数据仓库Hive学习笔记整理
数仓
1. 数仓概念
数据仓库(Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision support)。
数据的搬运工。
2. 数仓专注分析
数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;
同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用。
3. 数据仓库为何而来,解决什么问题
为了分析数据而来,分析结果给企业决策提供支撑。
4. 业务数据的存储问题
联机事务处理系统(OLTP),执行联机事务处理。基本特征是,前台接收的用户数据,可以立即传送到后台进行处理,并在很短的时间内给出处理结果。
关系型数据库(RDBMS)是OLTP典型应用,如Oracle、MySQL、SQL server等。
5. OLTP环境开展分析可行吗?
可以,但是没必要。
OLTP系统的核心是面向业务,支持业务,支持事务。分为读操作和写操作。一般读的压力明显大于写的压力,如果在OLTP环境直接分析
会让读取压力倍增。
OLTP仅存储数周或数月的数据。
数据分散在不同系统,不同表中,字段类型属性不统一。
6. 数据仓库面世
为了更好的进行各种规模的数据分析,同时也不影响OLTP系统运行,此时需要构建一个集成统一的数据分析平台。
该平台的目的很简单:面向分析,支持分析,并且和OLTP系统解耦合。
基于这种需求,数据仓库的雏形开始在企业中出现了。
7. 数据仓库的构建
数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境。
这种面向分析、支持分析的系统就是OLAP(联机分析处理)系统。
数据仓库是OLAP系统的一种实现。
基于分析决策需求,构建数仓平台。
8. 数仓的主要特征
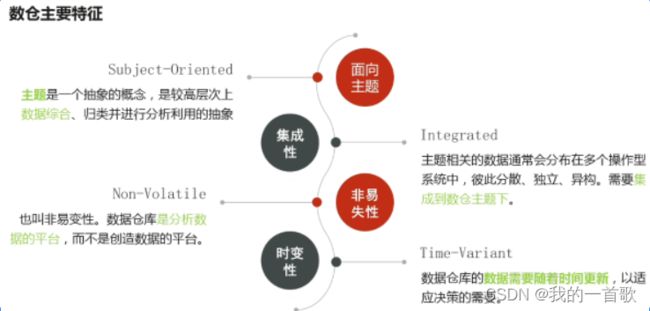
9. ETL
抽取、转换、加载。
10. 结构化数据
结构化数据也称为行数据,是由二维表结构来逻辑表达和实现的数据
有严格的行对齐,便于解读与理解
11. DDL和DML
DDL(Data Definition Language) 数据库定义语言
DML(Date Manipulation Language) 数据库操作语言
Hive
1. 什么是Hive
Apache Hive 是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件系统中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive的核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群执行。
Hive由Facebook实现并开源
2. Hive和Hadoop的关系
从功能方面考虑,数据仓库首先要具备以下两个功能:
存储数据
分析数据
Hive作为大数据时代的数据仓库,也具备以上两个功能,但是它不是自己实现,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
Hive最大的魅力在于:用于专注于编写HQL即可,Hive将HQL转换为MapReduce程序完成数据的分析。
3. Hive组件
用户接口
元数据存储
通常是存储在关系型数据库中,Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否是外部表),表的数据所在目录等。
元数据是解释数据的数据,在Hive中元数据指的是表和文件之间的映射关系。
记录了数据的文件路径,字段,分隔符等信息。
Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
执行引擎
Hive本身并不直接处理数据文件,而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark 3终执行引擎。
4. Hive自带客户端
目前共两个版本
第一代客户端(deprecated不推荐): H I V E H O M E / b i n / h i v e ;第二代客户端( r e c o m m e n d e d 推荐使用): HIVE_HOME/bin/hive; 第二代客户端(recommended推荐使用): HIVEHOME/bin/hive;第二代客户端(recommended推荐使用):HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐的Hive命令行工具,和第一代客户端相比,性能加强、安全性提高。
HiveServer2服务介绍
远程模式下beeline通过Thrift连接到单独的HiveServer2服务上,这也是官方推荐的生产环境中使用的模式。
HiveServer2支持多客户端的并发和身份认证。
HiveServer2通过Metastore服务读写元数据,所以在远程模式下,启动HiveServer2之前必须先启动Metastore服务。
远程模式下,beeline客户端只能通过HiveServer2访问HIve,而bin/hive是通过Metastore服务访问的。
先启动Metastore、后启动HiveServer2。
nohup /export/servers/hive/bin/hive --service metastore &
nohup /export/servers/hive/bin/hive --service hiveserver2 &
5. 建库
创建数据库: CREATE DATABASE database_name;
切换数据库: USE database_name;
删除数据库: DROP DATABASE database_name;
默认删除行为是restrict(约束),这意味着仅在数据库为空时才能删除它。
要删除带有表的数据库(不为空的数据库),我们可以使用cascade。
语句: DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
删除数据库务必谨慎。
查看数据库:
show databases;
show schemas;
6. 建表
建表语句 (待扩展):
CREATE TABLE [IF NOT EXISTS] [db_name.] table_name
(col_name data_type [COMMENT col_comment],…)
[COMMENT table_comment]
[ROW FORMAT DELIMITED …];
PARTITIONED BY (clndr_dt_id int) :标明分区字段。
ROW FORMAT DELIMITED 分隔符设置开始语句
FIELDS TERMINATED BY:设置字段与字段之间的分隔符
COLLECTION ITEMS TERMINATED BY:设置一个复杂类型(array,struct)字段的各个item之间的分隔符
MAP KEYS TERMINATED BY:设置一个复杂类型(Map)字段的key value之间的分隔符
LINES TERMINATED BY:设置行与行之间的分隔符
如果不指定字段分隔符,默认以“\001”为字段分隔符。
查看所有表: show tables;
也可使用:show tables in database_name;
查看建表语句:show create table table_name;
查看表的字段属性:desc table_name;
查看表的详细元数据:desc formatted table_name;
7. Load语法功能
将数据文件移动到与Hive表对应的位置。
Load语法规则
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename;
语法LOCAL
指定LOCAL,将在本地文件系统中查找文件路径。
本地指的是HiveServer2服务所在的机器。
不写LOCAL,基本都是再hdfs系统中查找。
使用再Hadoop配置文件中参数fs.default.name指定的。
8. inser+select
INSERT INTO TABLE table_name1 SELECT col_name,… FROM talbe_name2;
Hive函数
- 概述
使用show functions 查看当下可用的所有函数。
通过describe function extended funcname 来查看函数的使用方式。