【NLP】基于神经网络PCNN(Piece-Wise-CNN)的关系抽取模型
背景
关系抽取是信息抽取的基本任务之一,对于知识库的构建以及文本的理解十分重要,在自然语言处理的一些任务,如问答,文本理解等得到了广泛的应用。
这里介绍的关系抽取主要指的是实体之间的关系抽取,实体是之前NER任务中介绍的概念。实体之间可能存在各式各样的关系,关系抽取就是通过自动识别实体之间具有的某种语义关系。有的实体之间可能有多种关系,例如“徐峥自导自演了《人在囧途》”,那么徐峥 和 《人在囧途》 之间的关系就存在“导演”与“参演”两种关系,。这里介绍的是两个实体之间的关系也称为二元关系抽取( Binary Relation Extraction,BiRE)是比较经典的关系抽取任务,我们也称为简单关系抽取。近些年随着关系抽取场景的变化,慢慢衍生出需要复杂关系抽取(Complex Relation Extration,CoRE),如:多个实体之间的关系抽取,即多元关系抽取,文档关系抽取,多模态关系抽取,嵌套关系抽取等等。
目前的在深度学习领域关系抽取方法主要分为三大类:基于监督学习的BiRE(Supervised BiRE)、基于半监督学习的(Semi-supervised BiRE)以及基于远程监督的BiRE(Distant Supervised BiRE)。毕竟在工程中,标注数据并不是那么多,成本高。对于有监督的关系抽取任务,通常也将其分为两大类
Pipline: 将实体抽取与关系抽取分为两个独立的过程,关系抽取依赖实体抽取的结果,容易造成误差累积;Joint Model: 实体抽取与关系抽取同时进行,通常用模型参数共享的方法来实现。
关系抽取还可以按照业务领域分为:限定领域和开放领域两类。限定领域关系抽取,指在一个或多个限定的领域内对实体间的语义关系进行抽取。一般来说,在限定领域下,关系都是预先定义好的有限个类别,该任务可以采用基于监督学习的方法来处理,也就是针对每个关系类别标注足够多的样本,然后使用多分类模型来训练关系抽取模型;开放领域关系抽取,该任务不限定关系的类别,也就是在抽取关系之前不知道会有什么样的关系被抽取到,依据模型对自然语言句子理解的结果从中开放式的抽取实体三元组。
传统的解决方案可以通过书写规则(模板)的方式确保关系抽取的准确性,但是召回效果并不理想,并且还需要人工去总结归纳。
当然关系抽取也有很多难点,如:
- 同一关系可由不同的词语表达。
- 同一短语或词具有歧义性,不能很好的表征同一关系。
- 实体对间可能具有多种关系。
- 跨句多元关系不能很好解决。
- 隐含关系不能很好解决。
- 对nlp处理工具依赖较大等。
下面我就从经典深度学习关系抽取模型开始介绍,Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks(2015年),该论文实在 ACL 2014的中《Relation Classification via Convolutional Deep Neural Network》改进,就是我们所说的PCNN。这是一个pipline形式的模型。
论文阅读
Distant Supervised Learning 远程监督学习
2010年提出Distant Supervision可以自动标注训练样本,Distant supervision for relation extraction without labeled data。原理很简单,利用知识图谱中的两个entity以及对应的某个relation,在corpus中进行回标,如果某个句子中同时包含了两个entity,那么就假定这个句子包含了上述的relation。这样就可以获得大量的标注数据。当然缺陷就是假设太强,会引入了很多噪音数据, 因为包含两个entity的句子不一定可以刻画对应的relation。
正文概览
论文要解决的两个问题:
- Distant supervised 会产生有大量噪音或者被错误标注的数据,直接使用supervised的方法进行关系分类,效果很差。
- 传统的方法大都是基于词法、句法特征来处理, 无法自动提取特征。而且句法树等特征在句子长度变长,正确率会显著下降。
针对第一个问题,文中是这么说的:
To address the first problem, distant supervised relation extraction istreated as a multi-instance problem similar to pre-vious studies 。In multi-instance problem, the training set consists of many bags,and each contains many instances. The labels of the bags are known; however, the labels of the in-stances in the bags are unknown. We design an objective function at the bag level. In the learning process, the uncertainty of instance labels can be taken into account; this alleviates the wrong label problem。
概括起来就是,对样本使用Multi-Instance Learning(MIL),构建了一个bag级别的目标函数。如何理解这个MIL呢,可以参考:
设想有若干个人,每个人手上有一个钥匙串(bag),串有若干个钥匙(instance)。已知某个钥匙串能否打开特定的一扇门(training set)。我们的任务是要学习到哪一串钥匙串能打开这扇门,以及哪个钥匙能打开这扇门。
针对第二个问题,概括来说,就是在Zeng 2014 的CNN基础上修改了Pooling的方式,调整了特征提取方案,根据实体位置将一个sentence分成三段,每段单独进行max pooling以进行特征提取。
具体模型
模型主要分为四个模块:Vector Representation,Convolution,Piecewise Max PoolingandSoftmax Output,如下图:
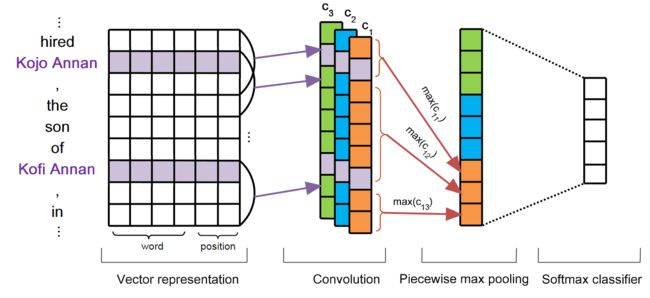
Vector Representation
NLP中文本常规操作,将文本转成低纬度的向量。词语使用的是预训练的词向量(Word Embeddings),此外还未对应的词语添加了position feature(PF),也就是位置向量(Position Embeddings)。这个PF的构建还是比较有意思的,位置的设定取与关系词的相对距离,如下图:Kojo Annan 相对于关系吃son,左边第三个,以此类推,Kofi Annan则是在关系词son右边第二个开始。

假设词向量的维度为 d w d_w dw,位置信号的维度为 d p d_p dp,拼接后的向量维度 d = d w + d p × 2 d=d_w+d_p \times 2 d=dw+dp×2。
Convolution
卷积计算是一个比较经典的操作了,也比较容易理解。为了提高捕捉特征的能力,可以在卷积操作中增加多个卷积核或者称为filter的家伙。想谅解相关的计算公式可参见原文。
Piecewise Max Pooling
分段池化应该属于论文中的一个亮点。就是把每个卷积核得到向量 c i c_i ci按照两个实体的位置将向量划分三个部分,然后使用最大池化的方式取出每个部分的最大值,相比于传统的全局max pooling 每个卷积核只能得到一个值,这样可以更加充分有效的得到句子特征信息。每个通道经过分段最大池化后,再拼接成一个向量,最后再与其他通道的向量拼接起来,再经过一个非线性层。
Softmax Output
深度学习分类常规操作层,添加softmax函数,对各个类别进行打分输出。
Multi-instance Learning
多实例学习。在训练的过程中需要设计学习的目标函数,也就是我们常说的损失函数的构造。模型输入是一个bag。假设有个 T T T个bag { M 1 , ⋯ , M T } \{M_1,\cdots, M_T\} {M1,⋯,MT},第 i i i个bag有 q i q_i qi个实例 M i = { m i 1 , ⋯ , m i q i } M_i=\{ m^1_i, \cdots, m_i^{q_i}\} Mi={mi1,⋯,miqi},即有 q i q_i qi个句子。下面我们看看如何构造这个目标函数。
一个bag中所有的实例都认为是独立的。包含两个同样实体的实例就是一个bag,按照远程监督的情况样本处理的方式,认为一个bag有一个relation标签。
对于一个实例 m i j m_i^j mij经过模型后输出的结果为 o o o。这个结果的维度是与关系类别想对应的,包含 o r o_r or表示对第 r r r个类别的打分,文章这个打分是未经过softmax处理的。经过softmax处理后的打分如下:
p ( r ∣ m i j ; θ ) = e o r ∑ k = 1 n 1 e o k p\left(r \mid m_{i}^{j} ; \theta\right)=\frac{e^{o_{r}}}{\sum_{k=1}^{n_{1}} e^{o_{k}}} p(r∣mij;θ)=∑k=1n1eokeor
多实例学习的目的是区分bag而不是实例,于是需要定义bag级别的目标函数。对于训练集 ( M i , y i ) (M_i, y_i) (Mi,yi)来说,目标函数在bag级使用的是交叉熵损失函数:
J ( θ ) = ∑ i = 1 T log p ( y i ∣ m i j ; θ ) J(\theta)=\sum_{i=1}^{T} \log p\left(y_{i} \mid m_{i}^{j} ; \theta\right) J(θ)=i=1∑Tlogp(yi∣mij;θ)
其中, T T T表示训练集(bag)数目, θ \theta θ表示模型。看起来这个和普通的分类损失函数没有什么不同,需要注意的是上式中的 j j j是有限制的,如下:
j ∗ = arg max j p ( y i ∣ m i j ; θ ) 1 ≤ j ≤ q i j^{*}=\arg \max _{j} p\left(y_{i} \mid m_{i}^{j} ; \theta\right) \quad 1 \leq j \leq q_{i} j∗=argjmaxp(yi∣mij;θ)1≤j≤qi
从bag中选取标注结果打分最高的实例进行误差反向传播的计算。这里也从侧面说明了,默认每一个bag中必有一个实例的标注是正确的,即所谓的at least one假设。
到这里,整个模型已经介绍完毕了。
论文结论
首先把PCNNs结合多实例学习的远程监督模型(PCNNs+MIL),与人工构造特征的远程监督算法(记为Mintz)和多实例学习的算法(记为MultiR和MIML)进行比较。
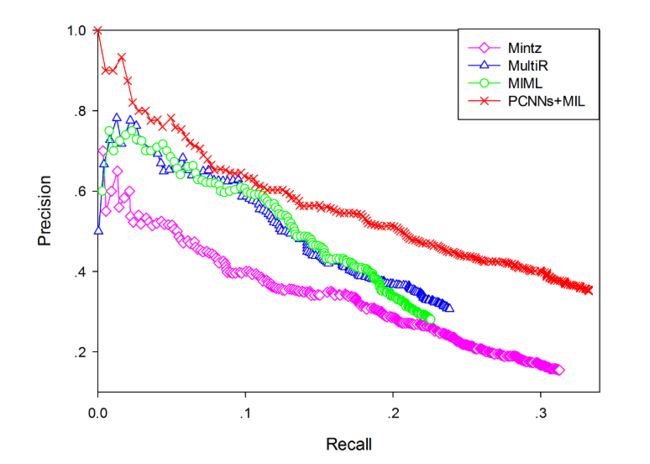
上图中,根据纵横坐标的意义,值在坐标系的右上角效果越好。从实验结果中可以看到,无论是查准率还是查全率,PCNNs+MIL模型都显著优于其他模型,这说明用卷积神经网络作为自动特征抽取器,可以有效降低人工构造特征和NLP工具提取特征带来的误差。即在问题二上有一定的改善。
将分段最大池化和普通的最大池化的效果进行对比(PCNNs VS CNNs),将结合多实例学习的卷积网络与单纯的卷积网络进行对比(PCNNs+MIL VS PCNNs)。
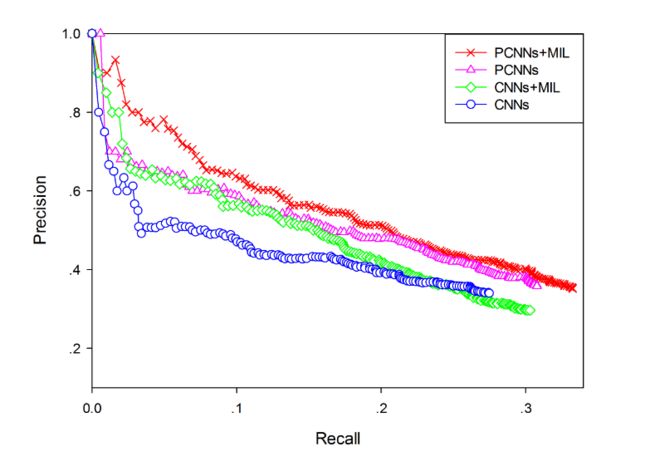
从结果可以看出,分段最大池化比普通的最大池化效果更好,说明分段最大池化可以抽取更丰富的结构特征。把多实例学习加入到卷积网络中,效果也有一定的提升,表明多实例学习可以缓解样本标注错误的问题。这说明针对问题1和问题2都已一定的改善。
总结
总得来说,在限定域的pipline形式的关系抽取中,使用分段的最大池化能够减少人为特征提取的操作,再引入远程监督的内容后,使用多实例学习的方式在一定程度上也能够减少远程监督引入的错误,使得关系抽取的整体效果达到当时的sota水平。
当然也存在不足之处,多实例学习仅从某个实体对句子中挑选最可能的句子进行反向传播计算,这也必然造成信息的大量损失。