一文详解仅用python底层代码实现关联规则与Apriori算法
一、基本概念
1.1. 项集的定义:在关联分析中,包含 0 0 0 个或多个项的集合称为项集.如果一个项集包含 k k k 个项,则称它为 − − k−项集.例如{牛奶,面包,麦片}是一个 3 − 3 − 3−项集.
我们把空集看成不包含任何项的项集.如果一个项集 X X X出现在某个事物 _ ti 对应的购物记录中,称该事物包含了该项集,记为 ⊆ ⊆ _ X⊆ti.每个事物包含的项集都是 I的子集.
1.2. 支持度的定义:项集的一个重要性质就是它的支持度计数,即包含该项集的事务个数.项集 X X X 的支持度计数可以用 σ ( ) = ∣ { : ⊆ , ∈ } ∣ \sigma() = |\{_: ⊆ _, _\in \}| σ(X)=∣{ti:X⊆ti,ti∈T}∣来表示
1.3. 关联规则的表示方式:形如 → \rightarrow X→Y的蕴
涵表达式,其中 X 和 Y 是是不相交的项集.关联规则的强度可以用它的支持度 s 和置信度 c 来度量,分别定义如下: ( → ) = σ ( ∪ ) N , ( → ) = σ ( ∪ ) σ ( X ) ( → ) =\frac{ \sigma(\cup)}{N} , ( \rightarrow ) = \frac{\sigma(\cup)}{\sigma(X)} s(X→Y)=Nσ(X∪Y),c(X→Y)=σ(X)σ(X∪Y)
二、理论基础
2.1. 关联规则的挖掘分解可以拆分成一下两个子任务:
(1)产生频繁项集:发现满足最小支持度阈值的所有项集,称为频繁项集;
(2)产生关联规则:从上一步发现的频繁项集中提取所有高置信度的规则.
如果采用对每个项集都计算其支持度计数的方式去发现频繁项集,必须将每个候选项集与每个事物去比较,这样做显然计算开销非常大.一个自然的思路就是能否利用频繁项集的性质在计算前减少候选项集的数目.对每一个非空项集来说,它的每个非空子集也是一个项集,并且包含大的项集的事务也一定包含该项集的每一个子集,因而我们有如下的先验原理.
2.2. (先验原理)设 X是项集,若 ′ ⊆ ^{′ }⊆ X′⊆X,则 σ ( ′ ) ≥ σ ( ) . \sigma(^{′}) ≥ \sigma(). σ(X′)≥σ(X).
因此如果一个项集是频繁的,则它的所有子集一定是频繁的.相反的,如果一个项集是非频繁的,则包含它的所有的项集一定是非频繁的.也就是说一旦发现某个项集是非频繁的,则可以立刻删除包含该项集的所有项集.
2.3. 基于 Apriori 算法产生频繁项集
Apriori 算法是关联规则挖掘频繁项集的原创性算法.算法使用一种称为逐层搜索的迭代方法,从寻找 1 − 1- 1−项集开始逐步寻找 − − k−项集,其中 ( − 1 ) − ( − 1) − (k−1)−项集用来寻找 − − k−项集,其中使用了前述的先验原理来压缩搜索空间.
首先,通过扫描数据库,累计每个项的计数,通过确定满足最小支持度的项得到频繁 1 − 1- 1−项集的集合 1 _1 L1,然后通过扫描数据库找出频繁 2 − 2- 2−项集的集合 2 _2 L2,使用 2 _2 L2 找出 3 _3 L3,如此下去,直到不能再找到频繁 ( + 1 ) − ( + 1) − (k+1)−项集.算法的核心思想包括以下两个部分:
(1)连接步:把 − 1 _{−1} Lk−1中的项按递增的字典序(可以简单理解为从小到大)排列,通过将 − 1 _{−1} Lk−1 与自身连接产生候选 − − k−项集的集合 _ Ck. − 1 _{−1} Lk−1中的两个项集 1 _1 l1 和 2 _2 l2 可以连接当且仅当其前 − 2 − 2 k−2 个项相同,连接而成的 − − k−项集即为 1 ∪ 2 _1\cup _2 l1∪l2.
