python图片切割以及识别图片中的文字
今天记录在爬取图片网站时,需要按如下需求展示图片和答案:

本次爬取数据量不大,爬取内容也都集中在一个页面,网站也没有异步加载或反爬措施,但是遇到了三个难点:
难点一:图片链接是lazyload,且全部151条图片链接,分散在两个模块下,第一个模块’//div[@class=“entry-content”]/figure/img’的43条图片链接数据爬取顺利,第二个模块’//div[@class=“entry-content”]/p/img’下的108条图片链接却总是显示只能爬取到第一条数据:
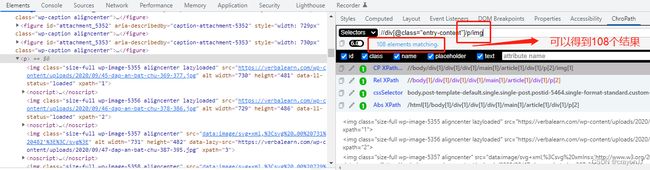
如上图,xpath定位没有问题,但结果却总是只有一条数据,暂时还没有搞清楚为什么,最后改成’//div[@class=“entry-content”]//img’来定位,可以直接两个模块下的链接一起爬取,反而更方便,只是这样的结果多出一条数据(最后一条数据),由于只多出一条,便未修改代码逻辑,直接手动去掉了,爬取图片到本地的代码如下:
import requests
from lxml import etree
import time
url = 'https://verbalearn.com/game-tri-tue/dap-an-duoi-hinh-bat-chu/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'}
img_list = list()
req = requests.get(url,headers=headers)
print(req.status_code)
html = etree.HTML(req.text)
path = '//div[@class="entry-content"]//img'
results = html.xpath(path)
print(len(results))
for result in results:
try:
img_text = result.xpath('./@data-lazy-src')
img_text1 = img_text[0].strip()
print(img_text1)
img_list.append(img_text1)
except IndexError:
continue
print(img_list)
for img_url in img_list:
img_resp = requests.get(img_url)
img_name = img_url.split("-chu-")[-1] # 如果没有提前剔除掉最后一条不要的数据,这里需要增加try...except来跳过最后一条数据
print(img_name)
with open("img1/"+img_name,mode="wb") as f:
f.write(img_resp.content)
print("over!",img_name)
time.sleep(1)
难点二:图片的切割操作。由于几张图片共用一个链接,所以需要对图片切割后才能得到单独的图片,这里有两个地方需要处理:
1,图片既有.jpg 格式,又有.png格式,需要统一,且之前的代码只是用img_name = img_url.split(“-chu-”)[-1] 切片操作来命名,图片的命名比较不美观,这里需要先对所有图片进行批量重命名;
2,共享一个链接的图片数量不一致,有些是6张共享一个链接,有些是9张共享一个链接,这里由于数据量不大,直接手动分类。将其按照数量分成了4个分类放在不同的文件夹下:
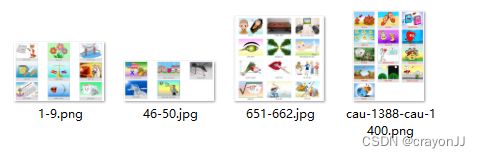
处理过程:
1,图片批量重命名:如上图所示,命名极其杂乱。首先将后缀全部统一成.jpg格式:在图片文件夹下创建一个.bat文件,在文件中写入ren *.png *.jpg代码,之后双击.bat,即可将所有图片后缀改成.jpg格式;然后重命名,由于需求没有要求爬取的图片按照网站图片顺序显示,且最后用到的是切割后的小图片,所以可以直接重命名,直接按1,2,3…这样的顺序重命名151个图片文件即可(这里肉眼发现1419-1430的图片和1449-1460的图片重复,唉,牛逼网站这么不规律,直接手动删除了,还剩150条数据)

