【一起入门NLP】中科院自然语言处理作业五:BiLSTM+Attention实现SemEval-2010 Task 8上的关系抽取(Pytorch)【代码+报告】
这里是国科大自然语言处理的第五次作业(终于是最后一次作业了,冲!),本篇博客是记录对论文:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification 的复现过程。现在我们开始吧(今天也是花里胡哨的一天呢)
目录
- 1. 程序与实验说明
- 实验要求
- 程序说明
- 2. 知识概述
- 2.1 信息抽取
- 2.2 关系抽取
- 2.3 LSTM与BiLSTM
- 3. 数据
- 数据来源
- 数据处理
- 4. 模型
- 模型结构
- LSTM Layer
- Attention Layer
- 5. 训练
- 训练参数
- 训练效果
- 6. 测试
1. 程序与实验说明
实验要求
- 任选一个深度学习框架建立一个关系抽取模型,实现在英文数据集SemEval-2010 Task8上进行的关系抽取。
- 测评指标使用的是官方给出的scorer,其实现基于perl语言,位于SemEval2010_task8_all_data\SemEval2010_task8_scorer-v1.2路径下,为semeval2010_task8_scorer-v1.2.pl,实验报告中需给出测评得到的macro-F1 score。
程序说明
代码:https://download.csdn.net/download/qq_39328436/71920051
按照顺序分别执行:
python run.py --mode=1 # 训练
python run.py --mode=0 # 测试
perl semeval2010_task8_scorer-v1.2.pl proposed_answer.txt predicted_result.txt >> result.txt # 用perl工具计算F1值
程序目录如下:
- data:存储原始语料,数据预处理文件,词向量文件。原始语料需解压data/SemEval2010_task8_all_data目录下。
- embedding:存储预训练glove数据
- output:存储训练好的模型
- config.py:描述参数配置
- evaluatepy:描述精度
- model.py:米哦啊书模型
- result.txt:输出的精度结果
- run.py:主函数
- utils.py:描述数据加载
- semeval2010_task8_scorer-v1.2.pl:用于计算精度的perl工具
2. 知识概述
2.1 信息抽取
任务描述:
- 从自然语言文本中抽取指定类型的实体、 关系、 事件等事实信息,并形成结构化数据输出的文本处理技术。一般情况下命名实体识别是知识抽取等其他任务的基础。
信息抽取主要包括以下子任务:
- 实体识别和抽取(Named Entity Recognition,NER)
- 实体消歧(entity resolution)
- 关系抽取(Relation Extraction,RE)
- 事件抽取(Event Extraction,EE)
在对无结构自然语言文本进行信息抽取的时候,任务包含两部分:命名实体识别和关系抽取。
2.2 关系抽取
任务描述:
- 从文本中识别抽取实体及实体之间的关系。抽取结果一般以三元组形式呈现。
比如:
- 比尔盖茨是微软的CEO:CEO(比尔盖茨, 微软)
- 信工所在闵庄路:Located-in (信工所, 闵庄路)
关系抽取的方法:
- 规则方法 :人工编制各种识别实体的规则,利用规则来识别。成本高,覆盖面底。
- 基于统计的抽取方法:基本思想:将关系实例转换成高维空间中的特征向量或直接用离散结构来表示,在标注语料库上训练生成分类模型, 然后再识别实体间关系。
- 基于神经网络的抽取方法:设计合理的网络结构, 从而捕捉更多的特征信息, 进而准确的进行关系分类
2.3 LSTM与BiLSTM
参考:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
