python读取与存储文件
下面是学习《Python金融大数据分析》一书第9章“输入/输出操作”的笔记。若想查看细节,可阅读原书~
文章目录
- f=open(filepath)的一些符号释义
- Python基本I/O
-
- Pickle
- CSV文件
- 读写Numpy数组
-
- tips:
- Pandas的I/O
-
- 读取数据库数据
- PyTable的I/O
-
- 使用表
- 使用压缩表
-
- tips
f=open(filepath)的一些符号释义
- “r” - Read - Default value. Opens a file for reading, error if the file does not exist 读取文件,如果文件不存在会报错
- “a” - Append - Opens a file for appending, creates the file if it does not exist 向文件后添加内容,如果文件不存在会自动创建一个
- “w” - Write - Opens a file for writing, creates the file if it does not exist 写入文件,如果文件不存在会自动创建,写入时会覆盖之前的内容
- “x” - Create - Creates the specified file, returns an error if the file exists 创建文件,如果文件存在会报错
- “t” - Text - Default value. Text mode 适用于文本
- “b” - Binary - Binary mode (e.g. images) 适用于图像
Python基本I/O
Pickle
将python对象写入磁盘,办法之一是使用pickle模块,这个模块可以序列化大部分Python对象。
import pickle
import numpy as np
from random import gauss
#导入高斯生成正态分布随机数
a=[gauss(1.5,2) for i in range(1000000)]
'''
存储单个对象
'''
#设置要保存的路径
path=‘’
#为二进制模式(wb)打开文件
pkl_file=open(path+'data.pkl','wb')
#序列化对象a,并将其保存到文件
pickle.dump(a, pkl_file)
#关闭文件
pkl_file.close()
'''
读取单个对象
'''
#为二进制读模式(rb)打开文件
pkl_file=open(path+'data.pkl','rb')
#从磁盘读取对象并反序列化
b=pickle.load(pkl_file)
'''
比较a和b是否相同
'''
np.allclose(np.array(a),np.array(b)) #True、
'''
存储多个对象
'''
x=np.array(a)
y=np.array(a)**2
#为二进制模式(wb)打开文件
pkl_file=open(path+'data.pkl','wb')
#保存为字典格式
pickle.dump({'x':x,'y':y}, pkl_file)
#关闭文件
pkl_file.close()
'''
读取多个对象
'''
#为二进制读模式(rb)打开文件
pkl_file=open(path+'data.pkl','rb')
#从磁盘读取对象并反序列化
data=pickle.load(pkl_file)
pkl.close()
'''
查看输出结果
'''
for key in data.keys():
print(key, data[key][:4])
CSV文件
尽管CSV文件有特殊的结构,但是这种文件本质上还是普通文本文件。CSV文件很重要也很常见,因此Python标准库中有一个CSV模块,可以返回列表对象或者字典对象的一个列表。(当然,Pandas读取会更加方便)
import csv
'''
将每一行当作列表对象返回
'''
with open(path+'data.csv','r') as f:
csv_reader=csv.reader(f)
lines=[line for line in csv_reader]
'''
将每一行当作OrderedDic(有序字典)对象返回,该对象是字典的特例
即返回的每一行为OrderedDic([(列名1,列值1),(列名2,列值2),(列名3,列值3),(列名3,列值3),……])
'''
with open(path+'data.csv','r') as f:
csv_reader=csv.DicReader(f)
lines=[line for line in csv_reader]
读写Numpy数组
ndarry对象的保存经过了高度优化,因此相当快速。
import numpy as np
# datetime64[m]为以分为单位的时间格式
dtimes=np.arange('2019-01-01 10:00:00','2025-12-31 22:00:00',dtype='datetime64[m]')
#为结构数组定义特殊的dtype对象
dty=np.dtype([('Date','datetime64[m]'),('No1','f'),('No2','f')])
#用特殊dtype来实例化ndarray对象
data=np.zeros(len(dtimes),dtype=dty)
'''
填充
'''
data['Date']=dtimes
a=np.random.standard_normal((len(dtimes),2)).round(4)
data['No1']=a[:,0]
data['No2']=a[:,1]
'''
保存及读取数据
'''
np.save(path+'array',data)
np.load(path+'array.npy')

tips:
numpy也可以创建类似于dataframe的对象。
Pandas的I/O
pandas 库的主要优势之一是可以原生读取和写入不同的数据格式,包括:
- CSV 输入:read_csv() 输出:to_csv()
- SQL 输入:read_sql() 输出:to_sql()
- XLS/XLSX 输入:read_excel() 输出:to_excel()
- JSON 输入:read_json() 输出:to_json()
- HTML 输入:read_html() 输出:to_html()
- HDF 输入:read_hdf() 输出:to_hdf()
读取数据库数据
用pandas读取整个表或者查询结果通常更为高效
import cx_Oracle
import pandas as pd
# 下面以查询wind底层数据库filesync为例
cx_Oracle.init_oracle_client(lib_dir='instantclient_21_3路径')
conn = cx_Oracle.connect('用户名', '密码', 'ip')
testSql='''
SELECT TRADE_DT ,S_DQ_CLOSE enjie
FROM FILESYNC.AShareEODPrices
WHERE S_INFO_WINDCODE LIKE '002812.SZ'
ORDER BY TRADE_DT
'''
data=pd.read_sql(testSql,conn)
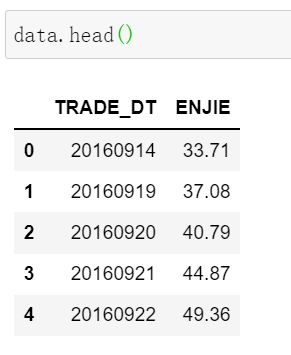
data.head()
PyTable的I/O
PyTable是Python与HDF5数据库/文件标准的结合。专门为优化I/O操作的性能、最大限度地利用可用硬件而设计。
PyTable提供了基于文件的数据库格式。其他数据需要服务器/客户端架构。事实证明,对于交互式数据和金融分析,基于文件的数据库更方便一些,也足以应付大部分场合。
使用表
import tables as tb
import numpy as np
import datetime as dt
filename=path+'pytab.h5'
h5=tb.open_file(filename,'w')
row_des={'Date':tb.StringCol(26,pos=1),
'No1':tb.IntCol(pos=2),
'No2':tb.IntCol(pos=3),
'No3':tb.Float64Col(pos=4),
"No4":tb.Float64Col(pos=5)}
rows=20000000
#指定压缩级别
filters=tb.Filters(complevel=0)
tab=h5.create_table('/','ints_floats', #表的节点和技术名称
row_des,
title='Integers and Floats',
expectedrows=rows, #预期行数,可优化
filters=filters)
#创建指针对象
pointer=tab.row
ran_int=np.random.randint(0,10000,size=(rows,2))
ran_flo=np.random.standard_normal((rows,2)).round(4)
for i in range(rows):
pointer['Date']=dt.datetime.now()
pointer['No1']=ran_int[i,0]
pointer['No2']=ran_int[i,1]
pointer['No3']=ran_flo[i,0]
pointer['No4']=ran_flo[i,1]
pointer.append() #附加新行
tab.flush() #所有写入的行都必须flush,也就是提交为永久性更改
上述例子中Python循环相当慢,可以通过Numpy结构数据提升性能
dty=np.dtype([('Date','S26'),('No1','),('No2','),
('No3','),('No4',')])
sarray=np.zeros(len(ran_int),dtype=dty)
sarray['Date']=dt.Datetime.now()
sarray['No1']=ran_int[:,0]
sarray['No2']=ran_int[:,1]
sarray['No3']=ran_flo[:,0]
sarray['No4']=ran_flo[:,1]
h5.create_table('/','ints_floats_from_array',sarray,
title='Integers and Floats',
expectedrows=rows, #预期行数,可优化
filters=filters)
h5.remove_node('/','ints_floats_from_array') #删除包含冗余数据的第二个Table对象
Table对象在大多数情况下与Numpy结构化数组的表现很相似
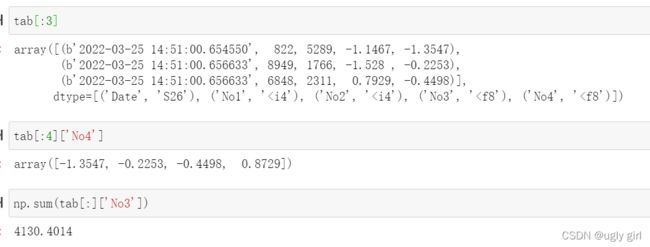
PyTables还提供了通过典型类SQL语句查询数据的灵活工具
query='((No3<-0.5) | (No3>0.5)) & ((No4<-1) | (No4>1))'
iterator = tab.where(query) #基于查询的迭代器对象
res=[(row['No3'], row['No4']) for row in iterator]
res=np.array(res)
使用压缩表
使用PyTable的主要优势之一是压缩方法。使用压缩不仅能节约磁盘空间,还能改善I/O操作的性能。
filters=tb.Filters(complevel=5, #压缩级别,参数取值范围为0-9
complib='blosc') #使用Blosc压缩引擎,该引擎优化了性能
tips
- Pytables可结合TsTables使用。TsTables软件包使用PyTables来为时间序列数据构建高性能存储,主要使用场景是“一次写入,多次检索”,能够进行快速的数据检索。由于笔者经历尚浅,还未遇到合适的应用场景,所以没有详细展开。如果后续遇到,可能会单独出一篇。