(2)剪枝步: _ Lk 是 _ Ck 的子集,也就是说, _ Ck 的成员可能不是频繁 − − k−项集,但是所有的频繁 − − k−项集都在 _ Ck 中.因而需要扫描数据集确定 _ Ck 中每个元素的支持度计数,从而确定 _ Lk.这里可以利用先验原理来压缩 _ Ck.如果一个候选 − − k−项集的某个 ( − 1 ) − ( − 1) − (k−1)−项子集不在 − 1 _{−1} Lk−1中,则该候选 − − k−项集不可能是频繁的,从而可以从 _ Ck中删除.
三、代码实现
3.1. 基于以上理论基础,我们可以着手编程,在此我们以下购物篮中的商品购买情况作为实战模拟:
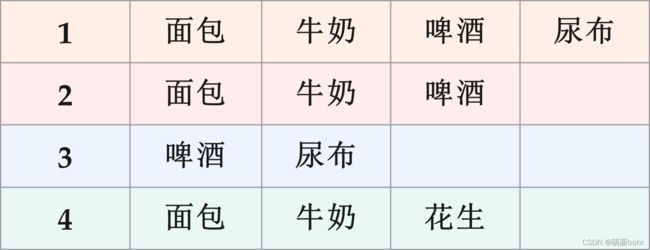
为了后续编程的方便,我们决定用数字代表购物篮中商品,分别用1代表面包,2代表牛奶,3代表啤酒,4代表尿布,5代表花生.
为实现该代码,我们通过对python中set函数以及list函数的灵活应用,同时我们还需要定义6个函数来帮助我们实现关联规则:
(1)实现数据的导入:
def loadDataSet():
"""导入数据"""
return [[1, 2, 3, 4], [1, 2, 3], [3, 4], [1, 2, 5]]
(2)通过迭代得到 k − k- k−项集以及支持度的集合:
def getkset_and_support(freList, dataSet, minSup):
length, resList, resSup, length2 = len(freList), [], [], len(dataSet)
"""连接步"""
for i in range(length - 1):
for j in range(i + 1, length):
t = sorted(list(set(freList[i]) | set(freList[j]))) #t是频繁项集连接后的新项集
if len(t) > len(freList[i]) + 1:
continue
if t not in resList:
resList.append(t)
resLen, num = len(resList), 0
"""剪枝步"""
while num < resLen:
sum = 0
for subSet in dataSet:
if (set(resList[num])).issubset(set(subSet)):
sum += 1
support = sum/1.0/length2 #计算新项集的支持度
if support >= minSup:
resSup.append(support)
num += 1
else:
resList.pop(num)
resLen -= 1
return resList, resSup
(3)得到频繁项集以支持度的集合:
def apriori(dataSet, minSup):
freList, supList, resList = [], [], []
allData = set()
for data in dataSet:
for i in data:
allData.add(i)
for i in allData:
resList.append([i])
resList, resSup = getkset_and_support(resList, dataSet, minSup) #迭代的开始
while resList:
freList.append(resList)
supList.append(resSup)
resList, resSup = getkset_and_support(resList, dataSet, minSup)
return freList, supList
(4)计算某一规则的置信度:
def getconfidence(tList, dataSet, support): #tList为一个规则的前缀,dataSet是导入的数据
sum = 0
for data in dataSet:
if set(tList).issubset(set(data)):
sum += 1
return support/(sum/1.0/len(dataSet)) #利用第一部分的计算公式得到置信度
(5)递归确定前缀:
def calConfidence(preList, fList, support, dataSet, minCon): #preList为规则的前缀,fList为规则的后缀
if len(preList) > 1:
for data in preList:
m = set(preList)
m.remove(data) #for循环遍历情况下,每次移除规则前缀中的一个值,其余的重新做为规则前缀
X = sorted(list(m)) #X为当前的规则前缀
Y = sorted(list(set(fList) - set(X))) #Y为规则后缀
confidence = getconfidence(X, dataSet, support)
if confidence >= minCon:
print(X, "->", Y, ":", confidence)
calConfidence(X, fList, support, dataSet, minCon)
return 0
(6)得到规则产生的函数:
def GetCorrRules(freList, supList, dataSet, minCon): #freList为所有的频繁项集,supList为频繁项集所对应的支持度
for i, List in enumerate(freList):
for j, fList in enumerate(freList[i]):
calConfidence(fList, fList, supList[i][j], dataSet, minCon)
