隐马尔可夫模型 (hidden Markov model, HMM)
- 本文为《统计学习方法》的读书笔记
目录
- 隐马尔可夫模型的基本概念
-
- 隐马尔可夫模型的定义
- 观测序列的生成过程
- 隐马尔可夫模型的 3 个基本问题
- 概率计算算法
-
- 直接计算法
- 前向算法 (forward algorithm)
- 后向算法 (backward algorithm)
- 一些概率与期望值的计算
- 学习算法
-
- 监督学习方法
- Baum-Welch 算法 (无监督学习方法)
- 预测算法
-
- 近似算法
- 维特比算法 (Viterbi algorithm)
隐马尔可夫模型的基本概念
隐马尔可夫模型的定义
- 隐马尔可夫模型是关于时序的概率模型。它描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列 (state sequence), 再由各个状态生成一个观测从而产生观测随机序列 (observation sequence) 的过程。序列的每一个位置可以看作是一个时刻
- 隐马尔可夫模型属于生成模型,表示状态序列和观测序列的联合分布,但是状态序列是隐藏的,不可观测的
隐马尔可夫模型的形式定义
- 隐马尔可夫模型由初始概率分布、状态转移概率分布以及观测概率分布确定
- 设 Q Q Q 是所有可能的状态的集合, V V V 是所有可能的观测的集合:
 I I I 是长度为 T T T 的状态序列, O O O 是对应的观测序列:
I I I 是长度为 T T T 的状态序列, O O O 是对应的观测序列:
 A A A 是状态转移概率矩阵:
A A A 是状态转移概率矩阵:
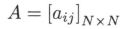 其中, a i j a_{ij} aij 是在时刻 t t t 处于状态 q i q_i qi 的条件下在时刻 t + 1 t+1 t+1 转移到状态 q j q_j qj 的概率
其中, a i j a_{ij} aij 是在时刻 t t t 处于状态 q i q_i qi 的条件下在时刻 t + 1 t+1 t+1 转移到状态 q j q_j qj 的概率
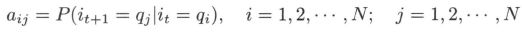 B B B 是观测概率矩阵:
B B B 是观测概率矩阵:
 其中, b j ( k ) b_j(k) bj(k) 是在时刻 t t t 处于状态 q j q_j qj 的条件下生成观测 v k v_k vk 的概率
其中, b j ( k ) b_j(k) bj(k) 是在时刻 t t t 处于状态 q j q_j qj 的条件下生成观测 v k v_k vk 的概率
 π \pi π 是初始状态概率向量:
π \pi π 是初始状态概率向量:
 其中, π i \pi_i πi 是时刻 t = 1 t=1 t=1 处于状态 q i q_i qi 的概率
其中, π i \pi_i πi 是时刻 t = 1 t=1 t=1 处于状态 q i q_i qi 的概率
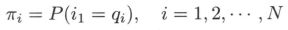
- 隐马尔可夫模型由初始状态概率向量 π \pi π、状态转移概率矩阵 A A A 和观测概率矩阵 B B B 决定。因此,隐马尔可夫模型 λ λ λ 可以用三元符号表示,即
 状态转移概率矩阵 A A A 与初始状态概率向量 π \pi π 确定了隐藏的马尔可夫链,生成不可观测的状态序列。观测概率矩阵 B B B 确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列
状态转移概率矩阵 A A A 与初始状态概率向量 π \pi π 确定了隐藏的马尔可夫链,生成不可观测的状态序列。观测概率矩阵 B B B 确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列
隐马尔可夫模型的两个基本假设
- (1) 齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻 t t t 的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻 t t t 无关:

- (2) 观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关:
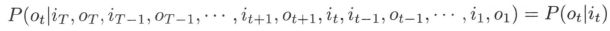
例

