【浙工商期末报告】研一Python期末作业B题(思路分享+源代码分享+原报告分享)
目录:研一Python期末作业B题(思路分享)
- 一、题目介绍
-
- 1.1 A题
- 1.2 B题
- 二、B题思路讲解
-
- 2.1 问题的引入
- 2.2 不平衡数据集
-
- 2.2.1 不平衡数据的实例
- 2.2.2 不平衡数据集导致的问题
- 2.2.3 不平衡数据集的主要处理方法
- 2.2.4 不平衡(均衡)数据集常用的处理方法实战
- 2.3 检查是否存在空值
- 2.4 数据分析过程
- 2.5 数据编码
- 2.7 数据集采样
- 2.8 模型的建立与求解
- 2.9 最后的29个算法模型比较
- 2.10 模型的预测
- 三、源代码和报告展示
- 五、代码和报告的分享地址
一、题目介绍
本次期末报告分为A和B两题,这里介绍一下两题:
1.1 A题
通过 Python 对数据集 orders.csv 进行数据分析。这个数据集包含某商店关于多种产品的销售数据,以及与地理、产品类别、销售收入和利润、消费者细分等相关信息。希望通过数据分析从数据中获取到有意义的见解,以改善市场和销售策略,其中必须包含但不限于可视化分析。
1.2 B题
提供一个与某金融机构的营销活动有关的数据集,这些营销活动是基于电话的。通常情况下,需要对同一客户进行一次以上的联系,以便了解该金融产品是否会被认购(“yes”)或不(“no”)。数据集中的各字段描述如下:
- 客户数据:
age :年龄(数值型);
job :工作情况(分类:‘admin.’, ‘blue-collar’, ‘entrepreneur’, ‘housemaid’, ‘management’,‘retired’, ‘self-employed’, ‘services’, ‘student’, ‘technician’, ‘unemployed’, ‘unknown’);
marital : 婚姻状况(分类:‘divorced’,‘married’,‘single’,‘unknown’; 注:‘divorced’ 指离婚或丧偶);
education :教育水平(分类:‘basic.4y’,‘basic.6y’,‘basic.9y’,‘high.school’,‘illiterate’,‘professional.course’,‘university.degree’,‘unknown’);
default :信用是否已经违约(分类: ‘no’,‘yes’,‘unknown’);
housing :是否有住房贷款(分类: ‘no’,‘yes’,‘unknown’);
loan :是否有个人贷款(分类: ‘no’,‘yes’,‘unknown’);
- 与当前活动的最后一次联系有关的数据:
contact :联系时通信类型(分类: ‘cellular’,‘telephone’);
month :一年中最后一次联系的月份(分类: ‘jan’, ‘feb’, ‘mar’, …, ‘nov’, ‘dec’);
dayofweek :一周中最后一次联系是周几(分类: ‘mon’,‘tue’,‘wed’,‘thu’,‘fri’);
campaign :在本次活动中与该客户的联系次数(数值型,包括最后一次联系);
passed_days :上次联系客户后的天数(数值型,999 表示以前没有联系过客户);
previous :在此活动之前与该客户的联系次数(数值型);
pre_outcome :前期营销活动的结果(分类: ‘failure’,‘nonexistent’,‘success’);
- 与社会和经济背景有关的一些指标:
emp_rate :就业变化率,季度指标(数值型);
cpi :消费者价格指数,月度指标(数值型);
cci :消费者信心指数,月度指标(数值型);
r3m :银行的 3 个月利率,每日指标(数值型);
employed :雇员人数,季度指标(数值型);
- 输出变量
y :客户是否认购该金融产品(分类: ‘yes’, ‘no’).
该题包含两个文件,分别是完整的数据集( data.xlsx ),以及将要预测的结果( 学号.csv )。要求根据 data.xlsx 构建合适的机器学习模型,然后对 学号.csv 中的数据进行预测,并填入预测结果( yes或 no )。
二、B题思路讲解
2.1 问题的引入
本题是一个二分类问题,我们可以考虑使用常用的二分类算法,比如支持向量机、逻辑回归、决策树等算法。
但是本题的标签数据比较奇怪:

no 23596
yes 3049
Name: y, dtype: int64
正负样本的比例比较悬殊!