批量重命名:
- 1,先全选图片,鼠标随便放在一张图片上,右键重命名,命名为new.jpg,安心enter键,之后所有图片变成new(1).jpg,new(2).jpg的命名;
- 2,再全选图片,选中一张照片,先空格,再enter,之后所有图片变成(1).jpg,(2).jpg,的命名;
- 3,去掉括号:在当前文件夹下创建一个.bat文件,里面代码如下:之后双击运行.bat文件,即去掉所有的括号。
@Echo Off&SetLocal ENABLEDELAYEDEXPANSION
FOR %%a in (*) do (
echo 正在处理 %%a
set "name=%%a"
set "name=!name:(=!"
set "name=!name:)=!"
ren "%%a" "!name!"
)
exit
2,切割图片:由于图片有4个分类(暂时还没有识别图片有几张小图片,然后自动切割的方法,后面深入学习后看看能否自动识别),只能分成4个文件夹分别切割,代码如下:
import cv2
import os
heightCutNum = 2; # 高度切割,4个分类分别放在2,3,4,5这四个文件夹下,分别有2,3,4,5行,四次分割修改这里的数字即可
widthCutNum = 3;
inPath = "D:/python/code/Test/TestScrapy/img/2/" #四次分割修改这里的文件路径
outPath = "D:/python/code/Test/TestScrapy/img/new/"
for f in os.listdir(inPath):
path = inPath + f.strip()
print(path)
img = cv2.imread(path)
height = img.shape[0] # The size of each input image
width = img.shape[1]
heightBlock = int(height / heightCutNum) # The size of block that you want to cut
widthBlock = int(width / widthCutNum)
for i in range(0, heightCutNum):
for j in range(0, widthCutNum):
cutImage = img[i * heightBlock:(i + 1) * heightBlock, j * widthBlock:(j + 1) * widthBlock]
savePath = outPath + f.strip().replace(".jpg","") + "_" + str(i) + str(j) + ".jpg"
cv2.imwrite(savePath, cutImage)
最终切割结果如下:

可以看到结果基本满足要求,但是还是有一个问题,对于一个链接里面的图片不是3的倍数的图片,就会有如图7_12.jpg这样的空图片,由于切割后的图片数量达到1425条,还是有一定的量,就不手动剔除了,后面在图片识别的时候做逻辑判断踢掉吧。
难点三:图片识别提取答案文字。根据上文的图片得知,网页源代码里面根本没有答案文字信息,所有答案直接在图片里面,只能通过图片文字识别来获得答案。而且要识别的文字还是越南语(唉,垃圾网站)
安装easyocr库:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple easyocr
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchaudio
通过镜像安装,没有遇到什么阻碍,但是运行越南语示例代码时,下载语言模型时总是出错:
reader = easyocr.Reader(['vi'],gpu=False)
result = reader.readtext('1_00.jpg')
print(result)
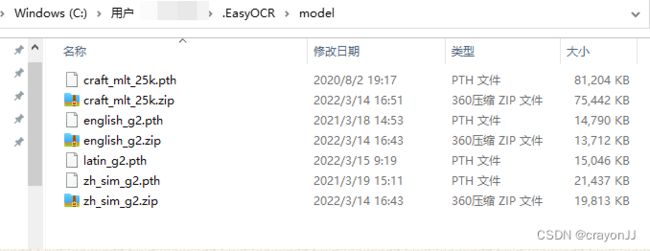
原因是只将解压后的.pth文件放C:\Users\jingjing.EasyOCR\model路径,却没有放.zip包;需要将.zip包和.pth都放该路径下才能正常运行:
图片文字识取完整代码如下:
import os
import easyocr
dic_set = dict()
inPath = "D:/python/code/Test/TestScrapy/img/new/"
bg = op.load_workbook(r'write.xlsx')
sheet = bg["Sheet1"]
i = 1
for f in os.listdir(inPath):
path = inPath + f.strip()
name = f.strip().replace(".jpg","")
reader = easyocr.Reader(['vi'],gpu=False)
result = reader.readtext(path)
print(name + ":")
try:
output = result[0][1]
except:
output = '未识别到图片'
print(output)
sheet.cell(i,1,name)
sheet.cell(i,3,output)
i = i + 1
bg.save("write.xlsx")
print('over!')
更多关于easyocr图片识别的使用可以看另一篇博客:easyocr快速安装及图片文字提取演示(小语种)