卷积神经网络
卷积神经网络介绍
为什么要“卷积”
全连接所需要的参数数量过多,尤其对于现在处理的数据量来说更多,对应硬件显存要求巨大。为了减少这部分需求,同时对神经网络也能够实现很好的训练,提出了卷积神经网络的概念
如何实现
权值共享
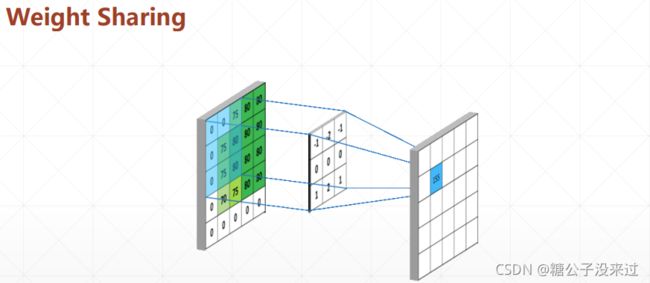
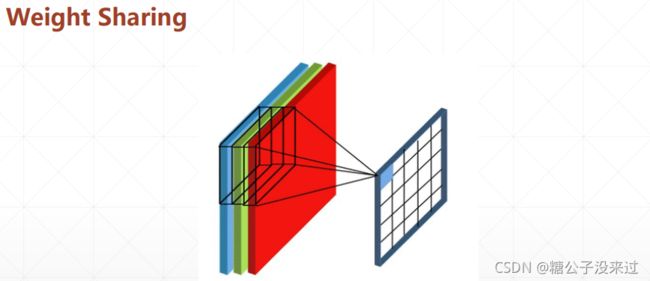
一些概念
-
feature maps:
- 比如说在Computer Vision 领域中,feature map 指的就是图像,包括输入的原始图像以及通过神经网络各层处理出来的“中间图像”。中间图像加引号是因为有的层处理完之后的由于维度发生了变换,无法呈现出一个图像的样子,它只是一个概念。就像下面这个图展示的那样,都代表feature maps

-
2D Convolution:
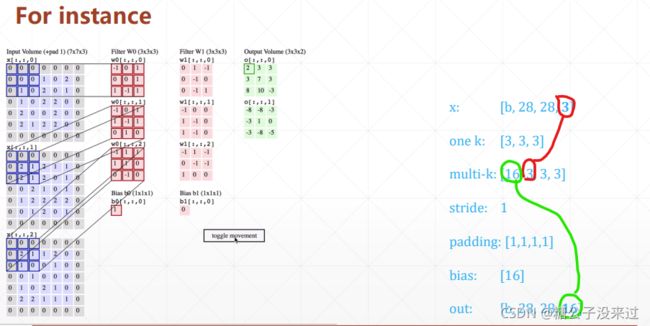
- 二维卷积。有的图片输入是有R/G/B三个通道(Channel),在进行处理时要进行降维,也就是一个 Kernel 同时处理三个维度,然后再将这三个数字加到一起,成为新 feature map 上的一个点数值,像下面展示的那样
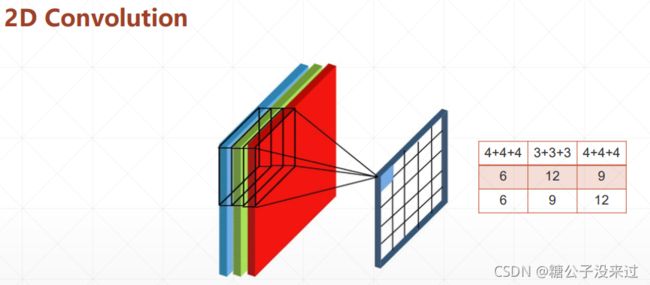
-
Kernel/Kernel size
- Kernel 就是进行计算的权值矩阵。是由 learned weights 组成,Kernel size 就是 Kernel 矩阵的shape
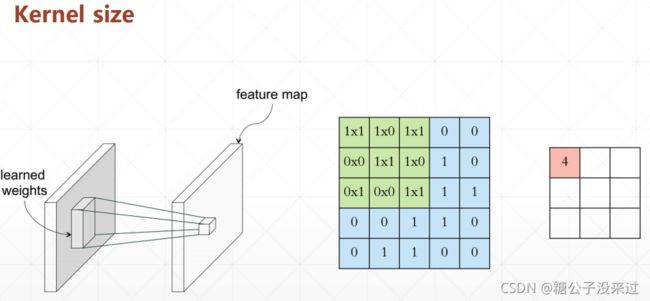
-
Padding & Stride
- 通常来讲,进行卷积之后的 feature map 的 shape 要小于卷积之前的 shape ,这是由 Kernel 卷积核的 shape 决定的。Kernel 如果 shape 比较大的话,就会把原来的 feature map 的 shape 压缩的比较多。为了让卷积之后的 map 大小和原来一样,就要在原来map的四周添加 pad,这个操作就叫 padding。
- 在对 map 进行卷积计算时,扫描的步长叫做 Stride。
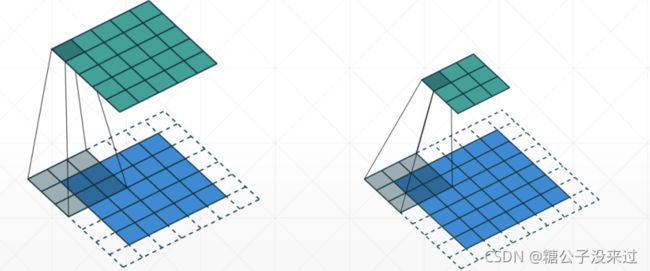
-
Channels
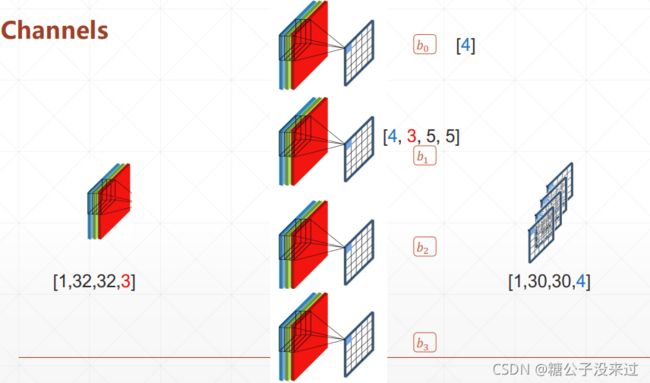
- 对于输入图像来说,比如一个 [1, 32, 32, 3] 的图像,Channel 就是最后一位数字 3,代表3个通道,通常指R、G、B三个通道,如果是 [1, 32, 32, 1] 就代表是一个灰度图像。
- 在 Kernel 上还有一个 Channel 概念,这个Channel不是故意设置出来的,而是为了能够获得特定shape 的feature map 而设计的。比如说在经过神经网络的某一层时,想要把 [1, 32, 32, 3] 变成一个 [1, 30, 30, 4]的map,如果使用上面提到的 [5, 5] 的 Kernel 的话,最后会变成一个[1, 30, 30, 1] 的网络,达不到要求。如果让 Kernel Size 变成 [4, 3, 5, 5] 的话,也就是说,在扫描某一区域的时候,会将这个区域用4个 Kernel 分别扫描一遍,各自获得一个数值,成为新 map 上的一点。不管怎么说吧,最后得到的是在图像的长和宽变短,而深度变深的 feature map,也就是让图像的像素点拥有了更多的信息量
- 需要注意的是,Kernel Size 中第一个参数是你想让新的feature map 最后一个维度的 shape,第二个参数就是上一个feature map 最后一个维度的shape
TensorFlow中的卷积神经网络
layers.Conv2D

这里面的参数:4代表你想让新的feature map 的最后一维shape 是多少,这里就填多少;kernel_size 设置的是5*5,步长strides设置的是1,padding = 'valid' 表示不进行padding操作,这样的话图像的长宽会减少。像下面的 padding = 'same' 表示要进行padding 操作,它会自动帮你计算需要padding多少空白的pad,最后输出和输入一样的长宽。
补充一点,stride = 1,kernel_size = 5 还不进行 padding 的话,对于 input 是[1, 32, 32, 3]的图像来说,输出的28 = 32-(5-1);对于stride = 2 来说,就是长宽折半了
weight & bias

