yolov4 计算自己数据集先验框的长宽
yolov4.cfg文件中的先验框尺寸是coco数据集的,通用性可能已经够了,还是想试一下自己设置的能不能提高准确率。
用darknet源码中的gen_anchors.py文件生成自己数据集先验框的尺寸。
代码中IOU的计算部分没看懂,有人能解释一下吗
'''
Created on Feb 20, 2017
@author: jumabek
'''
from os import listdir
from os.path import isfile, join
import argparse
#import cv2
import numpy as np
import sys
import os
import shutil
import random
import math
width_in_cfg_file = 416.
height_in_cfg_file = 416.
def IOU(x,centroids):
similarities = []
k = len(centroids)
for centroid in centroids:
c_w,c_h = centroid
w,h = x
if c_w>=w and c_h>=h:
similarity = w*h/(c_w*c_h)
elif c_w>=w and c_h<=h:
similarity = w*c_h/(w*h + (c_w-w)*c_h)
elif c_w<=w and c_h>=h:
similarity = c_w*h/(w*h + c_w*(c_h-h))
else: #means both w,h are bigger than c_w and c_h respectively
similarity = (c_w*c_h)/(w*h)
similarities.append(similarity) # will become (k,) shape
return np.array(similarities)
def avg_IOU(X,centroids):
n,d = X.shape
sum = 0.
for i in range(X.shape[0]):
#note IOU() will return array which contains IoU for each centroid and X[i] // slightly ineffective, but I am too lazy
sum+= max(IOU(X[i],centroids))
return sum/n
def write_anchors_to_file(centroids,X,anchor_file):
f = open(anchor_file,'w')
anchors = centroids.copy()
print(anchors.shape)
print('acc:{:.2f}%'.format(avg_IOU(X, anchors) * 100))
for i in range(anchors.shape[0]):
anchors[i][0] = round( anchors[i][0] * width_in_cfg_file) # /32.
anchors[i][1] = round( anchors[i][1] * height_in_cfg_file) # /32.
widths = anchors[:, 0]
sorted_indices = np.argsort(widths)
for i in sorted_indices[:-1]:
f.write('%d, %d, '%(anchors[i,0],anchors[i,1]))
#there should not be comma after last anchor, that's why
f.write('%d, %d\n'%(anchors[sorted_indices[-1:],0],anchors[sorted_indices[-1:],1]))
out = anchors[sorted_indices]
print('Anchors = ', out)
# f.write('%f\n'%(avg_IOU(X,centroids)))
def kmeans(X,centroids,eps,anchor_file):
N = X.shape[0] #锚框个数
iterations = 0
k,dim = centroids.shape
prev_assignments = np.ones(N)*(-1)
iter = 0
old_D = np.zeros((N,k))
while True:
D = []
iter+=1
for i in range(N):
d = 1 - IOU(X[i],centroids)
D.append(d)
D = np.array(D) # D.shape = (N,k)
print("iter {}: dists = {}".format(iter,np.sum(np.abs(old_D-D))))
#assign samples to centroids
assignments = np.argmin(D,axis=1) # 取出最小点
if (assignments == prev_assignments).all() :
print("Centroids = ",centroids)
write_anchors_to_file(centroids,X,anchor_file)
return
#calculate new centroids
centroid_sums=np.zeros((k,dim),np.float)
for i in range(N):jieguo
centroid_sums[assignments[i]]+=X[i]
for j in range(k):
centroids[j] = centroid_sums[j]/(np.sum(assignments==j))
prev_assignments = assignments.copy()
old_D = D.copy()
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument('-filelist', default = '\\scripts\\VOCdevkit\\VOC2020\\labels',
help='path to filelist\n' )
parser.add_argument('-output_dir', default = 'generated_anchors/anchors', type = str,
help='Output anchor directory\n' )
parser.add_argument('-num_clusters', default = 9, type = int,
help='number of clusters\n' )
args = parser.parse_args()
if not os.path.exists(args.output_dir):
os.mkdir(args.output_dir)
# f = open(args.filelist)
#
# lines = [line.rstrip('\n') for line in f.readlines()]
annotation_dims = []
size = np.zeros((1,1,3))
for root, dirs, files in os.walk(r"E:\scripts\VOCdevkit\VOC2020\labels"):
for file in files:
# 获取文件路径
fileName = os.path.join(root, file)
print(fileName)
f2 = open(fileName)
for line in f2.readlines():
line = line.rstrip('\n')
w, h = line.split(' ')[3:]
print(w,h)
annotation_dims.append(tuple(map(float, (w, h))))
annotation_dims = np.array(annotation_dims)
# for line in lines:
#
# #line = line.replace('images','labels')
# #line = line.replace('img1','labels')
# #line = line.replace('JPEGImages','labels')
#
#
# #line = line.replace('.jpg','.txt')
# l#ine = line.replace('.png','.txt')
# print(line)
# f2 = open(line)
# for line in f2.readlines():
# line = line.rstrip('\n')
# w,h = line.split(' ')[3:]
# #print(w,h)
# annotation_dims.append(tuple(map(float,(w,h))))
# annotation_dims = np.array(annotation_dims)
eps = 0.005
if args.num_clusters == 0:
for num_clusters in range(1,11): #we make 1 through 10 clusters
anchor_file = join( args.output_dir,'anchors%d.txt'%(num_clusters))
indices = [ random.randrange(annotation_dims.shape[0]) for i in range(num_clusters)]
centroids = annotation_dims[indices]
kmeans(annotation_dims,centroids,eps,anchor_file)
print('centroids.shape', centroids.shape)
else:
anchor_file = join( args.output_dir,'anchors%d.txt'%(args.num_clusters))
indices = [ random.randrange(annotation_dims.shape[0]) for i in range(args.num_clusters)]
centroids = annotation_dims[indices]
kmeans(annotation_dims,centroids,eps,anchor_file)
print('centroids.shape', centroids.shape)
if __name__=="__main__":
main(sys.argv)
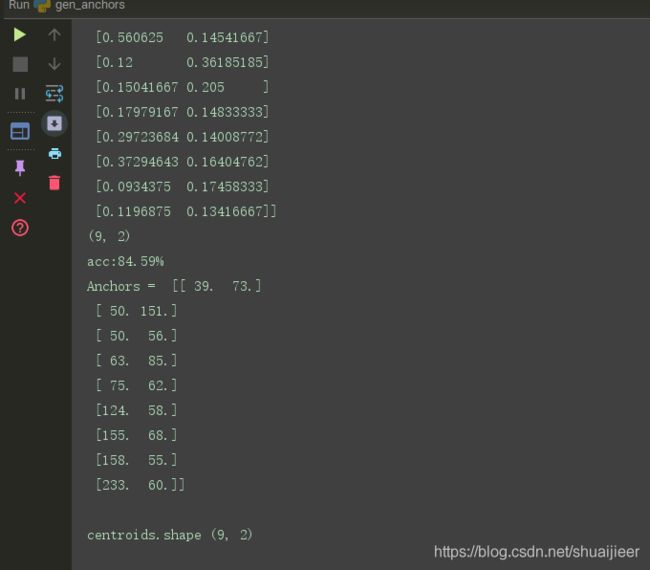
程序运行结果: