CIKM'21「华为」推荐系统 | 因果推断+强化学习:反事实用户偏好模拟
![]()
![]()
![]()
点击蓝字关注,提升学习效率

![]()
title:Top-N Recommendation with Counterfactual User Preference Simulation
link:https://dl.acm.org/doi/pdf/10.1145/3459637.3482305
from:CIKM 2021
1. 导读
对因果推断和反事实推断不熟悉的小伙伴可以阅读相关文章
文中涉及变分推断,可参考这篇阅读:https://zhuanlan.zhihu.com/p/70644599
SIGIR'21 因果推断+推荐系统:利用反事实理论增强用户行为序列数据
SIGIR'21 因果推断+序列推荐:反事实数据促进鲁棒用户表征生成
上面这两篇文章都是利用反事实推断,来生成更丰富的序列数据的文章。本文和这两篇文章有类似之处,本文也是利用反事实推断来生成数据,缓解数据稀疏和不平衡问题。不同之处在于,上述两篇文章都是用反事实推断的思想来对序列推荐中的用户行为序列数据进行生成,而本文是对通用的top-N推荐。
本文结合因果推断框架,利用反事实模拟用户基于排名的偏好来处理数据稀缺问题,提出CPR方法。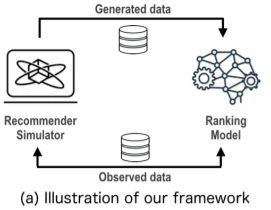 如图所示为本文所提方法的总体框架,主要包含两个部分:推荐模拟器和目标排序模型。排序模型用于提供最终推荐列表,推荐模拟器旨在通过生成额外的训练样本来辅助排名模型的优化。
如图所示为本文所提方法的总体框架,主要包含两个部分:推荐模拟器和目标排序模型。排序模型用于提供最终推荐列表,推荐模拟器旨在通过生成额外的训练样本来辅助排名模型的优化。
2. 定义
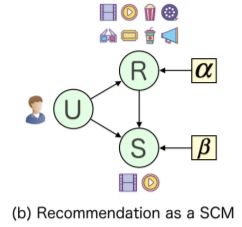 以上为通常情况下的因果图,其中存在混杂因子R。U表示用户画像,R表示推荐列表,S表示用户真实从R中选择的集合。
以上为通常情况下的因果图,其中存在混杂因子R。U表示用户画像,R表示推荐列表,S表示用户真实从R中选择的集合。
3. 方法
CPR框架由两部分组成:一是推荐模拟器,负责生成新的训练样本。另一个是目标排名模型,它是根据观察到的和生成的数据学习的,并用来提供最终的推荐列表。框架可以应用于任何基于排名的推荐模型。
3.1 推荐模拟器
 如图所示为现有的因果图,U,R,S分别表示用户画像,推荐列表和被用户选择的正样本。U->R表示推荐列表是根据用户偏好生成的,U->S和R->S表示正样本是用户偏好和推荐列表共同决定的。结构方程为下式,其中U,R,S为内源性变量;α,β为外源性变量。
如图所示为现有的因果图,U,R,S分别表示用户画像,推荐列表和被用户选择的正样本。U->R表示推荐列表是根据用户偏好生成的,U->S和R->S表示正样本是用户偏好和推荐列表共同决定的。结构方程为下式,其中U,R,S为内源性变量;α,β为外源性变量。
note:
考虑推荐系统内在的噪声和随机性,PR和PS都以随机方式定义,以此学到更加准确和鲁棒的行为。
推荐系统中的外源性变量可以理解为诱导当前观察到的数据的条件,如系统状态、用户习惯等
例子:以电影推荐为例,用户可能更有可能在闲暇时间看电影。所以如果是晚上采集的数据,那么电影点击概率应该会更高。这种时间条件是潜在的,但会影响数据生成过程,预计会被外源变量捕获,并通过推断相应的后验来恢复。
3.1.1 构建结构方程F
假设存在个商品,则推荐列表存在中可能,这个数是很大的,因此作者将其分解为单个商品推荐概率的乘积。公式如下,其中表示推荐列表,列表中单个商品的推荐概率用softmax来计算,和表示用户和商品的embedding,他们可以用ID或各自的画像信息来初始化,表示可学习参数。
表示从推荐列表R中选择S的概率,公式如下,其中表示S的集合,w为可学习参数,X和Y为用户和商品的embedding。
在pr和ps中用户和商品的embedding是不同的。
3.1.2 F的学习
假设训练集为,分别表示用户,对应的推荐列表和选择集合,由于商品集市非常庞大的,因此无法直接优化的softmax函数。因此利用负采样,公式如下,其中为可学习参数,表示负样本的集合,从非推荐列表中随机采样得到。从标准正太分布中采样得到。