-
LSTM用来解决普通RNN模型存在的长距离依赖问题:距当前节点越远的节点对当前节点处理影响越小,无法建模长时间依赖。
-
RNN由很多循环的单元构成,在标准的RNN中,这个重复的单元只有一个非常简单的结构,比如一个tahn层。
-
LSTM同样也是循环的结构,只是这个重复的单元开始变得复杂起来。
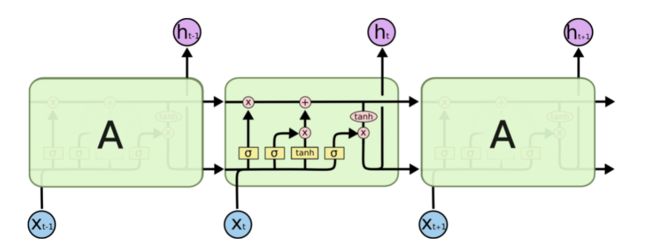
-
在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。

-
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。 细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
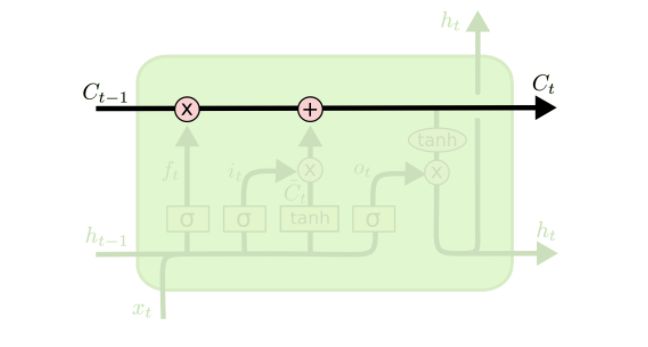
-
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。下图是一个门结构:
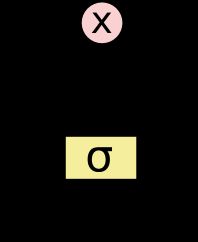
-
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”。LSTM 拥有三个门,来保护和控制细胞状态。
-
遗忘门:决定从细胞状态中丢弃什么信息。
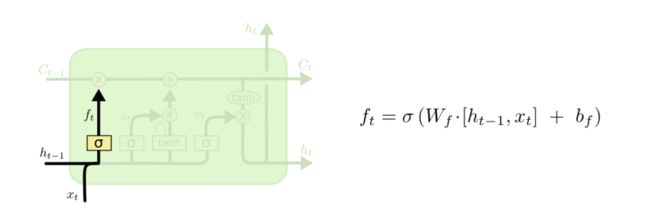
-
输入门:决定什么样的新信息会被存入细胞状态
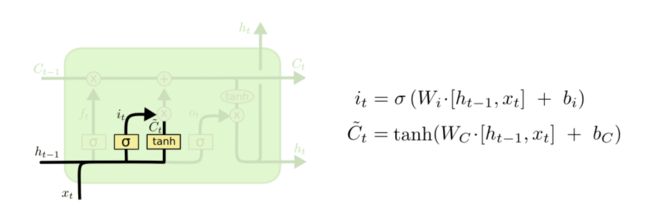
-
输出门:决定输出什么样的值
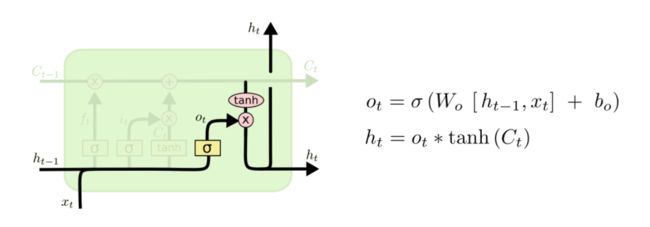
-
LSTM都只能依据之前时刻的时序信息来预测下一时刻的输出,但在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。比如预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。
-
所谓的Bi-LSTM可以看成是两层神经网络,第一层从左边作为系列的起始输入,在文本处理上可以理解成从句子的开头开始输入,而第二层则是从右边作为系列的起始输入,在文本处理上可以理解成从句子的最后一个词语作为输入,反向做与第一层一样的处理处理。最后对得到的两个结果进行处理。
3. 数据
数据来源
-
本次实验所用的数据集是完全监督的关系抽取数据集SemEval-2010 Task8。这个数据集包含了10717个样本,其中,8000个为训练样例,2717个测试样例。其中,训练集数据在TRAIN_FILE.TXT,测试集数据在TEST_FILE.TXT中。
-
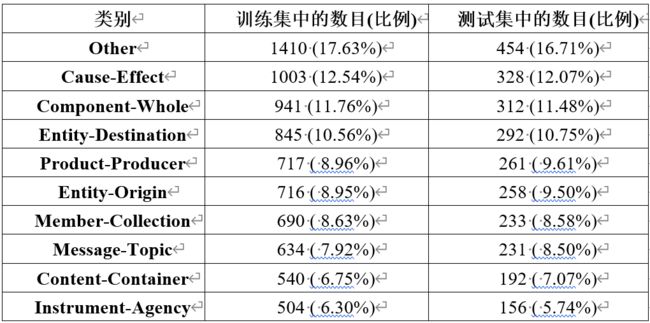
这个数据集包含了9种基本关系和1种人工分类关系Other。这九种关系分别为:Cause-Effect、Component-Whole、Entity-Destination、Product-Producer、Entity-Origin、Member-Collection、Message-Topic、Content-Container、Instrument-Agency。特别需要说明的是,另一种关系Other是一种人工分类关系,其表示的是不属于这9种关系之一,而并不是一种独特的关系。
-
在SemEval-2010 Task8的训练集以及测试集中,上述10种关系的数目和比例如下所示:
- SemEval-2010 Task8的训练集和测试集的数据格式相同。每一个样例由三行内容组成,其中第一行为样例的序号以及具体的语句内容,第二行为此语句中两个实体的关系,第三行为对于此样例的注释:
8001 " The most common audits were about waste and recycling . "
Message-Topic(e1 ,e2)
Comment: Assuming an audit = an audit document .
