ASFformer模型简述
目录
提出问题
问题的解决方案
基本模型
Encoder
Decoder
单一解码器
多头解码器
数据集
评估指标
具体实验
提出问题
transformer最初是为机器翻译任务设计的,在过去的几年里,它在几乎所有的自然语言处理(NLP)任务中都取得了出色的性能。最近,许多研究人员也展示了纯或混合Transformer模型在许多视觉任务中的潜力,包括图像分类,动作分类等。
动作分割任务与NLP任务类似,都是序列到序列的预测任务。随着基于transformer的模型在序列数据中元素之间关系建模方面的成功,人们可以期望基于transformer的模型对于动作分割任务也非常有效。然而,在用普通Transformer解决动作分割任务时,有三个主要问题:
1.由于训练集规模小,vanilla Transformer缺乏归纳偏差。
2.对于较长的输入视频,由于缺乏自我注意,一个Transformer模型中的各个自注意层之间很难相互协作,形成对输入的有效表示。
3.transformer原有的编码器-解码器结构不能满足动作分割任务的细化需求。
因此本文提出一种ASFormer模型用来解决以上三个问题。
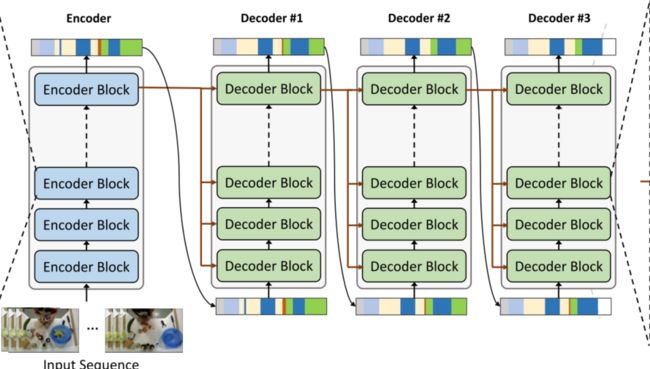
如上图为ASFormer总体模型,该模型由一个编码器和几个解码器组成,用于执行迭代细化。对于编码器,它接收视频序列并输出初始预测。编码器由一系列具有预定义层次表示模式的编码器块组成。对于解码器,它接收预测作为输入,并具有与编码器相似的架构。
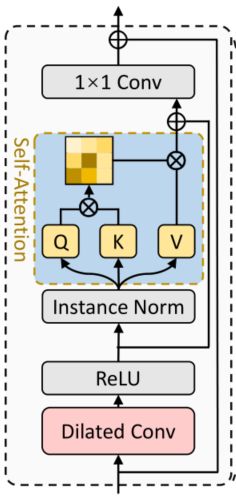
上图为每个编码器块,由前馈层(扩张时间卷积)和带有剩余连接的自注意层组成。

上图为解码器块,使用交叉注意机制从编码器引入信息。交叉注意机制允许编码器中的每个位置在细化过程中对所有位置进行关注,同时避免了编码器在细化阶段对学习到的特征空间的干扰。
问题的解决方案
对于第一个问题,动作分割任务的一个属性是特征的高局部性,因为每个动作都占用连续的时间戳,故局部连通性归纳偏差对动作分割任务很重要。它将假设空间约束在一个可靠的范围内,有利于用较小的训练集学习合适的目标函数。我们通过在每一层中应用额外的时间卷积来引入这种强归纳先验。
对于第二个问题,用预定义的分层表示模式约束每个自注意层,迫使低层次的自注意层首先关注局部关系,然后逐渐扩大其足迹,以捕获较长的高层依赖关系。local-to-global流程为每个自我关注层分配了特定的职责,以便它们能够更好地合作,以实现更快的收敛速度和更高的性能。这种分层表示模式还降低了总空间和时间复杂度,使模型具有可扩展性。
对于第三个问题,本文提出了一种新的解码器设计,以获得精细化的预测。
基本模型
Encoder
编码器的输入是预先提取的大小为T ×D的特征序列,其中T为视频长度,D为特征维数。编码器的第一层是一个完全连接的层,它可以调整输入特征的维度。然后,这一层后面是一系列编码器块。在此之后,一个完全连接的层将从最后一个编码器块输出预测ye∈RT ×C,其中C表示动作类的数量。
每个编码器块包含两个子层。第一个是前馈层,第二个是单头自注意层。我们在两个子层周围都使用了一个残差连接,然后是实例规范化和ReLU激活,如上图所示。与普通的Transformer不同,我们使用一个扩展的时间卷积作为前馈层,而不是全连接层。
自注意层很难学会在数千帧中关注有意义的位置。对于一个输入视频,这些自注意层之间很难相互配合形成有效的表示。为了缓解这个问题,本文预先定义了一个层次表示模式,将每个自注意层的接受域限制在一个大小为w的局部窗口内(例如,对于一个框架t,只计算其局部窗口内的框架的注意权重)。然后,本地窗口的大小在每层i加倍(即w = 2i,i = 1,2…)同时,随着编码器深度的增加,同时将时间卷积层的扩张速率提高一倍,与自注意层保持一致。
ASFormer的分层表示模式使得空间复杂度大大降低,因此更适用于接受长输入序列。
Decoder
单一解码器
解码器的输入是编码器输出的初始预测。解码器的第一层是全连接层,用于调整尺寸,然后是一系列的解码器块。与编码器类似,我们使用时间卷积作为前馈层,交叉注意层也采用分层模式。
交叉注意与自我注意层相比有以下区别:查询Q和键K是由编码器和上一层的输出拼接而来,而值V仅从上一层的输出中获得。
交叉注意机制允许编码器中的每个位置通过生成注意权重来关注细化过程中的所有位置。特征空间V完全由输入预测转换而来,不会受到编码器参与者的干扰,因为生成的注意力权重仅用于在V内进行线性组合
多头解码器
每个解码器的输入都是前一个解码器的输入,从上图总体模型中可看出。
本文的ASFormer由一个编码器和三个解码器组成,而每个编码器和解码器包含9个块。
数据集
本文采用的数据集为50Salads、GTEA和Breakfast。
对于所有三个数据集,我们使用I3D模型,它是在动力学数据集上训练的,像以前的工作那样预提取特征序列。
评估指标
本文采用的评估指标为帧级精度、分段编辑分数和分段重叠F1分数与阈值k/100。
具体实验
(正在看)