这是一个典型的不平衡数据集。
不平衡数据集经常出现在某些业务场景中,比如点击率预估,异常检测等。对于初学者来说,当你接到一个分类任务,乱七八糟胡乱操作一番后,上个baseline,发现自己分类的Accuracy居然高达99%(真是天才般的模型啊),但是真的部署在实际生产环境,发现对所有测试数据的预测结果居然都是Fasle。
这就是不平衡数据集带来的影响。
2.2 不平衡数据集
不平衡数据集指的是数据集各个类别的样本数目相差巨大。以二分类问题为例,假设正类的样本数量远大于负类的样本数量,这种情况下的数据称为不平衡数据。
在二分类问题中,训练集中class 1的样本数比上class 2的样本数的比值为60:1。使用逻辑回归进行分类,最后结果是其忽略了class 2,将所有的训练样本都分类为class 1。
在三分类问题中,三个类别分别为A,B,C,训练集中A类的样本占70%,B类的样本占25%,C类的样本占5%。最后我的分类器对类A的样本过拟合了,而对其它两个类别的样本欠拟合。
2.2.1 不平衡数据的实例
训练数据不均衡是常见并且合理的情况,比如:
在欺诈交易识别中,绝大部分交易是正常的,只有极少部分的交易属于欺诈交易。
在客户流失问题中,绝大部分的客户是会继续享受其服务的(非流失对象),只有极少数部分的客户不会再继续享受其服务(流失对象)。
2.2.2 不平衡数据集导致的问题
如果训练集的90%的样本是属于同一个类的,而我们的分类器将所有的样本都分类为该类,在这种情况下,该分类器是无效的,尽管最后的分类准确度为90%。所以在数据不均衡时,准确度(Accuracy)这个评价指标参考意义就不大了。实际上,如果不均衡比例超过4:1,分类器就会偏向于大的类别。
2.2.3 不平衡数据集的主要处理方法
- 从数据的角度出发,主要方法为采样,分为
欠采样和过采样以及对应的一些改进方法。 - 从算法的角度出发,考虑不同误分类情况代价的差异性对算法进行优化,主要是基于代价敏感学习算法(Cost-Sensitive Learning),代表的算法有adacost。
2.2.4 不平衡(均衡)数据集常用的处理方法实战
(1)扩充数据集
首先想到能否获得更多数据,尤其是小类(该类样本数据极少)的数据,更多的数据往往能得到更多的分布信息。
(2)对数据集进行重采样
- 过采样(over-sampling)
对小类的数据样本进行过采样来增加小类的数据样本个数,即采样的个数大于该类样本的个数。
# -*- coding: utf-8 -*-
from imblearn.over_sampling import RandomOverSampler
ros=RandomOverSampler(random_state=0) #采用随机过采样(上采样)
x_resample,y_resample=ros.fit_sample(trainset,labels)
- 欠采样(under-sampling)
对大类的数据样本进行欠采样来减少大类的数据样本个数,即采样的个数少于该类样本的个数。
采样算法容易实现,效果也不错,但可能增大模型的偏差(Bias),因为放大或者缩小某些样本的影响相当于改变了原数据集的分布。对不同的类别也要采取不同的采样比例,但一般不会是1:1,因为与现实情况相差甚远,压缩大类的数据是个不错的选择。
# -*- coding: utf-8 -*-
from imblearn.under_sampling import RandomUnderSampler
#通过设置RandomUnderSampler中的replacement=True参数, 可以实现自助法(boostrap)抽样
#通过设置RandomUnderSampler中的rratio参数,可以设置数据采样比例
rus=RandomUnderSampler(ratio=0.4,random_state=0,replacement=True) #采用随机欠采样(下采样)
x_resample,y_resample=rus.fit_sample(trainset,labels)
2.3 检查是否存在空值
此处不存在,不需要数据预处理的步骤!
2.4 数据分析过程
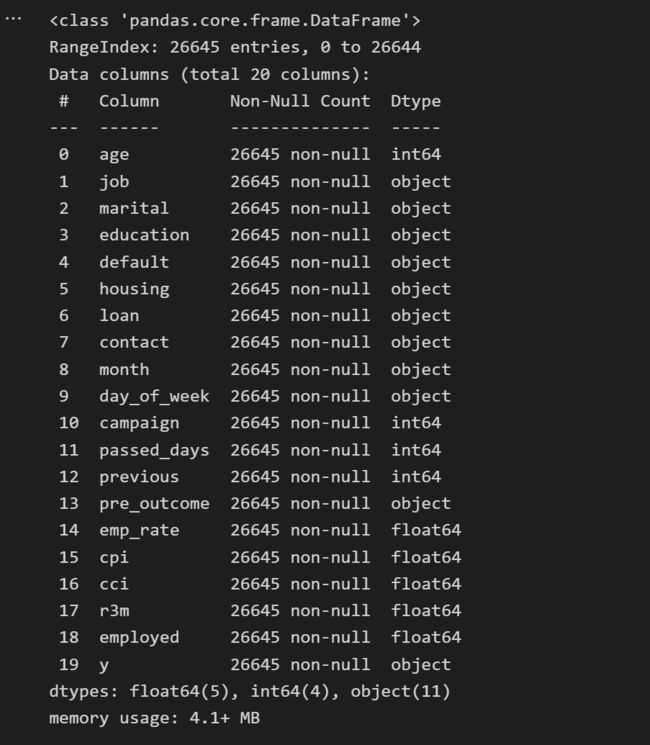
对各类特征进行数据分析,主要采用可视化的方法,得出初步结论,如下简单示例:

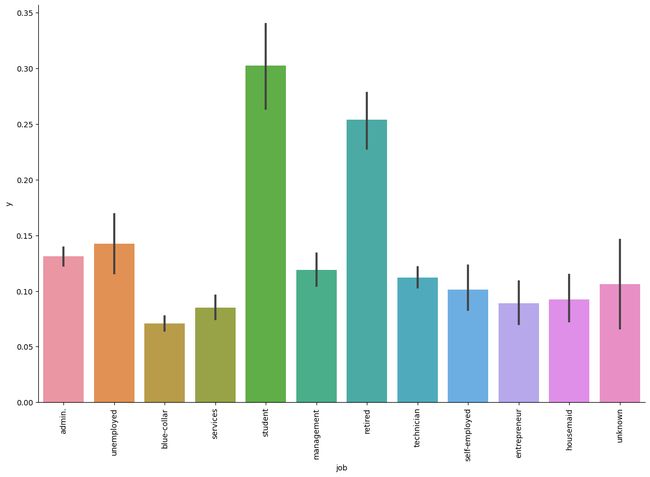
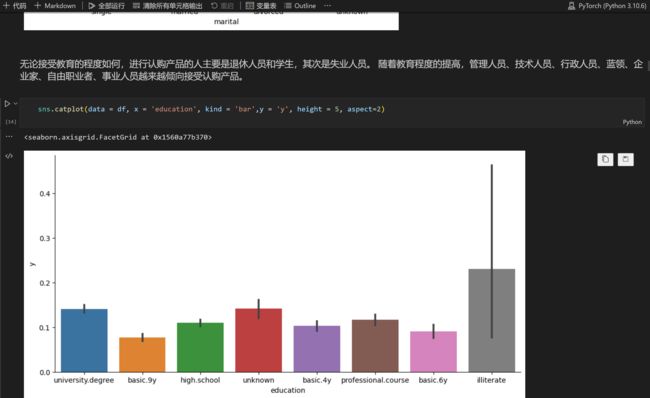
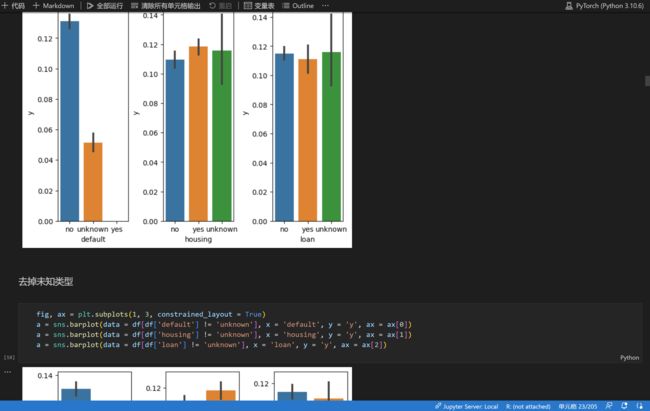
2.5 数据编码
主要采用one-hot编码,可以直接调用函数pd.get_dummies。
是利用pandas实现one hot encode的方式。
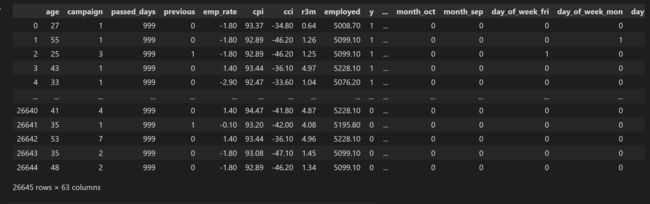
此时数据集的列为:
Index(['age', 'campaign', 'passed_days', 'previous', 'emp_rate', 'cpi', 'cci',
'r3m', 'employed', 'y', 'job_admin.', 'job_blue-collar',
'job_entrepreneur', 'job_housemaid', 'job_management', 'job_retired',
'job_self-employed', 'job_services', 'job_student', 'job_technician',
'job_unemployed', 'job_unknown', 'marital_divorced', 'marital_married',
'marital_single', 'marital_unknown', 'education_basic.4y',
'education_basic.6y', 'education_basic.9y', 'education_high.school',
'education_illiterate', 'education_professional.course',
'education_university.degree', 'education_unknown', 'default_no',
'default_unknown', 'default_yes', 'housing_no', 'housing_unknown',
'housing_yes', 'loan_no', 'loan_unknown', 'loan_yes',
'contact_cellular', 'contact_telephone', 'month_apr', 'month_aug',
'month_dec', 'month_jul', 'month_jun', 'month_mar', 'month_may',
'month_nov', 'month_oct', 'month_sep', 'day_of_week_fri',
'day_of_week_mon', 'day_of_week_thu', 'day_of_week_tue',
'day_of_week_wed', 'pre_outcome_failure', 'pre_outcome_nonexistent',
'pre_outcome_success'],
dtype='object')
2.7 数据集采样
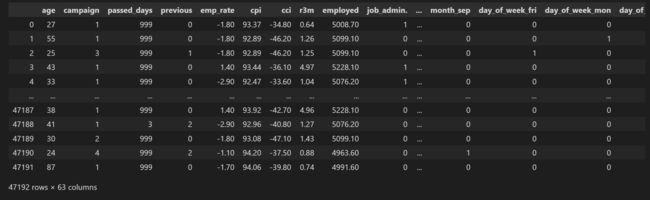
这时的正负样本已然均衡:
1 23596
0 23596
Name: y, dtype: int64
2.8 模型的建立与求解
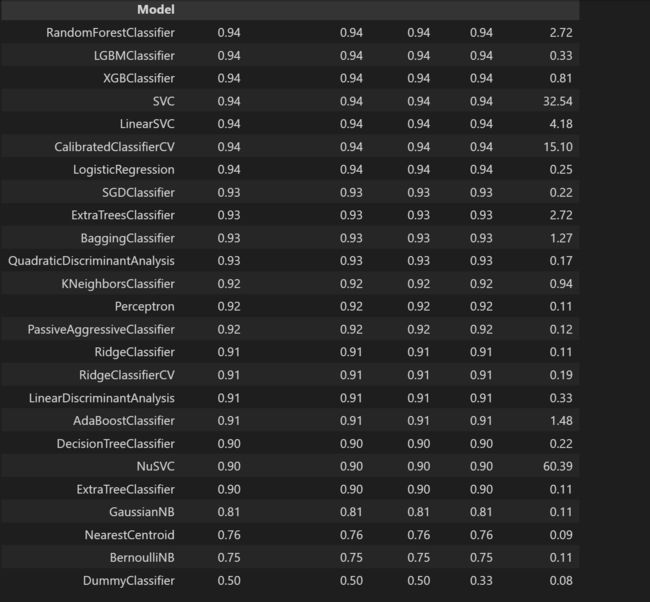
这里我主要测试了九个算法,分别是Adaboost算法、逻辑回归算法、支持向量机算法、KNN算法、决策树算法、随机森林算法、GBDT算法、LightGBM算法以及Xgboost算法。
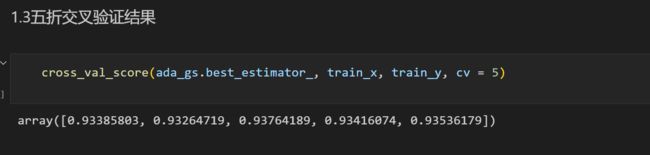
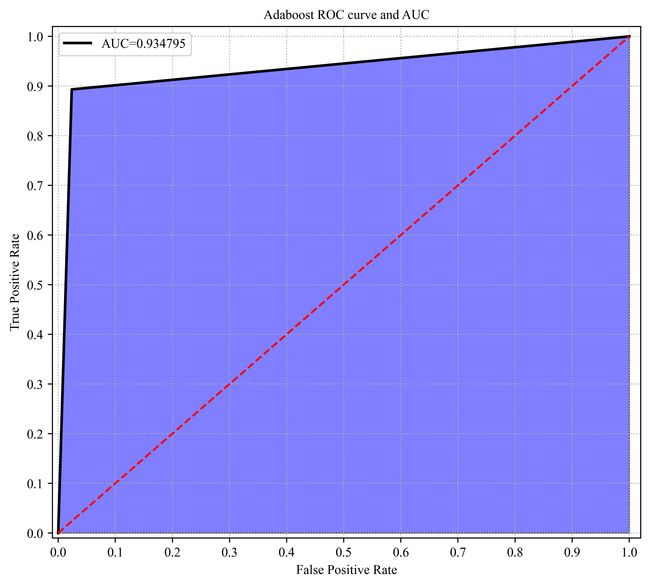
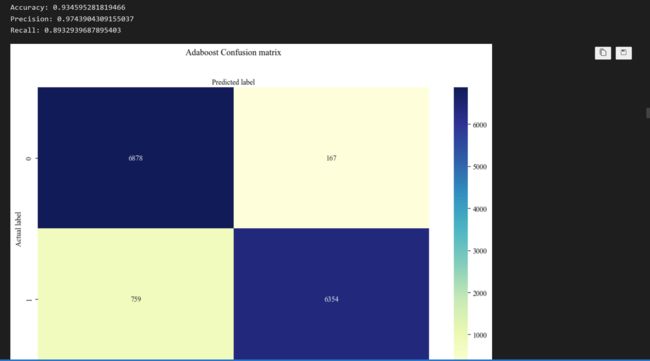
每一个算法都进行了评估,包括ROC曲线以及混淆矩阵,并用五折交叉验证和网格搜索确认了最佳参数。
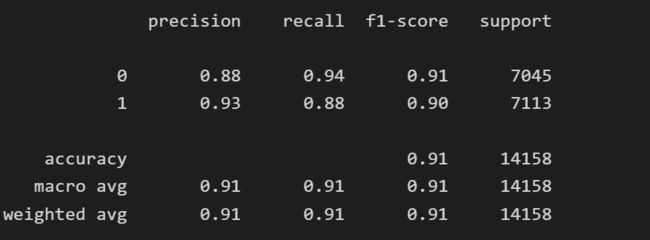
下面举一个算法的例子,以Adaboost算法为例:
准确率: 0.9054951264302867
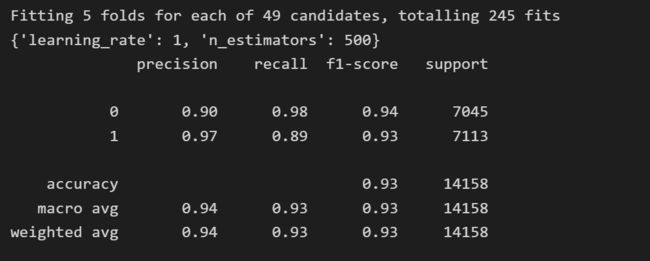
准确率: 0.934595281819466
2.9 最后的29个算法模型比较
2.10 模型的预测
选定好模型之后,进行预测,步骤与上述相同,但是不需要采样。
需要注意的是,最后需要预测的数据集缺少一列,需要排除掉才能去训练。
三、源代码和报告展示

格式均已整理好!
42页word报告!

五、代码和报告的分享地址
代码的地址:
https://mbd.pub/o/bread/mbd-Y52YlZ9u
报告的地址:
https://mbd.pub/o/bread/mbd-Y52YlZ9x