0:10]).float()).data