CH6 贝叶斯方法
文章目录
- CH6 贝叶斯方法
-
- 6.1 贝叶斯公式
- 6.2 朴素贝叶斯
- 6.3 例题
-
- 6.3.1 贝叶斯
- 6.3.2 朴素贝叶斯
- 训练一个朴素贝叶斯分类器
- 6.4 贝叶斯网络
-
- 6.4.1 贝叶斯网络示例
- 6.4.2 例题
CH6 贝叶斯方法
6.1 贝叶斯公式
P ( A ∣ B ) = P ( A , B ) P ( B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B) = \frac{P(A,B)}{P(B)} = \frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(A,B)=P(B)P(B∣A)P(A)
6.2 朴素贝叶斯
所有特征条件独立于决策(特征独立性),即:
P ( f 1 , … , f d ∣ c l a s s ) = ∏ i = 1 d P ( f i ∣ c l a s s ) P(f_1,\dots,f_d|class) = \prod^d_{i=1}P(f_i|class) P(f1,…,fd∣class)=i=1∏dP(fi∣class)
对于连续属性可考虑为概率密度函数,假定 p ( x i ∣ c ) ∼ N ( μ c , i , σ c , i 2 ) p(x_i|c)\sim\mathcal{N}(\mu_{c,i},\sigma_{c,i}^2) p(xi∣c)∼N(μc,i,σc,i2),其中 μ c , i \mu_{c,i} μc,i和 σ c , i 2 \sigma_{c,i}^2 σc,i2分别是第c类样本在第i个属性上取值的均值和方差,则有:
p ( x i ∣ c ) = 1 2 π σ c , i e x p ( − ( x i − μ c , i ) 2 2 σ c , i 2 ) p(x_i|c) = \frac{1}{\sqrt{2\pi}\sigma_{c,i}}exp\bigg(-\frac{(x_i-\mu_{c,i})^2}{2\sigma_{c,i}^2}\bigg) p(xi∣c)=2πσc,i1exp(−2σc,i2(xi−μc,i)2)
6.3 例题
训练样本如下

问题:现在又来了第七个病人,是一个打喷嚏的建筑工人,请问他患上感冒的概率有多大?
6.3.1 贝叶斯
P ( 感冒 ∣ 打喷嚏,建筑工人 ) = P ( 打喷嚏,建筑工人 ∣ 感冒 ) P ( 感冒 ) P ( 打喷嚏,建筑工人 ) P(感冒|打喷嚏,建筑工人) = \frac{P(打喷嚏,建筑工人|感冒)P(感冒)}{P(打喷嚏,建筑工人)} P(感冒∣打喷嚏,建筑工人)=P(打喷嚏,建筑工人)P(打喷嚏,建筑工人∣感冒)P(感冒)
6.3.2 朴素贝叶斯
P ( 感冒 ∣ 打喷嚏,建筑工人 ) = P ( 打喷嚏 ∣ 感冒 ) P ( 建筑工人 ∣ 感冒 ) P ( 感冒 ) P ( 打喷嚏 ) P ( 建筑工人 ) P(感冒|打喷嚏,建筑工人) = \frac{P(打喷嚏|感冒)P(建筑工人|感冒)P(感冒)}{P(打喷嚏)P(建筑工人)} P(感冒∣打喷嚏,建筑工人)=P(打喷嚏)P(建筑工人)P(打喷嚏∣感冒)P(建筑工人∣感冒)P(感冒)
训练一个朴素贝叶斯分类器
数据集如下:
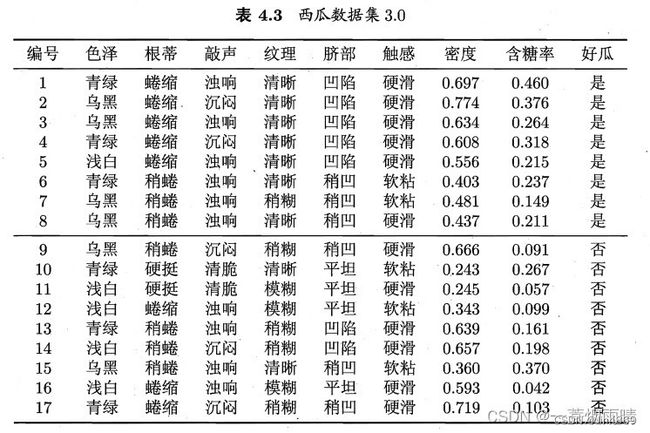
对测试例子进行分类

首先估计类先验概率P©,显然有:
P(好瓜 = 是) = 8 17 ≈ 0.471 \frac{8}{17} \approx 0.471 178≈0.471
P(好瓜 = 否) = 9 17 ≈ 0.529 \frac{9}{17} \approx 0.529 179≈0.529
然后,为每个属性估计条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)


于是,有:

由于 0.038 > 6.80 × 1 0 − 5 0.038 > 6.80 \times 10^{-5} 0.038>6.80×10−5,因此,朴素贝叶斯分类器将测试样本判别为好瓜。
需要注意,若某个属性值在训练集中没有与某个类同时出现过,则直接按上述方法将会出现问题。
例如,在使用西瓜数据集3.0训练朴素贝叶斯分类器时,对一个“敲声 = 清脆”的测试用例,有 P 清脆 ∣ 是 = P ( 敲声 = 清脆 ∣ 好瓜 = 是 ) = 0 8 = 0 P_{清脆|是} = P(敲声 = 清脆|好瓜 = 是) = \frac{0}{8} = 0 P清脆∣是=P(敲声=清脆∣好瓜=是)=80=0
则计算出的概率为0,无论该样本的其他属性是什么,哪怕在其他属性上明显像好瓜,分类的结果都是否,这显然不太合理。
为了避免其他属性携带的信息被训练集中未出现的属性值“抹去”,在估计概率值时通常需要进行“平滑”,常用“拉普拉斯修正”。
令 N N N 表示训练集D中可能的类别数, N i N_i Ni表示第i个属性可能的取值数,修正得:
P ( x i ∣ c ) = ∣ D c , x i ∣ + 1 ∣ D c ∣ + N i P(x_i|c) = \frac{|D_{c,x_i}|+1}{|D_c|+N_i} P(xi∣c)=∣Dc∣+Ni∣Dc,xi∣+1
例如,本例子中,类先验概率可估计为:(2为该属性可取“是”,“否”两个类别)
P(好瓜 = 是) = 8 + 1 17 + 2 ≈ 0.474 \frac{8+1}{17+2} \approx 0.474 17+28+1≈0.474
P(好瓜 = 否) = 9 + 1 17 + 2 ≈ 0.526 \frac{9+1}{17+2} \approx 0.526 17+29+1≈0.526
6.4 贝叶斯网络
6.4.1 贝叶斯网络示例
直观上:
- x1和x2独立
- x6和x7在x4给定的条件下独立
联合分布:
P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ∣ x 1 , x 2 , x 3 ) P ( x 5 ∣ x 1 , x 3 ) P ( x 6 ∣ x 4 ) P ( x 7 ∣ x 4 , x 5 ) P(x1)P(x2)P(x3)P(x4|x1,x2,x3)P(x5|x1,x3)P(x6|x4)P(x7|x4,x5) P(x1)P(x2)P(x3)P(x4∣x1,x2,x3)P(x5∣x1,x3)P(x6∣x4)P(x7∣x4,x5)
6.4.2 例题
使用贝叶斯分类方法预测一个客户(性别=女,婚姻状态=已婚,是否有房=无房),是否会购买此保险,写出详细的计算过程
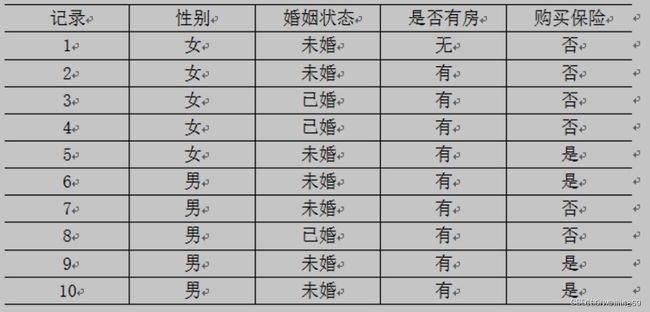
解答过程:
1.由训练集建立朴素贝叶斯网络
2.由训练集得出先验概率与条件概率
- P(购买保险 = 是) = 4 10 \frac{4}{10} 104 = 0.4
- P(购买保险 = 否) = 0.6
- P(性别 = 女|购买保险 = 是) = 1 4 \frac{1}{4} 41 = 0.25
- P(性别 = 女|购买保险 = 否) = 4 6 \frac{4}{6} 64 = 0.667
- P(婚姻状态 = 已婚|购买保险 = 是) = 0
- P(婚姻状态 = 已婚|购买保险 = 否) = 3 6 \frac{3}{6} 63 = 0.5
- P(是否有房 = 无房|购买保险 = 是) = 0
- P(是否有房 = 无房|购买保险 = 否) = 1 6 \frac{1}{6} 61 = 0.167
3.计算联合条件概率
记客户X = (性别 = 女,婚姻状态 = 已婚,是否有房 = 无房)
P(X|购买保险 = 是) = P(性别 = 女|购买保险 = 是) * P(婚姻状态 = 已婚|购买保险 = 是) * P(是否有房 = 无房|购买保险 = 是) = 0.25 * 0 * 0 = 0
P(X|购买保险 = 否) = 0.667 * 0.5 * 0.167 = 0.056
4.预测客户X是否购买保险
P(X|购买保险 = 是) * P(购买保险 = 是) = 0 * 0.4 = 0
P(X|购买保险 = 否) * P(购买保险 = 否) = 0.056 * 0.6 = 0.0336
结论:预测客户X不会购买此保险