对于而言,是在推荐列表R的基础上,R本身集合大小不大,因此可以直接进行优化。其中为可学习参数,,分别表示在,中的第t个和第j个。
3.1.3 基于F的反事实推断
第一步:根据观察到的数据集,计算外源变量α,β。对于β,可用下面的贝叶斯公式计算,其中可以用上面计算的公式计算得到。
但是如果要从下式采样出β还是太复杂了,因此本文采用变分推理。首先定义高斯分布,其中φ={μ,σ}为可学习参数。然后,通过最小化和的KL散度来优化,其中需要最大化ELBO,公式为下式,
同样也可以用相同方式得到,具体可以参考文献[1]中的变分推断。第二步:选择好一个用户和推荐列表,然后从中采样出,可以计算ps,公式如下:
第三步:从集合中选出概率最高的M个商品作为s。
3.2 基于学习的干预
上述过程我们对R进行了干预,从而来达到反事实的推断的效果。那么这里存在一个问题,如何得到。本节,作者提出基于学习的方法来选取推荐列表。思想:使生成的样本对目标排名模型具有更多信息。在文献[2,3]中可知,损失函数大的样本,给模型提供的信息就越多。这和难样本挖掘方面的思想是类似的,处于边界的样本,难训练的样本往往能提供更多的信息。
采用上述思想,作者在这里采用了强化学习的方式。将目标排序模型的损失作为奖励,构建可学习的方法。
令排序模型为f,对应的损失为,他可以是常用的point-wise的损失也可以是pair-wise的损失。而动作就是生成推荐列表,智能体agent需要做的就是生成能够使更大的推荐列表。考虑到动作空间可能非常大,作者按照之前的工作[4]学习高斯策略来生成的连续商品中心,然后根据等式的计算公式恢复离散商品ID。最终的学习目标是:
其中π是有两层全连接层加上ReLU得到的高斯策略。表示目标用户,表示生成的样本对应的损失。生成T组训练样本集合,每个都由下式得到,具体如下:
基于分数,在商品中心附近选取K个商品来生成
根据,从中选取M个商品作为集合
对于pair-wise的损失函数,;对于point-wise的损失函数,。
以下为所提方法的伪代码,具体来说,目标排序模型首先基于原始数据集进行训练。然后,基于高斯策略生成许多反事实训练样本。最后,基于生成的数据集重新训练目标排序模型。
4. 结果
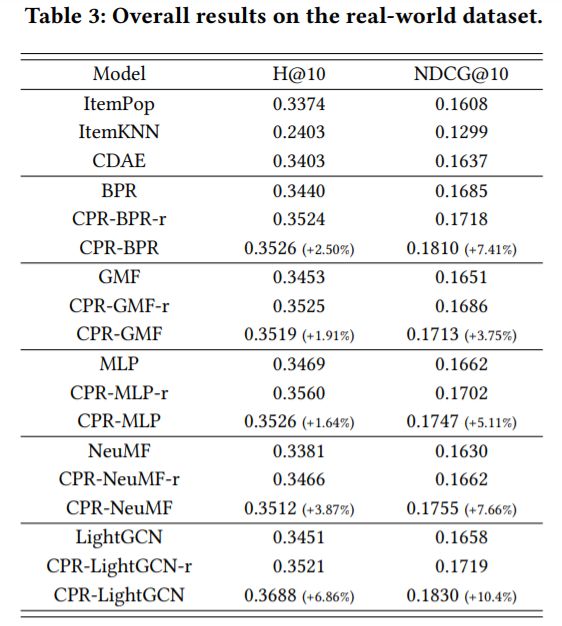 image.png
image.png
文献
[1] David M Blei, Alp Kucukelbir, and Jon D McAuliffe. 2017. Variational inference: A review for statisticians. Journal of the American statistical Association 112, 518 (2017), 859–877 [2] Tsu-Jui Fu, Xin Eric Wang, Matthew F Peterson, Scott T Grafton, Miguel P Eckstein, and William Yang Wang. 2020. Counterfactual Vision-and-Language Navigation via Adversarial Path Sampler. In European Conference on Computer Vision. Springer, 71–86
[3] Hongchang Gao and Heng Huang. 2018. Self-paced network embedding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1406–1415.
[4] Xiangyu Zhao, Liang Zhang, Long Xia, Zhuoye Ding, Dawei Yin, and Jiliang Tang. 2017. Deep reinforcement learning for list-wise recommendations. arXiv preprint arXiv:1801.00209 (2017)