(7)定义完成函数部分后我们可以进一步完善主体部分:
if __name__ == '__main__':
dataSet = loadDataSet()
minSup, minCon = 0.5, 0.7 #minSup最小支持度,minCon最小置信度
for data in dataSet:
data.sort()
freList, supList = apriori(dataSet, minSup)
print("频繁项集:", freList)
print("支持度集合:", supList)
GetCorrRules(freList, supList, dataSet, minCon)
运行代码即可得到:
频繁项集: [[[1, 2], [1, 3], [2, 3], [3, 4]], [[1, 2, 3]]]
支持度集合: [[0.75, 0.5, 0.5, 0.5], [0.5]]
[2] -> [1] : 1.0
[1] -> [2] : 1.0
[4] -> [3] : 1.0
[2, 3] -> [1] : 1.0
[1, 3] -> [2] : 1.0
3.2. 为方便读者自行尝试运行,完整代码如下:
def loadDataSet():
return [[1, 2, 3, 4], [1, 2, 3], [3, 4], [1, 2, 5]]
def getkset_and_support(freList, dataSet, minSup):
length, resList, resSup, length2 = len(freList), [], [], len(dataSet)
for i in range(length - 1):
for j in range(i + 1, length):
t = sorted(list(set(freList[i]) | set(freList[j])))
if len(t) > len(freList[i]) + 1:
continue
if t not in resList:
resList.append(t)
resLen, num = len(resList), 0
while num < resLen:
sum = 0
for subSet in dataSet:
if (set(resList[num])).issubset(set(subSet)):
sum += 1
support = sum/1.0/length2
if support >= minSup:
resSup.append(support)
num += 1
else:
resList.pop(num)
resLen -= 1
return resList, resSup
def apriori(dataSet, minSup):
freList, supList, resList = [], [], []
allData = set()
for data in dataSet:
for i in data:
allData.add(i)
for i in allData:
resList.append([i])
resList, resSup = getkset_and_support(resList, dataSet, minSup)
while resList:
freList.append(resList)
supList.append(resSup)
resList, resSup = getkset_and_support(resList, dataSet, minSup)
return freList, supList
def getconfidence(tList, dataSet, support):
sum = 0
for data in dataSet:
if set(tList).issubset(set(data)):
sum += 1
return support/(sum/1.0/len(dataSet))
def calConfidence(preList, fList, support, dataSet, minCon):
if len(preList) > 1:
for data in preList:
m = set(preList)
m.remove(data)
X = sorted(list(m))
Y = sorted(list(set(fList) - set(X)))
confidence = getconfidence(X, dataSet, support)
if confidence >= minCon:
print(X, "->", Y, ":", confidence)
calConfidence(X, fList, support, dataSet, minCon)
return 0
def GetCorrRules(freList, supList, dataSet, minCon):
for i, List in enumerate(freList):
for j, fList in enumerate(freList[i]):
calConfidence(fList, fList, supList[i][j], dataSet, minCon)
if __name__ == '__main__':
dataSet = loadDataSet()
minSup, minCon = 0.5, 0.7
for data in dataSet:
data.sort()
freList, supList = apriori(dataSet, minSup)
print("频繁项集:", freList)
print("支持度集合:", supList)
GetCorrRules(freList, supList, dataSet, minCon)