在自己的数据集上调用cocoapi计算map
之前算map都是用模型在COCO数据集上跑,然后按官方的格式生成results.json,调用cocoapi和官方下载的instances_val2017.json计算就可以了。
现在模型是在自己的数据集上训练的,需要跑一批测试数据计算map recall等,这些图片都是标注好的,而且格式是darknet的,和coco要求的不一样。目录结构如下:
-
data
-
val.txt
-
obj.names
-
val_data
-
img1.jpg
-
img1.txt
-
img2.jpg
-
img2.txt
-
…
-
-
val.txt中存放了所有图片的路径:
/path/to/img1.jpg
/path/to/img2.jpg
...
obj.names中存放了所有的类别:
class1
class2
...
然后就是val_data目录下放的图片和标注信息了,格式和darknet官网要求的是一样的
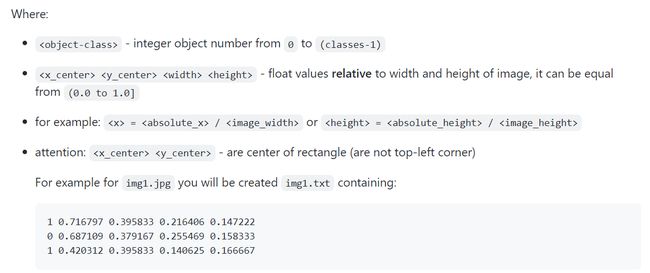
所以现在需要做的是把所有的标注txt文件合并成一个annotation.json作为ground truth,这个json文件的格式也要和官网要求的一致,否则调api会报错。然后和预测结果生成的result.json一起计算map,合并的代码如下:(python基本没学过,代码写的比较丑陋)
to_coco_format.py:
import pickle
import json
import numpy as np
import cv2
import os
DATA_PATH = '/workspace/data'
def _darknet_box_to_coco_bbox(box, img_width, img_height):
# darknet box format: normalized (x_ctr, y_ctr, w, h)
# coco box format: unnormalized (xmin, ymin, width, height)
box_width = round(box[2] * img_width, 2)
box_height = round(box[3] * img_height, 2)
box_x_ctr = box[0] * img_width
box_y_ctr = box[1] * img_height
xmin = round(box_x_ctr - box_width / 2., 2)
ymin = round(box_y_ctr - box_height / 2., 2)
bbox = np.array([xmin, ymin, box_width, box_height], dtype=np.float32)
return [xmin, ymin, box_width, box_height]
if __name__=='__main__':
cats = list()
with open('/workspace/data/obj.names', 'r') as f:
for line in f.readlines():
line = line.strip('\n')
cats.append(line)
cat_info = []
for i, cat in enumerate(cats):
cat_info.append({'name': cat, 'id': i})
image_set_path = os.path.join(DATA_PATH, 'val.txt')
ret = {'images': [], 'annotations': [], "categories": cat_info}
i = 0
for line in open(image_set_path, 'r'):
line = line.strip('\n')
i += 1
image_id = int(i)
image_info = {'file_name': '{}'.format(line), 'id': image_id}
ret['images'].append(image_info)
anno_path = line.replace('.jpg', '.txt')
anns = open(anno_path, 'r')
img = cv2.imread(line)
height, width = img.shape[0], img.shape[1]
for ann_id, txt in enumerate(anns):
tmp = txt[:-1].split(' ')
cat_id = tmp[0]
box = [float(tmp[1]), float(tmp[2]), float(tmp[3]), float(tmp[4])]
bbox = _darknet_box_to_coco_bbox(box, img_width=width, img_height=height)
area = round(bbox[2] * bbox[3], 2)
# coco annotation format
ann = {'image_id': image_id,
'id': int(len(ret['annotations']) + 1),
'category_id': int(cat_id),
'bbox': bbox,
'iscrowd': 0,
'area': area}
ret['annotations'].append(ann)
out_path = os.path.join(DATA_PATH, 'annotations.json')
json.dump(ret, open(out_path, 'w'))
这里的image_id用的有序编号,如果文件名比较规范,类似coco或voc那样可以根据文件名的后几位区分图片的话,也可以把那个直接当image_id。
生成后,就可以在预测的代码里用这个json文件了,生成预测的代码视自己的情况而定,我这里因为要部署所以转成tensorrt了,代码用的这个仓库的https://github.com/jkjung-avt/tensorrt_demos
eval_yolo.py:
"""eval_yolo.py
This script is for evaluating mAP (accuracy) of YOLO models.