观测序列的生成过程

隐马尔可夫模型的 3 个基本问题
- (1) 概率计算问题: 给定模型 λ = ( A , B , π ) λ = (A ,B, π) λ=(A,B,π) 和观测序列 O = ( o 1 , . . . , o T ) O= (o_1 ,...,o_T) O=(o1,...,oT),计算在模型 λ λ λ 下观测序列 O O O 出现的概率 P ( O ∣ λ ) P(O| λ) P(O∣λ)
- (2) 学习问题。己知观测序列 O = ( o 1 , . . . , o T ) O= (o_1 ,...,o_T) O=(o1,...,oT) 估计模型 λ = ( A , B , π ) λ = (A ,B, π) λ=(A,B,π) 参数,使得在该模型下观测序列概率 P ( O ∣ λ ) P(O| λ) P(O∣λ) 最大。即用极大似然估计的方法估计参数
- (3) 预测问题 / 解码 (decoding) 问题。已知模型 λ = ( A , B , π ) λ = (A ,B, π) λ=(A,B,π) 和观测序列 O = ( o 1 , . . . , o T ) O= (o_1 ,...,o_T) O=(o1,...,oT) 求对给定观测序列条件概率 P ( I ∣ O ) P (I|O) P(I∣O) 最大的状态序列 I = ( i 1 , , . . . , i T ) I = (i_1, ,...,i_T ) I=(i1,,...,iT)。即给定观测序列,求最有可能的对应的状态序列
标注问题
- 隐马尔可夫模型可以用于标注。标注问题是给定观测的序列预测其对应的标记序列。可以假设标注问题的数据是由隐马尔可夫模型生成的。这样我们可以利用隐马尔可夫模型的学习与预测算法进行标注,即输入为观测序列,输出为标记序列 (状态序列)
概率计算算法
- 概率计算问题: 给定模型 λ = ( A , B , π ) λ = (A ,B, π) λ=(A,B,π) 和观测序列 O = ( o 1 , . . . , o T ) O= (o_1 ,...,o_T) O=(o1,...,oT),计算在模型 λ λ λ 下观测序列 O O O 出现的概率 P ( O ∣ λ ) P(O| λ) P(O∣λ)
直接计算法
- 最直接的方法是按概率公式直接计算。通过列举所有可能的长度为 T T T 的状态序列 I = ( i 1 , i 2 , . . . , i T ) ′ I = (i_1, i_2,... , i_T)' I=(i1,i2,...,iT)′,求各个状态序列 I I I 与观测序列 O = ( o 1 , o 2 , . . . , o T ) O= (o_1 ,o_2 ,...,o_T) O=(o1,o2,...,oT) 的联合概率 P ( O , I ∣ λ ) P(O ,I| λ) P(O,I∣λ),然后对所有可能的状态序列求和,得到 P ( O ∣ λ ) P(O| λ) P(O∣λ)

- 但显然,利用上式计算量很大,是 O ( T N T ) O(TN^T) O(TNT) 阶的,这种算法不可行
前向算法 (forward algorithm)


- 按照上面的算法可以递推地求得前向概率 α t ( i ) α_t (i) αt(i) 及观测序列概率 P ( O ∣ λ ) P(O| λ) P(O∣λ),计算量是 O ( N 2 T ) O(N^2 T) O(N2T) 阶的
后向算法 (backward algorithm)


- 按照上面的算法可以递推地求得后向概率 β t ( i ) \beta_t (i) βt(i) 及观测序列概率 P ( O ∣ λ ) P(O| λ) P(O∣λ),计算量是 O ( N 2 T ) O(N^2 T) O(N2T) 阶的
一些概率与期望值的计算
- 给定模型 λ λ λ 和观测 O O O,在时刻 t t t 处于状态 q i q_i qi 的概率。记
 由前向概率和后向概率定义可知:
由前向概率和后向概率定义可知:
 于是得到:
于是得到:
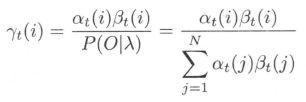
- 给定模型 λ λ λ 和观测 O O O,在时刻 t t t 处于状态 q i q_i qi 且在时刻 t + 1 t+1 t+1 处于状态 q j q_j qj 的概率。记
 可以通过前向后向概率计算:
可以通过前向后向概率计算:
 而
而
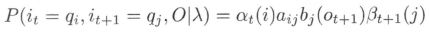 所以
所以

- 将 γ t ( i ) \gamma_t(i) γt(i) 和 ξ t ( i , j ) \xi_t(i,j) ξt(i,j) 对各个时刻 t t t 求和,可以得到一些有用的期望值
- (1) 在观测 O O O 下状态 i i i 出现的期望值:

- (2) 在观测 O O O 下由状态 i i i 转移的期望值:

- (3) 在观测 O O O 下由状态 i i i 转移到状态 j j j 的期望值:
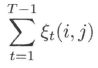
- (1) 在观测 O O O 下状态 i i i 出现的期望值:
学习算法
- 学习问题。己知观测序列 O = ( o 1 , . . . , o T ) O= (o_1 ,...,o_T) O=(o1,...,oT) 估计模型 λ = ( A , B , π ) λ = (A ,B, π) λ=(A,B,π) 参数,使得在该模型下观测序列概率 P ( O ∣ λ ) P(O| λ) P(O∣λ) 最大。即用极大似然估计的方法估计参数
- 如果训练数据除了观测序列,还包含状态序列,那么就可由监督学习实现;否则用无监督学习实现
监督学习方法
- 假设给训练数据包含 S S S 个长度相同的观测序列和对应的状态序列 { ( O 1 , I 1 ) , . . . , ( O S , I S ) } \{(O_1,I_1),...,(O_S, I_S)\} {(O1,I1),...,(OS,IS)}. 那么可以利用极大似然估计法来估计隐马尔可夫模型的参数
- (1) 转移概率 a i j a_{ij} aij 的估计: 设样本中时刻 t t t 处于状态 i i i 时刻 t + 1 t+1 t+1 转移到状态 j j j 的频数为 A i j A_{ij} Aij,那么状态转移概率 a i j a_{ij} aij 的估计是
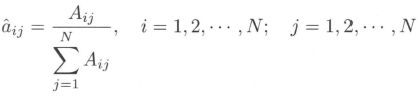
- (2) 观测概率 b j ( k ) b_j (k) bj(k) 的估计: 设样本中状态为 j j j 并观测为 k k k 的频数是 B j k B_{jk} Bjk,那么状态为 j j j 观测为 k k k 的概率 b j ( k ) b_j(k) bj(k) 的估计是
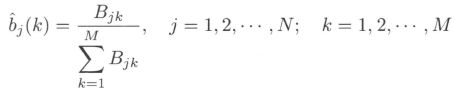
- (3) 初始状态概率 π i \pi_i πi 的估计 π ^ i \hat\pi_i π^i 为 S S S 个样本中初始状态为 q i q_i qi 的频率
Baum-Welch 算法 (无监督学习方法)
- 由于监督学习需要使用标注的训练数据,而人工标注训练数据往往代价很高,有时就会利用无监督学习的方法。假设给定训练数据只包含 S S S 个长度为 T T T 的观测序列 { O 1 , . . . , O S } \{O_1,...,O_S\} {O1,...,OS} 而没有对应的状态序列,目标是学习隐马尔可夫模型 λ = ( A , B , π ) λ = (A, B,\pi) λ=(A,B,π) 的参数。我们将观测序列数据看作观测数据 O O O,状态序列数据看作不可观测的隐数据 I I I,那么隐马尔可夫模型事实上是一个含有隐变量的概率模型
 它的参数学习可以由 EM 算法实现
它的参数学习可以由 EM 算法实现
E 步: 求 Q Q Q 函数 Q ( λ , λ ˉ ) Q(\lambda,\bar\lambda) Q(λ,λˉ)
max λ E I [ log P ( O , I ∣ λ ) ∣ O , λ ˉ ] = max λ ∑ I log P ( O , I ∣ λ ) P ( I ∣ O , λ ˉ ) = max λ ∑ I log P ( O , I ∣ λ ) P ( O , I ∣ λ ˉ ) P ( O ∣ λ ˉ ) = max λ ∑ I log P ( O , I ∣ λ ) P ( O , I ∣ λ ˉ ) \begin{aligned} \max_\lambda E_I[\log P(O,I\mid\lambda)\mid O,\bar\lambda] &=\max_\lambda \sum_{I} \log P(O, I \mid \lambda) P(I \mid O,\bar{\lambda}) \\&=\max_\lambda \sum_{I} \log P(O, I \mid \lambda) \frac{P(O, I \mid \bar{\lambda})}{P(O\mid\bar\lambda)} \\&=\max_\lambda \sum_{I} \log P(O, I \mid \lambda) {P(O, I \mid \bar{\lambda})} \end{aligned} λmaxEI[logP(O,I∣λ)∣O,λˉ]=λmaxI∑logP(O,I∣λ)P(I∣O,λˉ)=λmaxI∑logP(O,I∣λ)P(O∣λˉ)P(O,I∣λˉ)=λmaxI∑logP(O,I∣λ)P(O,I∣λˉ)
- 因此,可直接设 Q ( λ , λ ˉ ) = ∑ I log P ( O , I ∣ λ ) P ( O , I ∣ λ ˉ ) Q(λ,\bar\lambda)=\sum_{I} \log P(O, I \mid \lambda) {P(O, I \mid \bar{\lambda})} Q(λ,λˉ)=∑IlogP(O,I∣λ)P(O,I∣λˉ)。其中, λ ˉ \bar\lambda λˉ 是隐马尔可夫模型参数的当前估计值, λ \lambda λ 是要极大化的隐马尔可夫模型参数
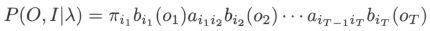
- 于是函数 Q ( λ , λ ˉ ) Q(λ,\bar\lambda) Q(λ,λˉ) 可以写成:

M 步: 极大化 Q ( λ , λ ˉ ) Q(λ,\bar\lambda) Q(λ,λˉ) 求模型参数 A , B , π A,B,\pi A,B,π
- 由于要极大化的参数在式 (10.34) 中单独地出现在 3 个项中,所以只需对各项分别极大化
- (1) 式 (10.34) 的第 1 项可以写成:
 注意到 π i \pi_i πi 满足约束条件 ∑ i = 1 N π i = 1 \sum_{i=1}^N\pi_i=1 ∑i=1Nπi=1,利用拉格朗日乘子法,写出拉格朗日函数:
注意到 π i \pi_i πi 满足约束条件 ∑ i = 1 N π i = 1 \sum_{i=1}^N\pi_i=1 ∑i=1Nπi=1,利用拉格朗日乘子法,写出拉格朗日函数:
 由 KKT 条件可知
由 KKT 条件可知
 得
得
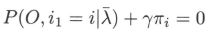 对 i i i 求和得到 γ γ γ
对 i i i 求和得到 γ γ γ
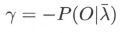 因此
因此

- (2) 式 (10.34) 的第 2 项可以写成
 类似第 1 项,应用具有约束条件 ∑ j = 1 a i j = 1 \sum_{j=1}a_{ij} = 1 ∑j=1aij=1 的拉格朗日乘子法可以求出
类似第 1 项,应用具有约束条件 ∑ j = 1 a i j = 1 \sum_{j=1}a_{ij} = 1 ∑j=1aij=1 的拉格朗日乘子法可以求出
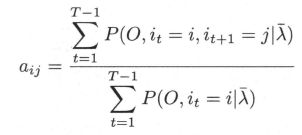
- (3) 式 (10.34) 的第 3 项为
 同样用拉格朗日乘子法,约束条件是 ∑ k = 1 M b j ( k ) = 1 \sum_{k=1}^Mb_j(k)=1 ∑k=1Mbj(k)=1。求得
同样用拉格朗日乘子法,约束条件是 ∑ k = 1 M b j ( k ) = 1 \sum_{k=1}^Mb_j(k)=1 ∑k=1Mbj(k)=1。求得
 其中 I I I 为指示函数
其中 I I I 为指示函数
Baum-Welch 算法
- 将参数迭代公式中的各概率分别用 γ t ( i ) , ξ t ( i , j ) \gamma_t(i),\xi_t(i,j) γt(i),ξt(i,j) 表示,则可将 Baum-Welch 算法写为以下形式:

预测算法
- 预测问题 / 解码 (decoding) 问题。已知模型 λ = ( A , B , π ) λ = (A ,B, π) λ=(A,B,π) 和观测序列 O = ( o 1 , . . . , o T ) O= (o_1 ,...,o_T) O=(o1,...,oT) 求对给定观测序列条件概率 P ( I ∣ O ) P (I|O) P(I∣O) 最大的状态序列 I = ( i 1 , , . . . , i T ) I = (i_1, ,...,i_T ) I=(i1,,...,iT)。即给定观测序列,求最有可能的对应的状态序列
近似算法
- 近似算法的想法是,在每个时刻 t t t 选择在该时刻最有可能出现的状态 i t ∗ i_t^* it∗,从而得到一个状态序列 I ∗ = ( i 1 ∗ , . . , i T ∗ ) I^* = (i_1^*,..,i_T^*) I∗=(i1∗,..,iT∗),将它作为预测的结果
 其中,
其中,

- 近似算法的优点是计算简单,其缺点是不能保证预测的状态序列整体是最有可能的状态序列,因为预测的状态序列可能有实际不发生的部分。尽管如此,近似算法仍然是有用的
维特比算法 (Viterbi algorithm)
- 维特比算法实际是用动态规划求概率最大路径 (最优路径)。这时一条路径对应着一个状态序列
- 根据动态规划原理,最优路径具有这样的特性: 如果最优路径在时刻 t t t 通过结点 i t ∗ i_t^* it∗,那么这一路径从结点 i t ∗ i_t^* it∗ 到终点 i T ∗ i_T^* iT∗ 的部分路径,对于从 i t ∗ i_t^* it∗ 到 i T ∗ i_T^* iT∗ 的所有可能的部分路径来说,必须是最优的。依据这一原理,我们只需从时刻 t = 1 t=1 t=1 开始,递推地计算在时刻 t t t 状态为 i i i 的各条部分路径的最大概率,直至得到时刻 t = T t = T t=T 状态为 i i i 的各条路径的最大概率。时刻 t = T t = T t=T 的最大概率即为最优路径的概率 P ∗ P^* P∗,最优路径的终结点 i T ∗ i^*_T iT∗ 也同时得到。之后,为了找出最优路径的各个结点,从终结点 i T ∗ i^*_T iT∗ 开始,由后向前逐步求得结点 i T − 1 ∗ , . . . , i 1 ∗ i_{T-1}^*,...,i_1^* iT−1∗,...,i1∗,得到最优路径 I ∗ = ( i 1 ∗ , . . . , i T ∗ ) I^* = (i_1^*,...,i_T^*) I∗=(i1∗,...,iT∗)
Notation
- 首先导入两个变量 δ \delta δ 和 ψ \psi ψ。定义在时刻 t t t 状态为 i i i 的所有单个路径 ( i 1 , . . . , i t − 1 , i ) (i_1,...,i_{t-1},i) (i1,...,it−1,i) 中概率最大值为
 由定义可得变量 δ \delta δ 的递推公式:
由定义可得变量 δ \delta δ 的递推公式:
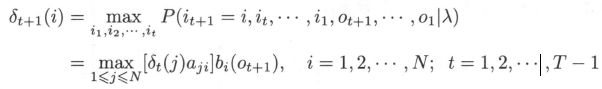 定义在时刻 t t t 状态为 i i i 的所有单个路径 ( i 1 , . . . , i t − 1 , i ) (i_1,...,i_{t-1},i) (i1,...,it−1,i) 中概率最大的路径的第 t − 1 t-1 t−1 个结点为
定义在时刻 t t t 状态为 i i i 的所有单个路径 ( i 1 , . . . , i t − 1 , i ) (i_1,...,i_{t-1},i) (i1,...,it−1,i) 中概率最大的路径的第 t − 1 t-1 t−1 个结点为

维特比算法
