python数据分析 - 关联规则Apriori算法
关联规则Apriori算法
- 导语
- mlxtend实现Apriori算法
导语
关联规则:
是反映一个事物与其他事物之间的相互依存性和关联性
常用于实体商店或在线电商的推荐系统:通过对顾客的购买记录数据库进行关联规则挖掘,最终目的是发现顾客群体的购买习惯的内在共性,例如购买产品A的同时也连带购买产品B的概率,根据挖掘结果,调整货架的布局陈列、设计促销组合方案,实现销量的提升,最经典的应用案例莫过于<啤酒和尿布>。关联规则分析中的关键概念包括:支持度(Support)、置信度(Confidence)与提升度(Lift)。
支持度(support)
支持度 (Support)支持度是两件商品 ( X ⋂ Y ) (X \bigcap Y) (X⋂Y)在总销售笔数(N)中出现的概率,即A与B同时被购买的概率
S u p p o r t ( X ⋂ Y ) = F r e q ( X ⋂ Y ) N Support(X \bigcap Y)=\frac{Freq(X \bigcap Y)}{N} Support(X⋂Y)=NFreq(X⋂Y)
举例说明:
比如某超市2016年有100w笔销售,顾客购买可乐又购买薯片有20w笔,顾客购买可乐又购买面包有10w笔
- 可乐和薯片的关联规则的支持度是:20%
- 可乐和面包的支持度是10%
置信度(confidence)
置信度是购买X后再购买Y的条件概率。简单来说就是交集部分Y在X中比例,如果比例大说明购买X的客户很大期望会购买Y商品
C o n f i d e n c e = F r e q ( X ⋂ Y ) F r e q ( X ) Confidence=\frac{Freq(X \bigcap Y)}{Freq (X)} Confidence=Freq(X)Freq(X⋂Y)
举例说明:
某超市2016年可乐购买次数40w笔,购买可乐又购买了薯片是30w笔,顾客购买可乐又购买面包有10w笔
- 购买可乐又会购买薯片的置信度是75%
- 购买可乐又购买面包的置信度是25%
提升度(lift)
提升度表示先购买X对购买Y的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率
L i f t = S u p p o r t ( X ⋂ Y ) S u p p o r t ( X ) ∗ S u p p o r t ( Y ) Lift=\frac{Support(X \bigcap Y)}{Support(X)*Support(Y)} Lift=Support(X)∗Support(Y)Support(X⋂Y)
举例说明:
可乐和薯片的关联规则的支持度是20%,购买可乐的支持度是3%,购买薯片的支持度是5%
- 提升度是1.33
{X→Y}的提升度大于1,这表示如果顾客购买了商品X,那么可能也会购买商品Y;而提升度小于1则表示如果顾客购买了商品X,那么不太可能再购买商品Y
有这三个指标,如何选择商品的组合,是需要对支持度,置信度,提升度综合指标来看待商品组合。没有固定的数值衡量
mlxtend实现Apriori算法
数据集选择:Grocery Store Data Set
数据集为10000多个购买商品的订单。该数据集包含11商品:果酱、麦琪、糖、咖啡、奶酪、茶、波恩维塔、玉米片、面包、饼干和牛奶。
import pandas as pd
data=pd.read_csv('GroceryStoreDataSet.csv',names=['products'],header=None)
data.head(10)

data=list(data['products'].apply(lambda x:x.split(',')))
data

转换数据类型TransactionEncoder类似于独热编码,每个值转换为一个唯一的bool值)
from mlxtend.preprocessing import TransactionEncoder
d=TransactionEncoder()
d_data=d.fit(data).transform(data)
df=pd.DataFrame(d_data,columns=d.columns_)
df
TransactionEncoder类似于独热编码,每个值转换为一个唯一的bool值)
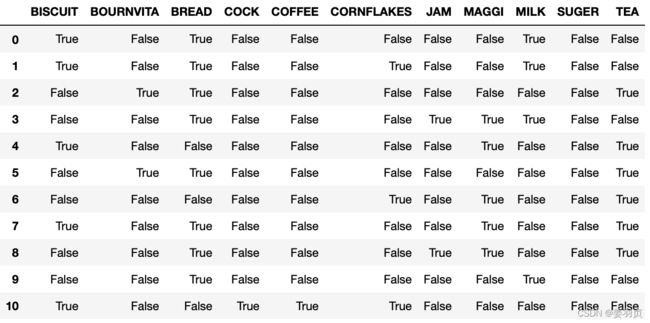
求支持度
from mlxtend.frequent_patterns import apriori
df1=apriori(df,min_support=0.01,use_colnames=True)
df1.sort_values(by='support',ascending=False)

求置信度与提升度
association_rules方法判断置信度,这里提取confidence大于0.9的
from mlxtend.frequent_patterns import association_rules
association_rule = association_rules(df1,metric='confidence',min_threshold=0.9)
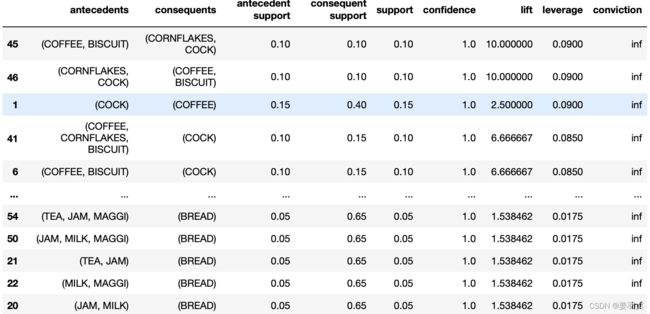
列中的columns参数含义如下:
- antecedents:商品X组合
- consequents:商品Y组合
购买关联的关系是{X -> Y} - antecedent support:商品X组合支持度
- consequent support:商品Y组合支持度
- support:{X -> Y}支持度
- confidence:{X -> Y}置信度
- lift:{X -> Y}提升度
- leverage:规则杠杆率,表示当商品X组合与商品Y组合独立分布时,商品X组合与商品Y组合一起出现的次数比预期多多少。
- conviction:{X -> Y}确信度,与提升度类似,但用差值表示。
确信度值越大,则商品X组合与商品Y组合的关联性越强。 以上三个值都是越大关联强度也就越大,inf表示无穷大。
注意是商品组合
单个商品与单个商品之间的关系
筛选商品组合,选出只有一个商品的antecedents,和consequents。
association_rule['X_length']=association_rule['antecedents'].apply(lambda x:len(x))
association_rule['Y_length']=association_rule['consequents'].apply(lambda x:len(x))
association_rule=association_rule[(association_rule['X_length']==1) & (association_rule['Y_length']==1) ]

也可以单独对antecedents的商品组合,分析,观察antecedent support值,找出关联性最大的情况