- 在样例的每一个句子中,对于实体,其使用了标签将其标注出来。在说明关系的时候,考虑了这两个实体的顺序。这意味着Cause-Effect(e1,e2)和Cause-Effect(e2,e1)是两个不同的关系。因此,在实际实验中,通常认为在此数据集中包含了19种关系。
数据处理
- preprocess.py对数据进行预处理。将原始语料中三行的形式转换为标准的json格式,并且完成英文分词以及实体分割符号<>
{"id": "8001", "relation": "Message-Topic(e1,e2)", "sentence": ["The", "most", "common", "" , "audits", "", "were", "about", "" , "waste", "", "and", "recycling", "."], "comment": " Assuming an audit = an audit document."}
- 在词嵌入word_embedding过程中用到了Glove算法预先训练数据,glove.6B.100d.txt是该算法需要用的预训练数据
- Glove的全称叫Global Vectors for Word Representation,是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
4. 模型
模型结构
模型分为五个部分
- 输入层(Input layer):将句子输入模型
- 嵌入层(Embedding layer):将每个词映射到一个低维向量
- LSTM层(LSTM layer):利用BiLSTM从词向量中获得特征
- Attention层(Attention layer):生成权重向量,将每个时间步长的单词级特征与权重向量相乘,合并成句子级特征向量
- 输出层(Output layer): 使用句子级特征向量进行关系分类
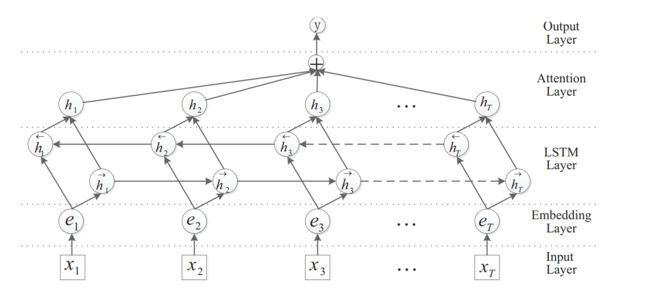
LSTM Layer
- bidirectional=True表示双向LSTM,可以考虑到上下文的信息,相比于单向LSTM会有更好的效果。
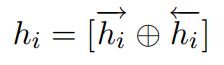
self.lstm = nn.LSTM(
input_size=self.word_dim,
hidden_size=self.hidden_size,
num_layers=self.layers_num,
bias=True,
batch_first=True,
dropout=0,
bidirectional=True,
)
def lstm_layer(self, x, mask):
lengths = torch.sum(mask.gt(0), dim=-1)
x = pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=False)
h, (_, _) = self.lstm(x)
h, _ = pad_packed_sequence(h, batch_first=True, padding_value=0.0, total_length=self.max_len)
h = h.view(-1, self.max_len, 2, self.hidden_size)
h = torch.sum(h, dim=2) # B*L*H
return h
Attention Layer
H:LSTM层的输出
w:是需要训的一组参数向量
h*:为最终用于分类的hidden state
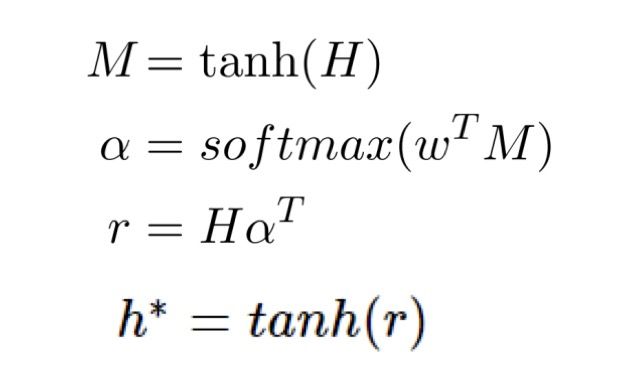
- att_score = torch.bmm(self.tanh(h), att_weight):实现了第一行和第二行公式
- torch.bmm(h.transpose(1, 2), att_weight).squeeze(dim=-1):实现第三行公式
- mask:在Attention之前需要创建mask
- reps = self.tanh(reps):实现第四行公式
- 根据公式和代码可以判断使用的是点积注意力机制。
def attention_layer(self, h, mask):
att_weight = self.att_weight.expand(mask.shape[0], -1, -1) # B*H*1
att_score = torch.bmm(self.tanh(h), att_weight) # B*L*H * B*H*1 -> B*L*1
# mask, remove the effect of 'PAD'
mask = mask.unsqueeze(dim=-1) # B*L*1
att_score = att_score.masked_fill(mask.eq(0), float('-inf')) # B*L*1
att_weight = F.softmax(att_score, dim=1) # B*L*1
reps = torch.bmm(h.transpose(1, 2), att_weight).squeeze(dim=-1) # B*H*L * B*L*1 -> B*H*1 -> B*H
reps = self.tanh(reps) # B*H
return reps
5. 训练
训练参数
epoch = 20 # 默认是30,考虑到训练时长,改为了20
batch_size = 10
lr = 1.0
max_len = 100
emb_dropout = 0.3
lstm_dropout = 0.3
linear_dropout = 0.5
hidden_size = 100
layers_num = 1
L2_decay = 1e-05
device = cpu
训练效果
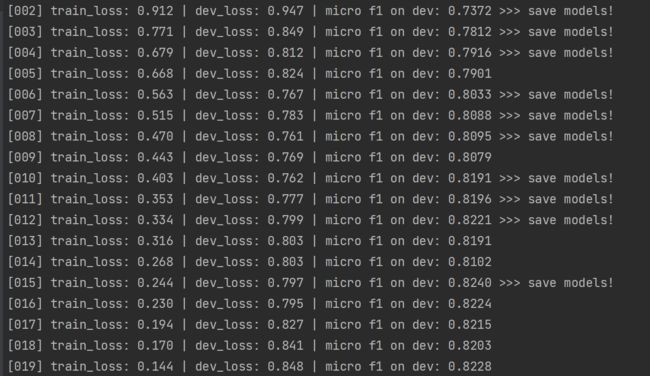
训练好的模型保存在目录output中,20个epoch训练时长约为4个小时。
6. 测试
- 先执行:
python run.py --mode=0 # 测试
- test的预测结果将保存在 predicted_result.txt中,semeval_scorer函数将会完成F1值的计算,测试结束后控制台会直接打出F1=0.824

- 除了用python代码来计算精度之外官方还提供了基于perl的工具(windows电脑需要安装perl环境),执行下面这行代码,计算结果将被保存在result.txt中,F1计算结果与直接用python计算的结果一致。
perl semeval2010_task8_scorer-v1.2.pl proposed_answer.txt predicted_result.txt >> result.txt
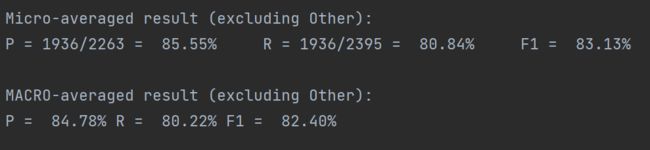
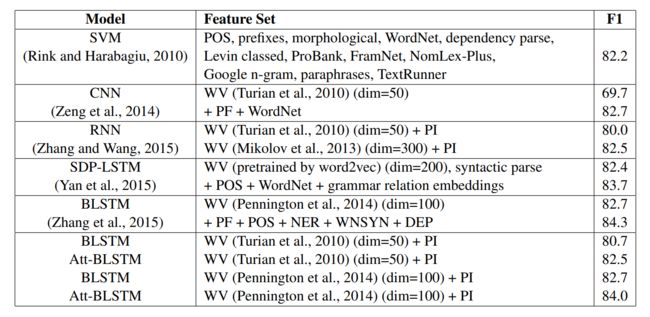
下图最后一行是论文中作者的实验结果,与我的训练结果基本相同。
okok NLP的所有大作业终于是完成了,一共训了5个模型,虽然每一个都有不少疑问,但是到第五个的时候已经游刃有余了,表扬自己的进步,并祝大家圣诞快乐!⛄⛄