MySQL数据库 学习笔记&面试题
常见问题
-
MySQL安装教程
-
输入
net start mysql无法启动
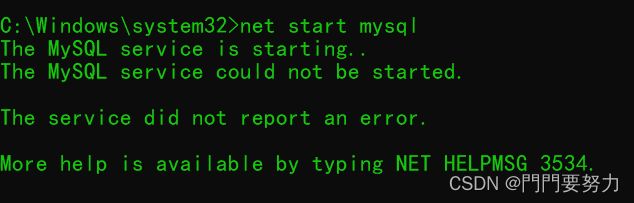
3306端口被占用,输入netstat -ano查看使用3306端口号的进程pid,然后taskkill /f /pid ***pid号结束进程
数据库概述
| DB(DataBase 数据库) | 保存特定规格的数据 |
| DBMS(DataBase Management System | 数据库软件,数据库管理系统,如oracle, SQL server, MySql |
| SQL(Structured Query Language) | 用于与数据库通信,是一套标准,每个数据都有其特性 |
| SQL语句分类 | 关键字 |
|---|---|
| 数据查询语言(DQL-Data Query Language) | select |
| 数据操纵语言(DML-Data Manipulation Language) | insert,delete,update |
| 数据定义语言(DDL-Data Definition Language) | create ,drop,alter, |
| 数据控制语言(DCL-Data Control Language) | grant,revoke. |
| 事务控制语言(TCL-Transactional Control Language) | commit ,rollback; |
cmd中用MySQL命令行操作数据库
| cmd指令 | 说明 | |
|---|---|---|
| 查看版本 | mysql --version |
|
| 连接MySQL | mysql -u root -p*** |
(可直接加密码enter) |
| 创建新数据库 | create database ***; |
|
| 选择数据库 | use ***; |
|
| 导入数据库 | source path.sql; |
(需要先创建数据库,然后执行.sql文件 sql脚本文件中编写了大量sql语句,执行脚本时,文件中所有sql语句执行 |
| 查看当前库中的表 | show tables; |
|
| 查看表的结构 | desc ***; |
|
| 删除数据库 | drop database ***; |
|
| 查看当前使用数据库 | show database(); |
|
| 退出 | \q; ctrl+c |
1. 查询语句 DQL
DQL语句只负责查询,不会修改数据库
// 查询的完整语法
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段
HAVING
分组后条件
ORDER BY
排序字段
LIMIT
分页限定;
1. 简单查询语法
| 查询语法 | ||
|---|---|---|
| 查询字段 | select 字段列表 from 表名; |
一个或多个 |
| 查询全部字段 | select * from 表名; |
(效率低,可读性差,相当于转化为所有字段,编程时不适用) |
| 去除重复记录 | SELECT DISTINCT 字段列表 FROM 表名; |
|
| 使用as关键字起别名 | select 列名 as 别名 from 表名; |
(只是显示结果,原列名不变) as可省略 |
例:
查询所有姓名性别 :SELECT name,sex FROM stu;
查看所有地址(去重) :SELECT DISTINCT address FROM stu;
查询姓名、数学成绩、英语成绩 :SELECT name,math AS 数学成绩,english AS 英语成绩 FROM stu;
2. 条件查询 WHERE
where必须放在from后 : SELECT 字段 FROM 表名 WHERE 条件列表;
可使用条件运算符:
- >大于, <小于, >=大于等于, <=小于等于 ,=等于,<>或!= 不等于
BETWEEN ... AND ...在某范围内()都包含IN(...)多选一LIKE占位符 模糊查询(_代表单个字符,%代表任意个字符)IS NULL查空 ,IS NOT NULL查非空AND或&& 且,OR或|| ,NOT或! 非
例:
- 查询年大于等于20且小于等于30的同学名字
SELECT name FROM stu WHERE age>=20 ANDage<=30;//AND可换为&&
也可用WHERE age BETWEEN 20 AND 30;- 查询生日在’2000-1-1’到’2001-1-1’之间的同学名字
SELECT name FROM stu WHERE birthday BETWEEN '2000-1-1' AND '2001-1-1';- 查询年龄为18,20或22岁的同学名字
SELECT name FROM stu WHERE age IN (18,20,22);- 查询英语成绩为空的同学名字
SELECT name FROM stu WHERE english IS NULL;//不能用=null- 模糊查询
查询姓赵的同学信息SELECT * FROM stu WHERE name LIKE '赵%';
查询名字中第二个字为海的同学信息SELECT * FROM stu WHERE name LIKE '_海%';
- regexp 正则表达式匹配字符串的使用
‘lgj’:包含lgj
^x:以x开头:‘^lgj’:以lgj开头
x$:以x结尾: ‘lgj$’:以lgj结尾
a|b|c:符合a或b或c都可: ‘lgj|gorgeous’:符合任一条件
[bc]a[nr]:bar,ban,car,can: ‘[LGJ]gorgeous’:字符串中有Lgorgeous,Ggorgeous,Jgorgeous都可
3. 排序查询 ORDER BY
order by排序子句,后面的排序字段可多个,默认升序- 如果存在 where 子句那么 order by 必须放到 where 语句的后面
查询学号在10-20之间的同学信息,按照数学成绩降序排列,若相同,再按学号升序排。
SELECT * FROM stu WHERE id BETWEEN 10 AND 20 ORDER BY math DESC, id ASC;
4. 聚合函数
将一列数据作为整体,进行纵向运算
SELECT 函数名(列名) FROM 表名; NULL值不参与所有聚合运算
| 函数名 | 功能 |
|---|---|
| COUNT( ) | 统计数量(一般选用不含NULL的列) |
| MAX( ) | |
| MIN( ) | |
| SUM( ) | 求和 |
| AVG( ) | 平均值 |
例:
- 统计数学成绩>140的同学数量
SELECT COUNT(id) FROM stu WHERE math>140;- 统计数学成绩>140的同学的语文平均分
SELECT AVG(chinese) FROM stu WHERE math>140;
5. 分组查询 GROUP BY
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];
注意:分组后,查询字段为聚合函数和分组字段,查其他字段没意义
例:
- 查询男女同学各自数学平均分以及人数
SELECT sex,AVG(math),COUNT(*) FROM stu GROUP BY sex;- 要求分数低于70的不参与分组
SELECT sex,AVG(math),COUNT(*) FROM stu WHERE math>=70 GROUP BY sex;- 要求分组后人数大于2的
SELECT sex,AVG(math),COUNT(*) FROM stu WHERE math>=70 GROUP BY sex HAVING COUNT(*)>2;
WHERE与HAVING的区别
- 执行时机:WHERE在分组前限定,不满足条件的不参与分组;HAVING是分组后对结果进行过滤
- 判断条件:WHERE不能对聚合函数进行判断,而HAVING可以
6. 分页查询 LIMIT
SELECT 字段 FROM 表名 LIMIT 起始索引 , 查询条目数;
可以不写起始索引,则直接展示前n条数据
例:查询数学成绩前2-6名
SELECT name FROM stu ORDER BY math DESC LIMIT 1,5;
视图 VIEW
创建视图对象 CREATE VIEW view_name AS DQL查询语句(select...);
删除视图 DROP VIEW view_name;
在数据库中以文件形式存在,存储于硬盘而非内存,可以像使用table一样使用视图,进行增删改查。会导致原表被操作。
作用:简化SQL代码(VIEW引用一堆查询的记录,该查询记录可能反复使用,以后每次使用时直接在VIEW上操作)
2. 操纵语句 DML
对表进行增(INSERT)删(DELETE)改(update)
1. 增加数据
| 增加数据 | 语法 |
|---|---|
| 给指定列增加数据 | INSERT INTO 表名(列名1,列名2……) VALUES(值1,值2……) |
| 给全部列添加数据 | INSERT INTO 表名 VALUES(值1,值2……); |
| 批量添加数据 | INSERT INTO 表名 VALUES(),(),()…; |
2. 修改数据
UPDATE 表名 SET 列名1=值1,列名2=值2… WHERE条件;
例:UPDATE stu SET score=99.99,sex='男' WHERE name='张三';
若没有加where条件,会将表中所有数据全部修改
3. 删除数据
DELETE FROM 表名 WHERE条件;
DELETE FROM stu WHERE NAME = '张三';
直接delete from stu会删除表中所有数据
删除符合条件的多行
DELETE FROM detail WHERE bill_id IN (SELECT bill_id FROM bill WHERE bill_date < '2021-10-05');
3. 定义语句 DDL
用于定义数据库对象:数据库、表、列等
| 操作 | DDL语法 |
|---|---|
| 创建数据库 | CREATE DATABASE ***; |
| 创建数据库(判断,不存在则创建) | CREATE DATABASE IF NOT EXISTS **; |
| 删除数据库 | DROP DATABASE **; |
| 删除数据库(判断,存在则删除) | DROP DATABASE IF EXISTS **; |
| 使用数据库 | USE ***; |
| 查看当前使用的数据库 | SELECT DATABASE(); |
| 修改表名 | ALTER TABLE 原名 RENAME TO 新表名; |
| 添加一列 | ALTER TABLE 表名 ADD 列名 数据类型; |
| 修改数据类型 | ALTER TABLE 表名 MODIFY 列名 新数据类型; |
| 修改列名与数据类型 | ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型; |
| 删除列 | ALTER TABLE 表名 DROP 列名; |
复制表:复制后的表会忽略列的属性,只复制值
CREATE TABLE saler_copy AS SELECT * FROM saler;
创建表
CREATE TABLE user(
id int,
username varchar(20),
password varchar(32)
);
MySQL数据类型
| 数据类型 | 说明 |
|---|---|
| 数值 | 1. tinyint小整数(一字节) 2. int大整数(四字节) 3. double浮点数 score double(5,2),总长度5,保留2位小数 |
| 日期 | 1. date日期(只包含年月日)birthday date, 2. datetime日期时间(包含年月日时分秒) |
| 字符串 | 1. char(-) 定长字符串(存储性能高但浪费空间) 2. varchar(-)(节约空间但存储性能低) |
数据表设计时,字段数据类型选用
学号/编号 id int,
姓名 name varchar(10), #姓名最长不超过10汉字
性别 gender char(1),
生日 birthday date,
成绩 score double(5,2), #小数点后保留两位
邮件 email varchar(15),
电话 tel varchar(15), #不一定是手机号,可能有字符
状态 status tinyint, #状态较少,数字表示
4. 控制语句 DCL
约束
创建表时,给表中的列加上约束,保证表中数据的有效性、完整性。
- 列级约束:约束写在字段后面
- 表级约束:需要给多个字段联合起来添加一个约束
| 约束类型 | 关键字 | 解释 |
|---|---|---|
| 非空约束 | not null |
保证列中所有数据不能有null值 |
| 唯一性约束 | unique |
保证列中所有数据各不相同 联合唯一 unique(列1, 列2) |
| 主键约束 | primary key (PK) |
主键是每一行记录的唯一标识,任何表都有且只有一个主键 |
| 外键约束 | foreign key (FK) |
让两个表的数据之间建立链接 |
| 检查约束 | check |
保证列中的值满足某一条件 (mysql不支持,Oracle支持) |
1. 主键约束
主键值是每一行记录的唯一标识,一般用int、bigint、char(定长),不用varchar
主键的特征:unique + not null
某个字段被not null与unique 联合后,自动成为主键字段
id int not null unique,
drop table if exists ctm;
create table ctm(
id int primary key,
name varchar(255),
age int,
);
主键分类
- 单一主键:一个字段做主键
- 复合主键:多个字段联合做主键
primary key(id,name),(实际开发中不建议使用)
- 业务主键:主键值与业务相关,如拿银行卡做主键
- 自然主键:自然数,与业务无关。
自然主键使用较多,因为主键只要做到不重复即可,不需要有意义。若与业务挂钩,当业务变动时会影响主键值。
MySQL 自动维护 自增主键
auto_increment 表示自增,从1开始递增
drop table if exists ctm;
create table ctm(
id int primary key auto_increment,
name varchar(255),
age int,
);
insert into ctm(name) values('zhangsan');
insert into ctm(name) values('zhangsan');
# 自动生成id列,且递增
2. 外键约束
- 建表时添加外键
FOREIGN KEY(外键列名) REFERENCES 主表(主表列名) - 建表后添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称); - 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
业务背景:设计数据库表,描述“班级与学生”的信息:学生学号、名字、班号、班主任。
- 若设计一张表,以学号作为主键,则班主任的信息很多相同,数据冗余,造成浪费
- 可设计两张表,学生表:学号、名字、班号(外键);班级表:班号、班主任
drop table if exists t_student;
drop table if exists t_class;
# 先创建父表
create table t_class(
class_no int primary key,
head_teacher varchar(255)
);
# 后创建子表
create table t_student(
student_no int primary key,
student_name varchar(255),
class_no int,
# 添加外键约束
foreign key(class_no) references t_class(class_no)
);
必须约束学生表中的班号存在且有效:学生表中的外键值(班号值)必须先存在于班级表
| 外键约束 | 字段被引用的表是父表 |
|---|---|
| 创建表的顺序 | 先创建父表、后子表 |
| 删除表的顺序 | 先删子表、后父表 |
| 插入数据 | 先插父表、后子表 |
| 删除数据 | 先删父表、后子表 |
- 外键值可以为
NULL吗? 可以 - 子表中的外键引用父表中的某个字段,必须是父表的主键吗?
不一定,但必须具有唯一性,用unique约束
数据库设计
数据库设计三范式
| 三范式 | 解释 | 举例 |
|---|---|---|
| 第一范式 | 任何表必须有主键,所有字段不可再分 | 一个字段为联系方式,可再 分为电话、邮箱 |
| 第二范式 | 建立在第一范式基础上,要求所有非主键字段完全依赖于主键,不能产生部分依赖 | |
| 第三范式 | 建立在第二范式基础上,要求所有非主键直接依赖主键,不能产生传递依赖 |
数据表关系
| 表关系 | 解释 | 例 |
|---|---|---|
| 一对多 | 两张表,多的表加外键 | 班级表、学生表(加外键连班级号) |
| 多对多 | 三张表,关系表两个外键,分别关联两方主键 | |
| 一对一 | 一张表,若某实体的字段太多可拆分表(将常用的放一张表,不常用的另一张表,用于提升查询性能) | 用户表拆成登陆信息表+详细信息表 |
多表查询(连接查询)
例:emp员工表(编号id,姓名name,性别gender,部门号dept_id),dept部门表(部门编号id,部门名name)
内连接
隐式内连接 : SELECT 字段 FROM 表一,表二 WHERE 表一.字段=表二.字段;
显式内连接 : SELECT * FROM 表一 INNER JOIN 表二 ON 表一.字段 = 表二.字段; (INNER可省略)
查询所有员工姓名及其部门名:
SELECT t1.name,t2.name FROM emp t1 JOIN dept t2 ON t1.dept_id=t2.id;
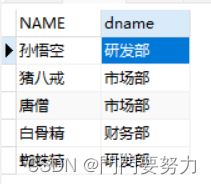
外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件; 显示左边表连接列的全部数据
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件; 显示右边表连接列的全部数据
例:
- 若有的员工没有部门信息,也显示出来
SELECT * FROM emp LEFT JOIN dept on emp.dep_id = dept.id;- 若有的部门没有员工,也显示出来
select * from emp right join dept on emp.dep_id = dept.did;(也可左外连接实现,将两表互换位置即可)

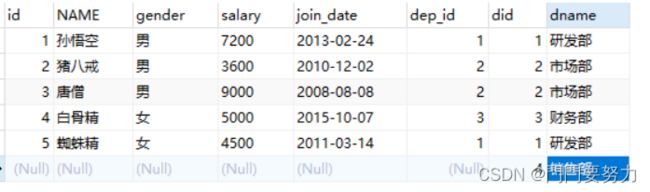
子查询
查询中嵌套查询
例:要查询学生表中英语成绩比马斯克高的同学信息。
需要先找出马斯克的英语成绩,然后以此条件查询其他同学信息
可用嵌套查询实现SELECT * FROM stu WHERE english > (SELECT english FROM stu WHERE name='马斯克');
| 根据子查询结果 | 需要不同判断条件 |
|---|---|
| 子查询结果单行单列(一个值) | 使用=!=><等条件 |
| 子查询结果多行单列(一串值) | 使用IN等条件 |
| 子查询结果多行多列(表) | 作为虚拟表 |
例:
- 查询财务部与市场部的所有员工信息
先查这俩部门的id,然后根据部门id查员工 :SELECT * FROM emp WHERE emp.dep_id IN (SELECT dept.did FROM dept WHERE dept.dname IN ('财务部','市场部'));- 查询入职日期在2011-11-11之后的员工信息与部门信息
先查满足条件的虚拟员工表,然后将其与部门信息内连接 :SELECT * FROM (SELECT * FROM emp WHERE emp.join_date>'2011-11-11') t1 JOIN dept ON t1.dep_id=dept.did;
补充
2.2 跨数据库连接
– select from db1.table1 new_name1
– join db2.table2 new_name2
– on new_name1.column = new_name2.column
– 2.3 自连接
– 2.4 复合连接条件:复合主键的连接需要用AND连接每个主键
– 2.5 隐式连接~
– 2.7 多表外连接
SELECT i.inv_id,s.store_id,sp.supply_id,s.store_name,i.inv_name
FROM store s
RIGHT JOIN inventory i
ON s.store_id = i.store_id
LEFT JOIN supply sp
ON i.supply_id = sp.supply_id;
– 2.8 自外连接
– 2.9 使用USING:当要连接的几个table中有一样的列名
SELECT a.area_name,s.store_name
FROM store s
RIGHT JOIN region a USING(area_id);
– 2.10 自然连接 NATURAL JOIN:不需要连接条件,搜索引擎自动查找共同列名
SELECT a.area_name,s.store_name
FROM store s
NATURAL JOIN region a ;
– 2.11 交叉连接 CROSS JOIN:将表一的一条记录与表2的每一条记录
SELECT s.area_id,a.area_id,a.area_name,s.store_name
FROM store s
CROSS JOIN region a ;
– 2.12 联合UNIONS:将结构相同的表(上下)拼接
SELECT b.bill_id,b.bill_info,‘good’ AS evaluate
FROM bill b
WHERE b.bill_info = ‘已付’
UNION
SELECT b.bill_id,b.bill_info,‘bad’ AS evaluate
FROM bill b
WHERE b.bill_info = ‘未付’;
2.9 使用USING:当需要连接的table中的连接列名一样
2.10 自然连接NATURAL JOIN:自动查找要连接的table中的共同列名
2.11 交叉连接CROSS JOIN:笛卡尔积
表一的每一个数据分别与表二的每一个数据
2.12 联合UNIONS:将相同结构的表拼接到一起(上下)
事务 transaction
数据库的事务是一个操作序列,包含一组数据库操作命令(一个完整的业务逻辑)
转账业务,A向B账户转账10000元,则A账户余额-10000(
update),B+10000,这是一个完整的业务逻辑,这些操作是一个最小的工作单元,要么同时成功、要么同时失败,不可再分。
- 只有DML语句有事务:
insertdeleteupdate这三个语句与事务有关,涉及增删改,需要考虑安全问题。 - 事务是一个不可分割的工作逻辑单元,需要多条DML语句实现,且事务的这些DML语句同时成功,或同时失败。
事务实现 同时成功 / 同时失败的方法
InnoDB存储引擎,提供一组用于记录事务性活动的日志文件:
insert.... update.... delete....
在事务执行过程中,每条DML操作都记录到事务性活动的日志文件中
如果操作能执行到最后没出异常,就提交事务;若出现异常,就回滚事务(撤销日志中做过的操作)
| 过程 | 标志 | 实现语句 | |
|---|---|---|---|
| 提交事务 | 清空事务性活动的日志文件,将数据彻底持久化到数据库中 | 提交事务标志:操作全部成功的结束 | commit |
| 回滚事务 | 将之前的DML操作全部撤销,并清空事务性活动的日志文件 | 回滚事务标志:操作全部失败的事务结束 | rollback |
-- 开启事务
BEGIN;
-- 转账操作
-- 1. 查询李四账户金额是否大于500
-- 2. 李四账户 -500
UPDATE account set money = money - 500 where name = '李四';
出现异常了... -- 此处不是注释,在整体执行时会出问题,后面的sql则不执行
-- 3. 张三账户 +500
UPDATE account set money = money + 500 where name = '张三';
-- 提交事务(若SQL顺利执行则提交)
COMMIT;
-- 回滚事务(若SQL语句出现问题则回滚事务语句)
ROLLBACK;
事务的四特性 - ACID
| 事务特性 | 说明 |
|---|---|
| 原子性 atomicity | 事务是不可再分的最小工作单元,所有操作必须同时成功,或同时失败 |
| 一致性 consistency | 事务完成时,必须使数据保持一致状态 |
| 隔离性 isolation | A事务与B事务的操作可能涉及同一表,两事务的操作需要一定的隔离 |
| 持久性 dynamic | 事务最终结束的保障。事务一旦提交或回滚,将数据保存到硬盘 |
事务的四大隔离级别
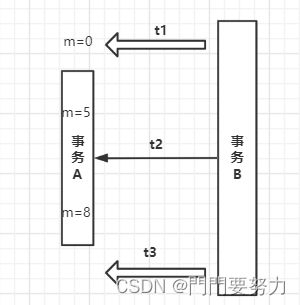
| 隔离级别(低-高) | 存在的问题 | 解释 |
|---|---|---|
读未提交 READ_UNCOMMITTED |
A提交前,事务B读到的都是A未提交的数据(脏读现象) | t1,B读m=0;t2时A还未提交,但m已更新为5,B读m=5。 但A最终可能提交,则m=8,B读到的5就是脏数据 t3时A已提交,B读m=8 |
读已提交 READ_COMMITTED |
A提交前,事务B只能读取A开启前的数据;A提交后,B读取A提交后的数据 (解决脏读,但不可重复读取) |
t2时(A还未提交),B只能读提交前的数据m=0;t3时(A已提交)B再次读m=8,两次读的不一致,这样不好 |
可重复读(MySQL默认隔离级别) REPEATABLE_READ |
B整个执行期间,看到的都是A执行前的数据(t0) (幻影问题:每次读取的数据都是幻象,不真实) |
由于B先执行,则在B整个事务过程中,读取的m都是0(实际上可能某一时刻m并不是0,这是幻影) |
序列化/串行化 SERIALIZABLE |
事务排队,不能并发(A操作时,B不能操作,synchronized) | 每次读取的数据都是最真实的,但效率最低 |
存储引擎
存储引擎:表存储数据的方式
在建表时指定存储引擎
create table t_student(
***
)engine = InnoDB default charset=utf8;
# 使用gbk可以插入中文值
show create table **; 查看建表的语句
show engines \G 查看MySQL支持的存储引擎
MySQL常用的存储引擎
| 存储引擎 | 特征 | 缺点 |
|---|---|---|
| MyISAM | 格式文件:存储表结构的定义 .frm;数据文件:存储表行的内容 .MYD;索引文件:存储表上的索引 .MYI(主键字段/unique约束的字段都自动建索引) |
|
| InnoDB(默认) | 支持事务以保证数据安全 | 效率不高、不能压缩、不能很好节省存储空间 |
| MEMORY | 表数据及索引存储在内存中,不需要与硬盘交互,查询快、效率高 | 不安全,关机后数据消失 |
索引
索引是在数据库表的字段上添加的,为了提高查询效率(缩小扫描范围)的机制(放在内存而不是磁盘中)。相当于字段的目录
select * from t_student where student_name = 'jack';,该SQL语句会在student_name字段扫描,若该字段未创建索引,会进行全表扫描(字段中每个值都比对一遍),效率较低
SQL的索引需要排序,其排序与TreeSet / TreeMap相同,底层是一个自平衡二叉树,MySQL中索引是一个B-Tree数据结构(存放原则:左小右大,读取数据:中序遍历)
- 任何数据库中的主键 /
unique约束列 都会自动添加索引对象, - 任何数据库中的任何一张表的任意一条记录,在硬盘存储上都有一个硬盘物理存储编号
- 索引在MySQL中是一个单独的对象,都是以树的形式存在(自平衡二叉树 B-Tree)
– 14.1 创建索引
EXPLAIN SELECT ctm_id FROM customer WHERE points > 1000;
CREATE INDEX idx_points ON customer(points);
EXPLAIN SELECT ctm_id FROM customer WHERE points > 1000;
– 14.2 查看索引
SHOW INDEXES IN customer;
– collation(排序规则):数据在索引中的排序方式A升B降
– cardinality(基数):索引中唯一值的估计数
– index_type:大多数索引以二进制树BTREE存储
– 主键索引:聚集索引(每个表最多一个),为表添加主键时自动生成的索引
– 二级索引:创建二级索引后,主键列会纳入二级索引
– 外键索引:为两张表创建关系时自动生成,为了加快join
14.1 对表的某几列创建索引:
创建前的查询遍历1010行:
创建后的查询遍历529行:
14.2 查看表中的索引:
索引的属性:
– collation(排序规则):数据在索引中的排序方式A升B降
– cardinality(基数):索引中唯一值的估计数
– index_type:大多数索引以二进制树BTREE存储
索引的类型:
– 主键索引:聚集索引(每个表最多一个),为表添加主键时自动生成的索引
– 二级索引:创建二级索引后,主键列会纳入二级索引
– 外键索引:为两张表创建关系时自动生成,为了加快join
– 14.3 前缀索引:由于索引是放在内存中,不应占太大空间,
– 当为字符串列建索引时,选取定长的字符串前缀,
– 前缀长度应使索引中唯一值最大化
SELECT
COUNT(DISTINCT LEFT(last_name,1)),
COUNT(DISTINCT LEFT(last_name,5)),
COUNT(DISTINCT LEFT(last_name,10))
FROM customer;
CREATE INDEX idx_lastname ON customer(last_name(5));
– 14.4 全文索引:需要在整个字符串中查找,如百度一个关键词
– 支持全文索引的内置函数match(查找列) against(查找内容)
– 相关性得分
– 自然语言模式:默认模式
– 布尔模式:'A -B +C’IN BOOLEAN MODE:排除B,必须有C
CREATE FULLTEXT INDEX idx_title_body ON posts(title,BODY);
SELECT * ,MATCH(title,BODY) AGAINST(‘react modal’)
FROM posts
WHERE MATCH(title,BODY) AGAINST(‘react modal’);
SELECT * ,MATCH(title,BODY) AGAINST(‘react modal’)
FROM posts
WHERE MATCH(title,BODY) AGAINST(‘react -modal + form’ IN BOOLEAN MODE);
14.3 前缀索引:取每个字符串记录取定长前缀
找到最佳前缀长度:能尽可能区分所有记录
14.4 全文索引:搜索引擎
内置函数MATCH(查找列) AGAINST(查找内容) 实现匹配,可输出相关性得分
默认自然语言模式:
布尔模式:‘A - B +C’ IN BOOLEAN MODE:有字符串A,无B,必包含C
– 14.5 复合索引:对多个列创建的索引
– 当查询条件较多时,MYSQL只用一个列索引
CREATE INDEX idx_state ON customer(state);
EXPLAIN SELECT ctm_id FROM customer WHERE state = ‘CA’ AND points > 100;
CREATE INDEX idx_state_points ON customer(state,points);
EXPLAIN SELECT ctm_id FROM customer WHERE state = ‘CA’ AND points > 100;
– 14.6 复合索引的列顺序
– ①让频繁使用的列放在前面
– ②把基数高的列放在前面(将查询结果变小) ???
– 考虑查询本身来确定顺序
– 14.7 索引失效
– 表达式中对索引列做运算时
EXPLAIN SELECT ctm_id FROM customer
WHERE points+10 > 2010;
– 换成
EXPLAIN SELECT ctm_id FROM customer
WHERE points > 2000;
14.5 复合索引:对多个列创建的索引
14.6 索引失效: 当表达式中有对索引的运算时
– 14.8 使用索引排序
– 无索引排序时:filesort外部排序方式成本高
EXPLAIN SELECT ctm_id FROM customer
ORDER BY first_name;
SHOW STATUS LIKE ‘last_query_cost’;
– index sort 不会全表排序
EXPLAIN SELECT ctm_id FROM customer
ORDER BY state,points;
SHOW STATUS LIKE ‘last_query_cost’;
– 14.9 覆盖索引
– 读取所有列,使用外部排序,会读取表
EXPLAIN SELECT * FROM customer
ORDER BY state;
– 二级索引dix_state自动包括了id主键列
– 设计索引时,应该尽量覆盖常用的列
– ①看where包含的列
– ②看order by 的列
– ③看select包含的列
EXPLAIN SELECT ctm_id,state FROM customer
ORDER BY state;
14.8 使用索引排序:外部排序成本较高file sort做全表排序
不适用索引进行排序:
创建IDX_STATE_POINTS后,USING INDEX排序
14.9 覆盖索引:索引应该覆盖常用列,如WHERE, ORDER BY , SELECT中的列
select *所有列,没有被索引覆盖,若记录多,查询慢
14.10 维护索引:
拒绝重复索引:两次创建(A, B, C)
拒绝多余索引:已有(A, B)又创建了(A) 多余了;但再创建(B ,A)不是多余的