"""
import os
import sys
import json
import argparse
import cv2
import pycuda.autoinit # This is needed for initializing CUDA driver
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
from progressbar import progressbar
from utils.yolo_with_plugins import TrtYOLO
from utils.yolo_classes import yolo_cls_to_ssd
HOME = os.environ['HOME']
# VAL_IMGS_DIR = '/workspace/downloads/data/coco/images/val2017'
# VAL_ANNOTATIONS = '/workspace/downloads/data/coco/annotations/instances_val2017.json'
VAL_IMGS_DIR = '/workspace/data/val_data'
VAL_ANNOTATIONS = '/workspace/data/annotations.json'
# 因为id不是选的文件名后几位,所以只能把json文件读出来存一下文件名和id的对应关系
file2id = dict()
with open(VAL_ANNOTATIONS) as f:
dic = json.load(f)
images = dic['images']
for i in range(len(images)):
image = images[i]
file2id[image['file_name']] = image['id']
def parse_args():
"""Parse input arguments."""
desc = 'Evaluate mAP of YOLO model'
parser = argparse.ArgumentParser(description=desc)
parser.add_argument(
'--imgs_dir', type=str, default=VAL_IMGS_DIR,
help='directory of validation images [%s]' % VAL_IMGS_DIR)
parser.add_argument(
'--annotations', type=str, default=VAL_ANNOTATIONS,
help='groundtruth annotations [%s]' % VAL_ANNOTATIONS)
parser.add_argument(
'--non_coco', action='store_true',
help='don\'t do coco class translation [False]')
parser.add_argument(
'-c', '--category_num', type=int, default=80,
help='number of object categories [80]')
parser.add_argument(
'-m', '--model', type=str, required=True,
help=('[yolov3|yolov3-tiny|yolov3-spp|yolov4|yolov4-tiny]-'
'[{dimension}], where dimension could be a single '
'number (e.g. 288, 416, 608) or WxH (e.g. 416x256)'))
parser.add_argument(
'-l', '--letter_box', action='store_true',
help='inference with letterboxed image [False]')
args = parser.parse_args()
return args
def check_args(args):
"""Check and make sure command-line arguments are valid."""
if not os.path.isdir(args.imgs_dir):
sys.exit('%s is not a valid directory' % args.imgs_dir)
if not os.path.isfile(args.annotations):
sys.exit('%s is not a valid file' % args.annotations)
def generate_results(trt_yolo, imgs_dir, jpgs, results_file, non_coco):
"""Run detection on each jpg and write results to file."""
results = []
for jpg in progressbar(jpgs):
img_path = os.path.join(imgs_dir, jpg)
img = cv2.imread(img_path)
# 原代码是用的文件名后几位,因为coco的命名是规范的
#image_id = int(jpg.split('.')[0].split('_')[-1])
image_id = file2id[img_path]
boxes, confs, clss = trt_yolo.detect(img, conf_th=1e-2)
for box, conf, cls in zip(boxes, confs, clss):
x = float(box[0])
y = float(box[1])
w = float(box[2] - box[0] + 1)
h = float(box[3] - box[1] + 1)
cls = int(cls)
# 自己的cat不需要转
# cls = cls if non_coco else yolo_cls_to_ssd[cls]
results.append({'image_id': image_id,
'category_id': cls,
'bbox': [x, y, w, h],
'score': float(conf)})
with open(results_file, 'w') as f:
f.write(json.dumps(results, indent=4))
def main():
args = parse_args()
check_args(args)
if args.category_num <= 0:
raise SystemExit('ERROR: bad category_num (%d)!' % args.category_num)
if not os.path.isfile('yolo/%s.trt' % args.model):
raise SystemExit('ERROR: file (yolo/%s.trt) not found!' % args.model)
results_file = 'yolo/results_%s.json' % args.model
trt_yolo = TrtYOLO(args.model, args.category_num, args.letter_box)
jpgs = [j for j in os.listdir(args.imgs_dir) if j.endswith('.jpg')]
generate_results(trt_yolo, args.imgs_dir, jpgs, results_file,
non_coco=args.non_coco)
# Run COCO mAP evaluation
# Reference: https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
cocoGt = COCO(args.annotations)
cocoDt = cocoGt.loadRes(results_file)
# imgIds = sorted(cocoGt.getImgIds())
cocoEval = COCOeval(cocoGt, cocoDt, 'bbox')
# cocoEval.params.imgIds = imgIds
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
if __name__ == '__main__':
main()
之后就大功告成可以正确计算map了: