用于缺陷检测的高分辨率图像的切片处理——工作总结
目录
- 参考
- 背景
- 原理
-
- 切片
- 标签映射
- 代码
- 结果
- 切片检测结果映射回原图
- LabelImg的使用
-
- 安装
- 运行
- 标注
- 总结
参考
[1] https://blog.csdn.net/zengwubbb/article/details/115800477
背景
当样本图像分辨率高(就是像素点很多很多),且图像中待检测目标非常小的情况下:
- 如果reshape成小图再送进网络训练的话,目标会变得更加小,甚至reshape没了,检测难度大或根本检测不出来;
- 直接对大图训练又会导致训练时间非常慢甚至GPU out of memory。
原理
切片
在切片时有overlap(重叠区域)的概念,即相邻两个切片中间有一部分重叠区域,如对于分辨率5000×5000的图像,假设切片大小为640×640,重叠区域长度为28,则每次切片移动512,如下图:
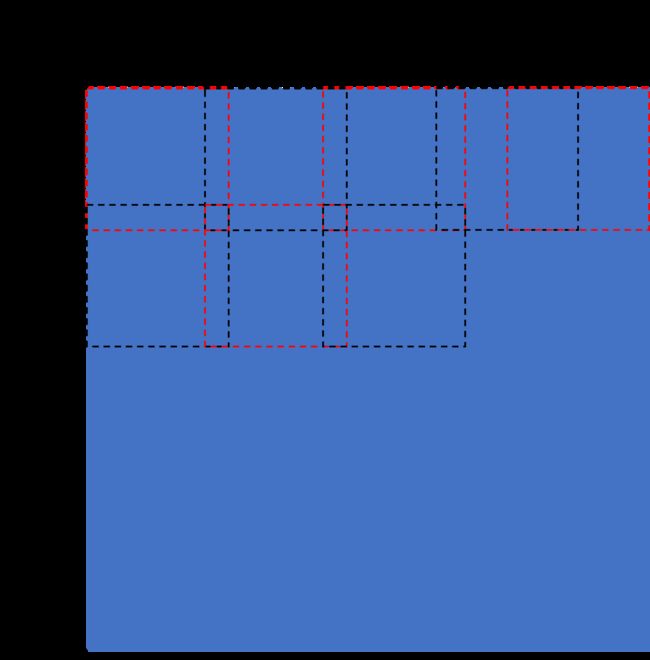
如上图,为了避免最右侧的切片超出图片像素范围,应对overlap进行调整,即取5000-640
标签映射
图像中的标签和切片区域存在以下9种关系(这里当然不考虑标签不在切片区域内的情况)
红色为标签,蓝色为切片区域

每个切片只保留在其上的标签区域:

代码
切片操作代码见参考链接,这里不附了。
下面是将xml文件中的object写入(画入)图片中的代码:
import xml.etree.ElementTree as ET
import os, cv2
from tqdm import tqdm
annota_dir = './xml/'
img_dir = './image/'
def divide_img(oriname):
#print(oriname)
img_file = os.path.join(img_dir, oriname + '.bmp')
im = cv2.imread(img_file)
xml_file = os.path.join(annota_dir, oriname + '.xml') # 读取每个原图像的xml⽂件
tree = ET.parse(xml_file)
root = tree.getroot()
#im = cv2.imread(imgfile)
for object in root.findall('object'):
object_name = object.find('name').text
Xmin = int(object.find('bndbox').find('xmin').text)
Ymin = int(object.find('bndbox').find('ymin').text)
Xmax = int(object.find('bndbox').find('xmax').text)
Ymax = int(object.find('bndbox').find('ymax').text)
color = (4, 250, 7)
cv2.rectangle(im, (Xmin, Ymin), (Xmax, Ymax), color, 2)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(im, object_name, (Xmin, Ymin - 7), font, 0.5, (6, 230, 230), 2)
cv2.imshow('01', im)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('./label_img/'+oriname+'.bmp',im)
#img_name = oriname + '.jpg'
#to_name = os.path.join(target_dir1, img_name)
#cv2.imwrite(to_name, im)
img_list = os.listdir(img_dir)
for name in img_list:
divide_img(name.rstrip('.bmp'))
结果
这里只保留含有标签的切片
因为有overlap的存在所以会出现两个切片都包含同一个标签的情况。
切片检测结果映射回原图
思路

代码
### 将切片的检测结果映射到原图
#思路:
#1.首先对原图进行切片,切片名称中保留切片的位置信息
#2.切片丢去检测
#3.显示切片的检测结果再映射回原图
import os
from tqdm import tqdm
import cv2
import codecs
import xml.etree.ElementTree as ET
import numpy as np
#实现功能:将图片切片
def im_slice (img_dir,save_dir,sliceHeight = 640,sliceWidth = 640,overlap = 0.2): #overlap是重叠比率
for per_img_name in tqdm(os.listdir(img_dir)):
cnt = 0
o_name, _ = os.path.splitext(per_img_name) # 分离文件名和扩展名
image_path = os.path.join(img_dir, per_img_name) # 图片路径
image0 = cv2.imread(image_path, 1) # color 1表示读彩色图,这里也可以直接写cv2.IMREAD_COLOR
ext = '.' + image_path.split('.')[-1] # 取图片的扩展名
win_h, win_w = image0.shape[:2] # 图片的高和宽
# 避免出现切图的大小比原图还大的情况
pad = 0
if sliceHeight > win_h:
pad = sliceHeight - win_h
if sliceWidth > win_w:
pad = max(pad, sliceWidth - win_w)
# pad the edge of the image with black pixels
if pad > 0:
border_color = (0, 0, 0)
image0 = cv2.copyMakeBorder(image0, pad, pad, pad, pad,
cv2.BORDER_CONSTANT, value=border_color)
#win_size = sliceHeight * sliceWidth
dx = int((1. - overlap) * sliceWidth)
dy = int((1. - overlap) * sliceHeight)
slice_y_num = 0
for y0 in range(0, image0.shape[0], dy):
slice_x_num = 0
for x0 in range(0, image0.shape[1], dx):
if y0 + sliceHeight > image0.shape[0]:
y = image0.shape[0] - sliceHeight
else:
y = y0
if x0 + sliceWidth > image0.shape[1]:
x = image0.shape[1] - sliceWidth
else:
x = x0
window_c = image0[y:y + sliceHeight, x:x + sliceWidth]
outpath = os.path.join(save_dir,
o_name +'_'+str(slice_y_num)+ '_'+str(slice_x_num) +'_'+ str(y) + '_' + str(x) + '_' + str(sliceHeight) + '_' + str(
sliceWidth) + '_' + str(pad) + '_' + str(win_w) + '_' + str(win_h) + ext)
cv2.imwrite(outpath, window_c)
slice_x_num +=1
slice_y_num +=1
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def xml_transfer(img_dir,xml_save_dir,slice_xml_dir):
for img in os.listdir(img_dir):
img_name,img_ext = os.path.splitext(img)
object_list = []
for xml_name in os.listdir(slice_xml_dir):
if xml_name.split('_')[0]==img_name:
label_ext = xml_name.split('.')[-1]
index_x = xml_name.split('_')[1] #是第几张切片
index_y = xml_name.split('_')[2]
tree = ET.parse(os.path.join(slice_xml_dir,xml_name))
root = tree.getroot()
for obj in root.findall('object'):
x0 = int(xml_name.split('_')[4])
y0 = int(xml_name.split('_')[3])
# 取出检测框类别名称
category = get_and_check(obj, 'name', 1).text
# 更新类别ID字典
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(get_and_check(bndbox, 'xmin', 1).text) + x0
ymin = int(get_and_check(bndbox, 'ymin', 1).text) + y0
xmax = int(get_and_check(bndbox, 'xmax', 1).text) + x0
ymax = int(get_and_check(bndbox, 'ymax', 1).text) + y0
assert (xmax > xmin)
assert (ymax > ymin)
obj_info = [xmin, ymin, xmax, ymax, category]
object_list.append(obj_info)
if object_list != []:
img0 = cv2.imread(os.path.join(img_dir,img))
h,w = img0.shape[:2]
with codecs.open(os.path.join(xml_save_dir, img_name + '.'+label_ext), 'w', 'utf-8') as xml:
xml.write('\n' )
xml.write('\t' + img_name+'.'+img_ext + '\n')
xml.write('\t\n' )
xml.write('\t\t' + str(w) + '\n')
xml.write('\t\t' + str(h) + '\n')
xml.write('\t\t' + str(3) + '\n')
xml.write('\t\n')
cnt = 0
for obj in object_list:
bbox = obj[:4]
class_name = obj[-1]
xmin, ymin, xmax, ymax = bbox
xml.write('\t)
xml.write('\t\t' + class_name + '\n')
xml.write('\t\t\n' )
xml.write('\t\t\t' + str(int(xmin)) + '\n')
xml.write('\t\t\t' + str(int(ymin)) + '\n')
xml.write('\t\t\t' + str(int(xmax)) + '\n')
xml.write('\t\t\t' + str(int(ymax)) + '\n')
xml.write('\t\t\n')
xml.write('\t\n')
cnt+=1
assert cnt > 0
xml.write('')
test_img_dir = './image/'
test_label_dir = './test_label_img/'
test_xml_dir = './test_img_xml/'
slice_label_dir = './slice_label_img/'
slice_img_dir = './slice_img/'
slice_xml_dir = './slice_img_xml/'
if not os.path.exists(slice_img_dir):
os.makedirs(slice_img_dir)
if not os.path.exists(test_label_dir):
os.makedirs(test_label_dir)
if not os.path.exists(test_xml_dir):
os.makedirs(test_xml_dir)
if __name__ == "__main__":
im_slice(test_img_dir, slice_img_dir,sliceHeight = 1280,sliceWidth = 1280)
xml_transfer(test_img_dir, test_xml_dir, slice_xml_dir)
LabelImg的使用
安装
直接在cmd中输入以下代码
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
运行
直接在cmd输入labelimg
标注

- 1处打开待标注图片所在文件夹
- 2处选择标注文件的格式,有三种
- VOC标签格式,保存为xml文件;
- yolo标签格式,保存为txt文件;
- createML标签格式,保存为json格式;
- 3处进行标注
- 4处保存标注文件
有一些快捷键:
| 快捷键 | 功能 |
|---|---|
| Ctrl + u | 加载标注图片路径 |
| Ctrl + r | 更改标注结果文件路径 |
| Ctrl + s | 保存 |
| Ctrl + d | 拷贝标注框标签 |
| Space | 将当前图像标记为已验证 |
| w | 创建框 |
| d | 下一张图片 |
| a | 上一张图片 |
| del | 删除选定的框 |
| Ctrl++ | 放大 |
| Ctrl– | 缩小 |
| ↑→↓← | 键盘箭头微调框 |
总结
- 高分辨率图像的切片处理对于目标检测算法非常重要,可以起到提高检测效率和检测精度的作用;