可以看到,在TensorFlow 中kernel size 的表示是 [5, 5, 3, 4],这种形式和之前的例子[4, 3, 5, 5]不太一样,能够对应上就好,意义是一样的
再说一嘴 bias ,这个 bias 就是在 kernel 都计算完(相乘取和)之后,对这个结果再加上一个 bias,得到最终的数值。在上面这个例子里并没有设置 bias 因此都是0。对了,bias的shape是输出图像最后一维的shape
nn.conv2d
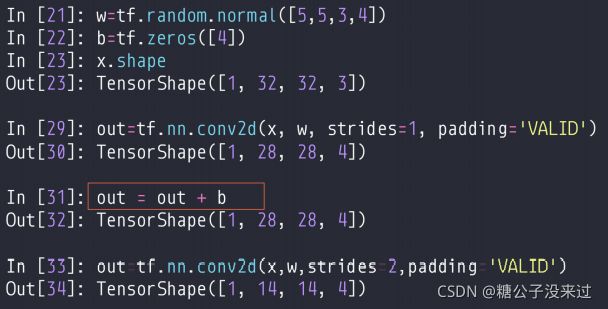
nn.conv2d 也可以实现像上面 layers.Conv2D 相似的功能,但是推荐使用 layers.Conv2D
池化与采样
- Pooling
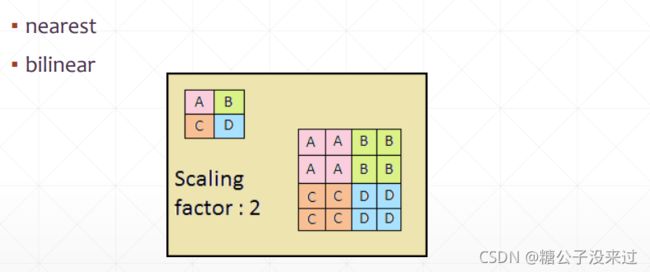
- upsample
- ReLU
Max/Avg pooling
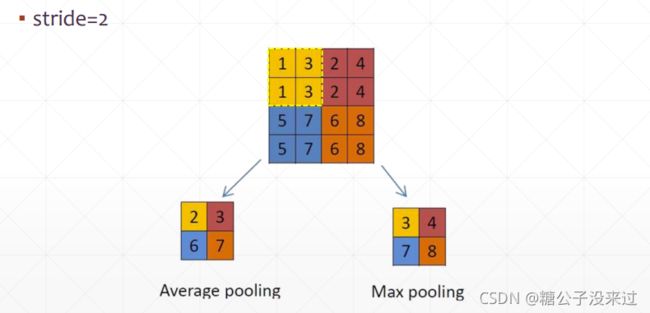
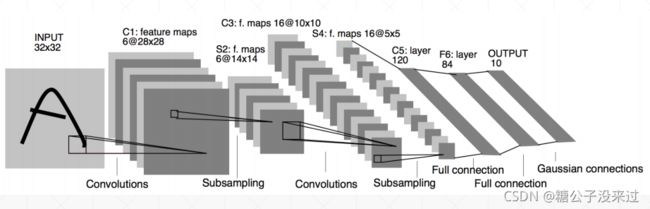
LeNet-5
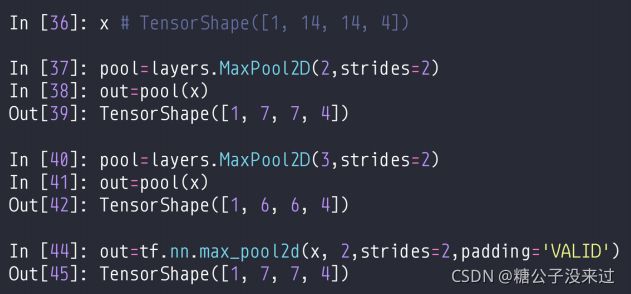
layers.MaxPool2D / tf.nn.max_pool2d
upsample
UpSampling2D

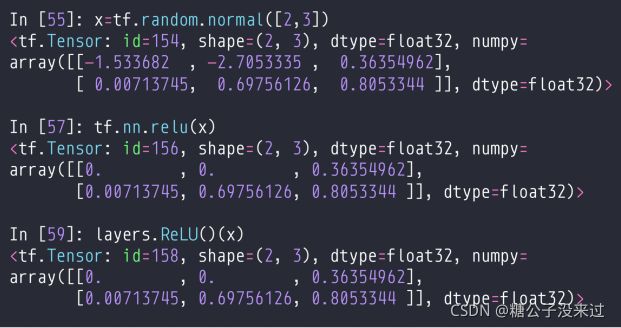
ReLU

tf.nn.relu / layers.ReLU()
CIFAR100实战
CIFAR100

13 Layers

源代码
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
tf.random.set_seed(2345)
conv_layers = [ # 5 units of conv + max pooling
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
def preprocess(x, y):
# [0~1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(64)
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
def main():
# [b, 32, 32, 3] => [b, 1, 1, 512]
conv_net = Sequential(conv_layers)
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(100, activation=None),
])
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None, 512])
optimizer = optimizers.Adam(lr=1e-4)
# [1, 2] + [3, 4] => [1, 2, 3, 4]
variables = conv_net.trainable_variables + fc_net.trainable_variables
for epoch in range(50):
for step, (x,y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 1, 1, 512]
out = conv_net(x)
# flatten, => [b, 512]
out = tf.reshape(out, [-1, 512])
# [b, 512] => [b, 100]
logits = fc_net(out)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
if step %100 == 0:
print(epoch, step, 'loss:', float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
out = conv_net(x)
out = tf.reshape(out, [-1, 512])
logits = fc_net(out)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()