【一起入门NLP】中科院自然语言处理作业二:中英文语料训练CBOW模型获得词向量(pytorch实现)【代码+报告】
目录
一、CBOW模型
二、程序说明
1.输入与预处理模块
2.训练模块
参数设置
模型结构
训练过程
3.测试模块
4.输出处理模块
5.可视化模块
三、实验结果
中文结果可视化:
英文结果可视化:
四、疑问与思考
1.cbow模型与词向量是什么关系
2.keras如何实现cbow
3.jieba分词:
4.关于训练负样本的问题
5.为什么中文语料要加载停用词
学校自然语言处理第二次大作业,训练中英文语料获得词向量,那我们开始吧~、

作业要求:选一种词向量模型,训练一份中文语料以及一份英文预料,提交报告以及词向量训练结果
代码链接:https://download.csdn.net/download/qq_39328436/41932914
代码结构/使用说明:

- data文件夹中存储语料(中文语料以及英文语料由老师提供,另一份为中文停用词语料)
- output文件夹中存储输出的词向量文件
- script文件夹中为CBOW的脚本,同时处理中文语料与英文语料
- 运行步骤:在脚本中确定训练中文或者是英语后,直接运行即可
一、CBOW模型

连续词袋模型(continuous bag of words, CBOW)
- CBOW是通过周围词去预测中心词的模型(skip-gram是用中心词预测周围词)
- word-embedding:将高维的词转换为低维的词表示。与one-hot的01编码不一样,embedding之后向量中是一些浮点数
- 拥有相似或者相同的上下文的多个词可能是近义词或者同义词
- 模型结构:
- 模型训练过程:
- 当前词的上下文词的one-hot编码(1*V:V表示不同的词语数量)送入输出层
- 这些词分别乘以同一个矩阵W1后,分别得到各自的1*N向量(这个就是词向量,N是降维之后的维度)
- 这些1*N向量相加取平均,得到一个新的1*N向量
- 将这个1*N向量乘矩阵W2得到一个1*V向量\
- 将这个1*Vsoftmax归一化之后输出每个词的概率向量1*V
- 将概率值最大的数对应的词作为预测值\
- 将预测结果的1*V向量,与真实标签的1*V向量计算误差
- 在每次向前传播之后反向传播误差,不断调整W1和W2矩阵的值
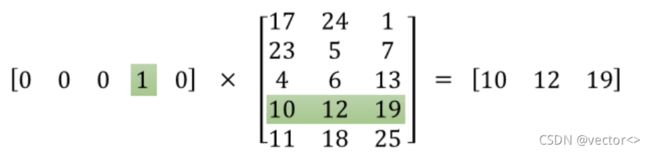
- 用CBOW训练词向量,想得到的是W1这个V*N的矩阵。当我们要查某个词向量的时,只需要和W1相乘就能得到结果。

二、程序说明
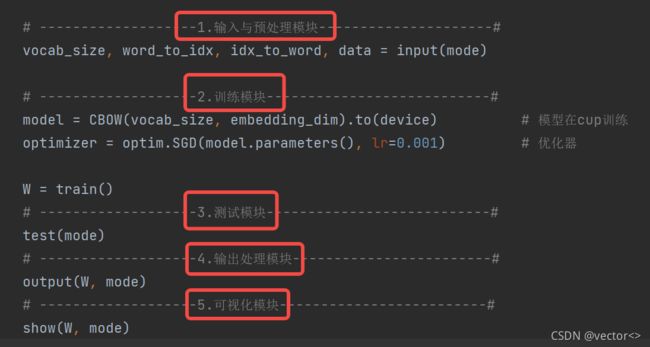
本程序共分为5个模块,首先对语料进行输入以及预处理,然后送入模型进行训练,训练完成后便获得了词向量矩阵。简单对训练好的CBOW模型进行测试,即判断输入周围词获得的中心预测值是否和标签一致。最后将词向量存储在txt文件中,并挑选1000个词向量在降为2维之后绘制在平面图中。
1.输入与预处理模块
相较于英文语料,加载中文语料时需要过滤一遍停用词,这是因为中文语料中会出现较多的特殊符号以及语气助词,例如:“啊,哎呀,哎哟”等,这些词语会干扰训练。
另外处理中文语料的一个难点是分词,即将一句话如“我超级想学习”,分割成“我 超级 想 学习”,常用的分词方法是jieba结巴分词(在本篇报告的最后一部分有介绍),由于提供的中文语料已经完成了分词操作,因此这边不再赘述。
读入数据之后还需要将其处理以便于训练,在第一部分在对CBOW的介绍中有提到这个模型是根据周围词来预测中心词,因此周围词是输出,中心词是标签。需要按照{[w1,w2,w4,w5],"label"}的格式构造一个词表,如:“the present food surplus can specifically.....”,可以构造(['the', 'present', 'surplus', 'can'], 'food') 以及(['present', 'food', 'can', 'specifically'],'surplus')可以理解为一个滑动窗口的机制,至于窗口多大根据训练要求确定的。
2.训练模块
参数设置
- mode = "en" :本程序将中英语词向量的训练整合在了同一个文件中,通过mode来控制,训练中文语料时将mode="en"注释掉即可。
- context_size = 2 :这个参数便是我上文提到的“滑动窗口”的大小,上下文分别两个词
- embedding_dim=100:设定词向量的维度为100维,即训练完成之后每个词都将是由100个浮点数表示,这个参数一般都设置为100-300左右。
- epochs = 10 :共训练十次
- 损失函数:nn.NLLLoss()
- 优化器:optim.SGD()
模型结构
| class CBOW(nn.Module): def __init__(self, vocab_size, embedding_dim): super(CBOW, self).__init__() self.embeddings = nn.Embedding(vocab_size, embedding_dim) self.proj = nn.Linear(embedding_dim, 128) self.output = nn.Linear(128, vocab_size) def forward(self, inputs): embeds = sum(self.embeddings(inputs)).view(1, -1) out = F.relu(self.proj(embeds)) out = self.output(out) nll_prob = F.log_softmax(out, dim=-1) return nll_prob |
- 第一层:嵌入层
- nn.Embedding(vocab_size, embedding_dim)其中vocab_size表示词表的大小,embedding_dim表示词向量维度。
- 输入必须是LongTensor
- embedding之后的词向量会存储在nn.Embedding.weight变量中,所以对于本次实验我们想要获得的词向量只是这一层的一个中间结果
- 嵌入层后再经过一个relu函数
- 第二层:线性层
- nn.Linear(embedding_dim, 128)输入为embedding_dim个结点,输出为128个结点。
- 第三层:输出层
- nn.Linear(128, vocab_size)输入为128个结点,输出为vocab_size个结点
- 输出层之后再经过一个softmax函数
训练过程
| for epoch in trange(epochs): total_loss = 0 for context, target in tqdm(data): context_vector = make_context_vector(context, word_to_idx).to(device) # 把训练集的上下文和标签都放到cpu中 target = torch.tensor([word_to_idx[target]]) model.zero_grad() # 梯度清零 train_predict = model(context_vector) # 开始前向传播 loss = loss_function(train_predict, target) loss.backward() # 反向传播 optimizer.step() # 更新参数 total_loss += loss.item() losses.append(total_loss) |
训练时需要注意,输入的上下文以及标签中心词都应该是张量形式,经过模型处理后输出值与标签都送入损失函数计算损失,损失向后传播并更新参数。经过十轮训练后,将embedding层的weight变量取出,里面存储的即为训练好的词向量
3.测试模块
由于实验不要求模型的准确率,所以测试模块仅做简单的预判。模型输出最大值即为预测值的下标。
4.输出处理模块
词向量矩阵中某个词的索引所对应的那一列即为所该词的词向量,将生成的词向量结果将保存在txt文件中,每一个词都由100维(100个浮点数)表示。

5.可视化模块
词向量设定为100维度,为将词向量进行可视化,首先要将维度降到2维,以便在坐标系中进行表示,用到的降维方法为PCA。考虑到可视化的效果,只取1000个词进行可视化。另外,为了将中文标签正确在figure中显示,需要设置plt.rcParams['font.sans-serif'] = ['SimHei'] 。
三、实验结果
中文结果可视化:

英文结果可视化:
四、疑问与思考
1.cbow模型与词向量是什么关系
从零开始学自然语言处理(十三)——CBOW原理详解
词向量矩阵是CBOW模型的参数,CBOW本身的作用是用来进行中心词预测,当模型训练好了之后,说明参数矩阵经过损失传播调整以及优化后也收敛到了最佳状态,对于目标语料产生了最佳的词向量表示。
2.keras如何实现cbow
从零开始学自然语言处理(二)——手把手带你用代码实现word2vec
3.jieba分词:
从零开始学自然语言处理(一)—— jieba 分词
- 分词的目标:将段落和句子切分为词语
- jieba:是一款优秀的中文分词工具
4.关于训练负样本的问题
CBOW 是用周围词去预测中心词。怎么预测呢?就比如给了一个训练语料“我/出生/在/中国/。”,当给定[“我”,“出生”,“中国”,“。”]时,此时我的训练目标就是要预测“在”这个词的概率要大于其它所有词(即语料库中所有除了“在”的所有词)的概率。
但是词库中的词可能会有几十万个,这样训练下去想要收敛就会变得十分困难。因此提出 word2vec 的神人们就想出了一个取巧的方法:我给它要求降低一点,我不要求模型从几十万个词找到那个正确的中心词,我只要求模型能从十几个词中找到正确的中心词就可以了。因此就用到了 negtive sampling。
那为什么我们的代码中没有负样本一说呢,这是由于本次实验的目标是并不是测试模型效果,并且模型的规模也有限。
5.为什么中文语料要加载停用词
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。