Spring Cloud 快速入门(七)调用链跟踪 Spring Cloud Sleuth + Zipkin
调用链跟踪 Spring Cloud Sleuth + zipkin
调用链跟踪产品:
Google—Dapper
淘宝-鹰眼-Eagleeye
京东-Hydra
大众点评-cat
新浪-watchman
唯品会-microscope
Twitter-Zipkin
1. Sleuth 简介
打开官网就可以看到对 Sleuth 的一个简单功能介绍。

【翻译】(Spring Cloud Sleuth可以实现)针对Spring Cloud应用程序的分布式跟踪,兼容Zipkin、HTrace 和基于日志的(如 Elk)跟踪。

【翻译】Spring Cloud Sleuth 为 Spring Cloud 实现了一个分布式跟踪解决方案,大量借鉴了Dapper、Zipkin 和 HTrace。对于大多数用户来说,Sleuth 是不可见的,并且你的当前应用与外部系统的所有交互都是自动检测的。你可以简单地在日志中捕获数据,或者将其发送到远程收集器中。
Sleuth 作为日志生成器
Zipkin 作为日志收集器
2. Sleuth 基本理论
2.1 Spring Cloud Sleuth 文档
Spring Cloud Sleuth 的官方文档中可以查看到服务跟踪的基本理论。
2.2 三大概念
服务跟踪理论中存在有跟踪单元的概念,而跟踪单元中涉及三个重要概念:trace、span,与 annotation。
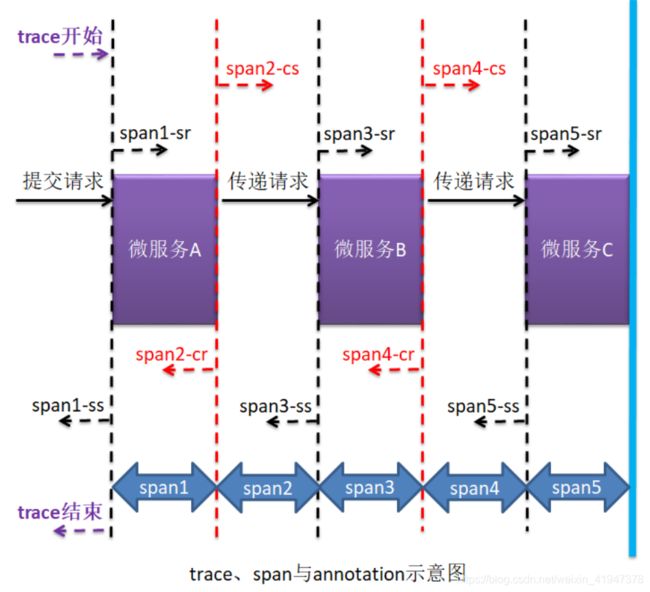
(1) trace 与 span
- trace:跟踪单元是从客户端所发起的请求抵达被跟踪系统的边界开始,到被跟踪系统向客户返回响应为止的过程,这个过程称为一个 trace。
- span:每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用所消耗的时间等信息,在每次调用服务时,埋入一个调用记录,这样两个调用记录之间的区域称为一个 span。
- 关系:一个 trace 由若干个有序的 span 组成。
Spring Cloud Sleuth 为服务之间调用提供链路追踪功能。为了唯一标识 trace 与 span,系统为每个 trace 与 span 都指定了一个 64 位长度的数字作为 ID,即 traceID 与 spanID。
(2) annotation
Spring Cloud Sleuth 中有三个重要概念,除了 trace、span 外,还有一个就是 annotation。但需要注意,这个 annotation 并不是我们平时代码中写的@开头的注解,而是这里的一个专有名词,用于及时记录事件的实体,表示一个事件发生的时间点。这些实体本身仅仅是为了原理叙述的方便,对于 Spring Cloud Sleuth 本身并没有什么必要性。这样的实体有多个,常用的有四个:
- cs:Client Send,表示客户端发送请求的时间点。
- sr:Server Receive,表示服务端接收到请求的时间点。
- ss:Server Send,表示服务端发送响应的时间点。
- cr:Client Receive,表示客户端接收到服务端响应的时间点。
比如:
- span5-ss 减去 span5-sr:代表了当前请求在微服务C这运算了多长时间
- span3-ss 减去 span3-sr:代表了当前请求在微服务B这运算了多长时间,肯定是包含微服务C的处理时间
- span4-cr 减去 span5-ss:代表了响应在网络上传输的时间
- span5-sr 减去 span4-cs:代表了请求在网络上传输的时间
- …可以算出很多信息

2.3 Sleuth 的日志采样
(1) 日志生成
只要在工程中添加了 Spring Cloud Sleuth 依赖, 那么工程在启动与运行过程中就会自动生成很多的日志。Sleuth 会为日志信息打上收集标记,需要收集的设置为 true,不需要的设置为 false。这个标记可以通过在代码中添加自己的日志信息看到。

(2) 日志采样率
Sleuth 对于这些日志支持抽样收集,即并不是所有日志都会上传到日志收集服务器,日志收集标记就起这个作用。默认的采样比例为: 0.1,即 10%。在配置文件中可以修改该值。若设置为 1 则表示全部采集,即 100%。
日志采样默认使用的是的水塘抽样算法(统计学)。
3. “跟踪日志”的生产者 Sleuth
3.1 创建提供者工程 07-sleuth-provider-8081
(1) 创建工程
复制第二章的 02-provider-8081,并重命名为 07-sleuth-provider-8081。
重命名启动类ApplicationSleuthProvider8081。
(2) 导入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
(3) 修改处理器
如果有需要的话,可以在业务代码中添加自己的跟踪日志信息。

@Slf4j //lombok
@RestController
@RequestMapping("/provider/depart")
public class DepartController {
@Autowired
private DepartService service;
// 声明服务发现客户端
@Autowired
private DiscoveryClient client;
...
@GetMapping("/get/{id}")
public Depart getHandler(@PathVariable("id") Integer id) {
log.info("调用provider的getDepartById()方法");
return service.getDepartById(id);
}
...
}
(4) 修改配置文件
将配置文件中原有的有关日志的配置删除,否则看不到后面的演示结果。(我们希望看到info级别的日志)

server:
port: 8081
spring:
jpa:
generate-ddl: true
show-sql: true
hibernate:
ddl-auto: none
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql:///test?useUnicode=true&;characterEncoding=utf8
username: root
password: 111
application:
name: abcmsc-provider-depart
eureka:
client:
service-url:
defaultZone: http://localhost:8000/eureka
3.2 创建消费者工程 07-sleuth-consumer-8080
(1) 创建工程
复制 02-consumer-8080,并重命名为 07-sleuth-consumer-8080。
重命名启动类ApplicationSleuthConsumer8080。
(2) 导入依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-sleuthartifactId>
dependency>
(3) 修改处理器
@Slf4j
@RestController
@RequestMapping("/consumer/depart")
public class SomeController {
@Autowired
private RestTemplate restTemplate;
// 要使用微服务名称来从eureka server查找提供者
private static final String SERVICE_PROVIDER = "http://abcmsc-provider-depart";
...
@GetMapping("/get/{id}")
public Depart getByIdHandler(@PathVariable("id") int id) {
log.info("调用consumer的getByIdHandler()方法");
String url = SERVICE_PROVIDER + "/provider/depart/get/" + id;
return restTemplate.getForObject(url, Depart.class);
}
...
}
3.3 演示
调用get方法后查看日志:
trace开始的时候第一个spanId和traceId一致
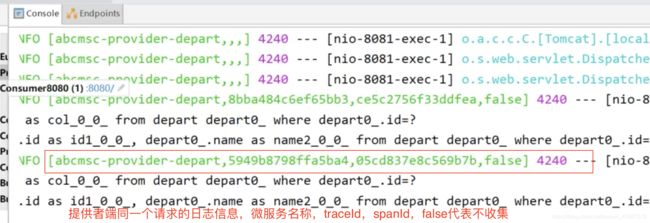
可以看到traceId是一致的。
4. zipkin 工作过程
4.1 zipkin 简介
zipkin 是 Twitter 开发的一个分布式系统 APM(Application Performance Management,应用性能管理)工具,其是基于 Google Dapper 实现的,用于完成日志的聚合。其与 Sleuth 联用,可以为用户提供调用链路监控可视化 UI 界面。
4.2 zipkin 系统结构
(1) 服务器组成

zipkin 服务器主要由 4 个核心组件构成:
- Collector:收集组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要用于处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,也可以修改存储策略,例如,将跟踪信息存储到数据库中。
- API:外部访问接口组件,外部系统通过这里的 API 可以实现对系统的监控。
- UI:用于操作界面组件,基于 API 组件实现的上层应用。通过 UI 组件用户可以方便而又直观地查询和分析跟踪信息。
(2) 日志发送方式
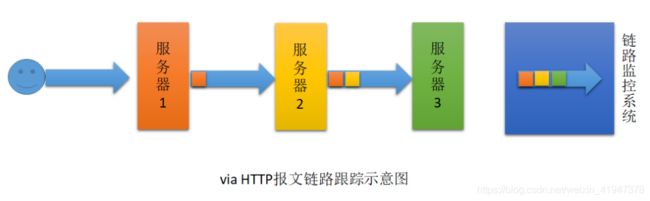
在 Spring Cloud Sleuth + Zipkin 系统中,客户端中一旦发生服务间的调用,就会被配置在微服务中的 Sleuth 的监听器监听,然后生成相应的 Trace 和 Span 等日志信息,并发送给 Zipkin 服务端。发送的方式主要有两种,一种是通过 via HTTP 报文的方式,也可以通过 Kafka、RabbitMQ 发送。
via HTTP 报文的方式原理:
用户请求服务器1,服务器1请求服务器2时,会在请求头中添加via请求头,把当前服务器信息添加到via头部,紧接着经过服务器2,又把服务器2的信息添加到via请求头中,经过服务器3把服务器3的的信息添加到via头中,到达链路监控系统时,链路监控系统就会对请求头部via进行解析,就可以知道请求经过各个服务器的信息,进行统计计算
缺点:
- 头部越来越沉
- 高并发情况下效率很低
消息队列方式:
每个服务器处理请求的时候立即将请求信息发送到Kafka,可以及时看到请求在各个服务器上的情况
不需要等请求最终到了链路监控系统以后,才能知道之前经过的各个服务器上的情况

4.3 zipkin 服务端搭建
4.5.1 启动 zipkin 服务器

(1) 下载
(2) 启动

4.5.2 访问 zipkin 服务器
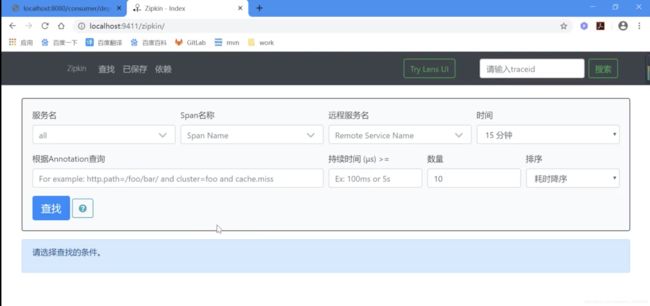
4.4 创建 zipkin 客户端工程 - via HTTP方式
4.4.1 总步骤
- 导入 zipkin 客户端依赖
- 在配置文件中指定 zipkin 服务器地址,并设置 Sleuth 采样率
4.4.2 创建提供者 07-via-provider-8081
(1) 创建工程
复制 07-sleuth-provider-8081,并重命名为 07-via-provider-8081。
修改启动类类名ApplicationViaProvider8081。
(2) 导入依赖
删除原来的 sleuth 依赖,导入 zipkin 依赖。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
打开 spring-cloud-starter-zipkin 依赖,可以看到其已经包含了 spring-cloud-starter-sleuth依赖,所以可以将原来导入的 sleuth 依赖删除。
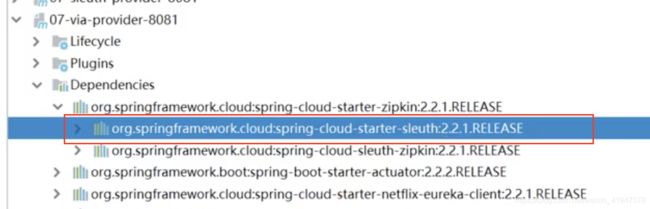
(3) 修改配置文件
在 spring 属性下注册 zipkin 服务器地址,并设置采样比例。

server:
port: 8081
spring:
jpa:
generate-ddl: true
show-sql: true
hibernate:
ddl-auto: none
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql:///test?useUnicode=true&;characterEncoding=utf8
username: root
password: 111
application:
name: abcmsc-provider-depart
# 指定zipkin服务器地址
zipkin:
base-url: http://localhost:9411/
# 设置采样比例为1.0,即全部都需要,默认0.1
sleuth:
sampler:
probability: 1.0
eureka:
client:
service-url:
defaultZone: http://localhost:8000/eureka
4.4.3 创建消费者工程 07-via-consumer-8080
(1) 创建工程
复制 07-sleuth-consumer-8080,并重命名为 07-via-consumer-8080。
修改启动类类名ApplicationViaConsumer8080。
(2) 导入依赖
删除原来的 sleuth 依赖,导入 zipkin 依赖。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
(3) 修改配置文件
在 spring 属性下注册 zipkin 服务器地址,并设置采样比例。
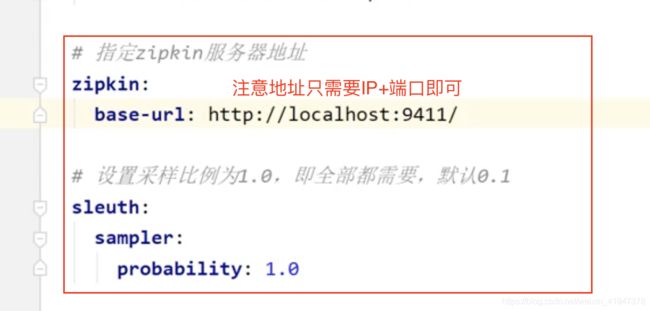
spring:
application:
name: abcmsc-consumer-depart
# 指定zipkin服务器地址
zipkin:
base-url: http://localhost:9411/
# 设置采样比例为1.0,即全部都需要,默认0.1
sleuth:
sampler:
probability: 1.0
eureka:
client:
service-url:
defaultZone: http://localhost:8000/eureka
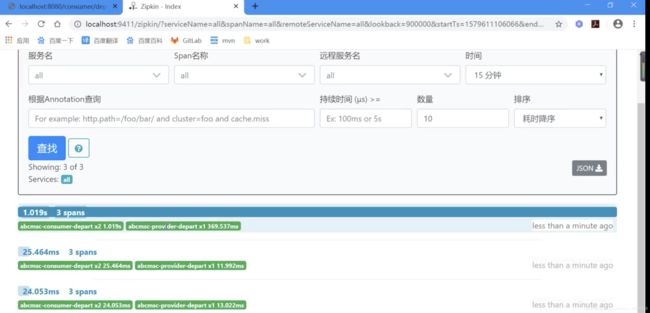
4.4.4 演示效果
-
先调用请求:

-
调用3次后访问zipkin:
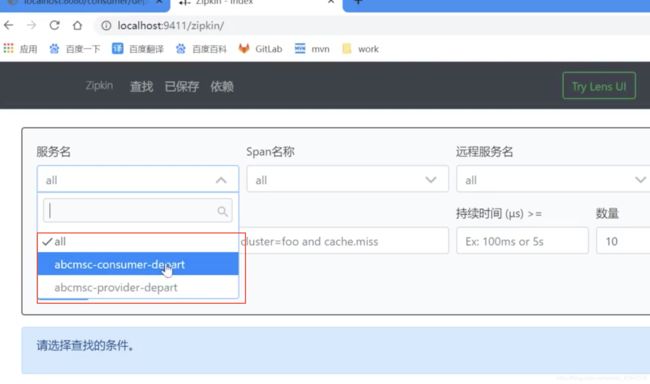
-
点击查询:
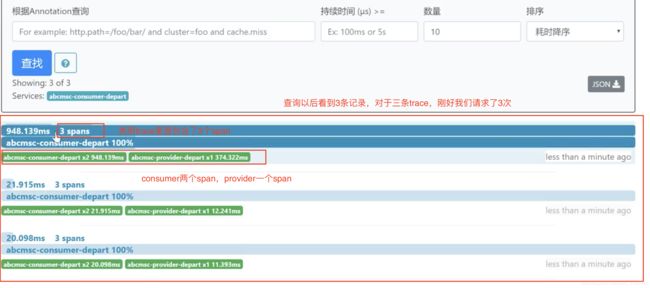
consumer两个span,provider一个span,对应图中:

-
选择一个点击进去
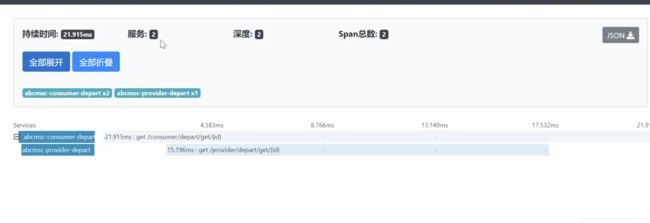

4.5 sleuth + kafka + zipkin
默认情况下,Sleuth 是通过将调用日志写入到 via 头部信息中的方式实现链路跟踪的,但在高并发下,这种方式的效率会非常低,会影响链路信息查看的。此时,可以让 Sleuth将其生成的调用日志写入到 Kafka 或 RabbitMQ 中,让 zipkin 从这些中间件中获取日志,效率会提高很多。

总步骤
- 导入 kafka 依赖,注意仍需保留 zipkin 客户端依赖
- 在配置文件中指定要连接的 kafka 集群,并指定 zipkin 服务器的日志发送者是 kafka
4.5.1 创建提供者工程 07-kafka-provider-8081
(1) 创建工程
复制 07-sleuth-provider-8081,并重命名为 07-kafka-provider-8081。
修改启动类类名ApplicationKafkaProvider8081。
(2) 导入依赖
添加 kafka 依赖。
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
(3) 修改配置文件
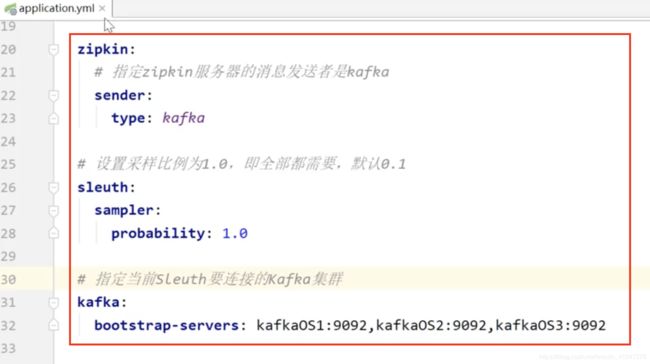
server:
port: 8081
spring:
jpa:
generate-ddl: true
show-sql: true
hibernate:
ddl-auto: none
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql:///test?useUnicode=true&;characterEncoding=utf8
username: root
password: 111
application:
name: abcmsc-provider-depart
zipkin:
# 指定zipkin服务器的消息发送者是kafka
sender:
type: kafka
# 设置采样比例为1.0,即全部都需要,默认0.1
sleuth:
sampler:
probability: 1.0
# 指定当前Sleuth要连接的Kafka集群
kafka:
bootstrap-servers: kafkaOS1:9092,kafkaOS2:9092,kafkaOS3:9092
eureka:
client:
service-url:
defaultZone: http://localhost:8000/eureka
4.5.2 创建消费者工程 07-kafka-consumer-8080
(1) 创建工程
复制 07-via-consumer-8080,并重命名为 07-kafka-consumer-8080。
修改启动类类名ApplicationKafkaConsumer8080。
(2) 导入依赖
添加 kafka 依赖。
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
(3) 修改配置文件
spring:
application:
name: abcmsc-consumer-depart
# 指定zipkin服务器地址
zipkin:
# 指定zipkin服务器的消息发送者是kafka
sender:
type: kafka
# 设置采样比例为1.0,即全部都需要,默认0.1
sleuth:
sampler:
probability: 1.0
# 指定当前Sleuth要连接的Kafka集群
kafka:
bootstrap-servers: kafkaOS1:9092,kafkaOS2:9092,kafkaOS3:9092
eureka:
client:
service-url:
defaultZone: http://localhost:8000/eureka
4.5.3 启动运行
(1) zookeeper启动(kafka 依赖 zk)
略
(2) kafka 集群启动
略
(3) zipkin 启动
在命令行启动 zipkin
java -DKAFKA_BOOTSTRAP_SERVERS=kafkaOS1:9092 –jar zipkin.jar

(4) 启动应用
- 启动 Eureka
- 启动提供者工程 07-kafka-provider-8081
- 启动消费者工程 07-kafka-consumer-8080
(5) 效果