【学习】语音和图像上的自监督模型
李宏毅深度学习
- 回顾
-
- 文字BERT
- 语音BERT
- SUPERB
- 1、生成方法(generative approach)
-
- 语音BERT
- 语音GPT
- 图像GPT/BERT
- 2、预测方法(predictive approach)
-
- 图像-预测旋转
- 图像-预测内容
- 3、对比学习(contrastive learning)
-
- 图像对比学习:simCLR
- 图像对比学习:MoCo
- 语音对比学习:CPC、wav2vec
- 语音对比学习:VQ-wav2vec
- VQ-wav2ve 2.0与BERT的关系
- 分类和对比
- 选择负样本并不简单
- 4、自举方法(Bootstrapping Approaches)
-
- 典型的知识蒸馏
- 5、简单额外正则化(Simply Extra Regularization)
-
- VICReg
- 结束语
回顾
文字BERT
BERT预训练使用无标签的资料,也可以加点有标签的资料;然后在微调的时候用标注的资料对应特定的下游任务。

语音BERT
也是直接使用无标签的语音信号预训练,用少量标注的资料用来微调下游任务的模型。

今天的语音辨识系统,如果没有大的模型做预训练,就要用成千上万的标注资料进行训练。
其实微调BERT是不需要的,可以只微调下游任务模型。
SUPERB
语音处理通用性能基准,下面是14个语音任务,这些是跟文章内容、说话者、语义等有关。
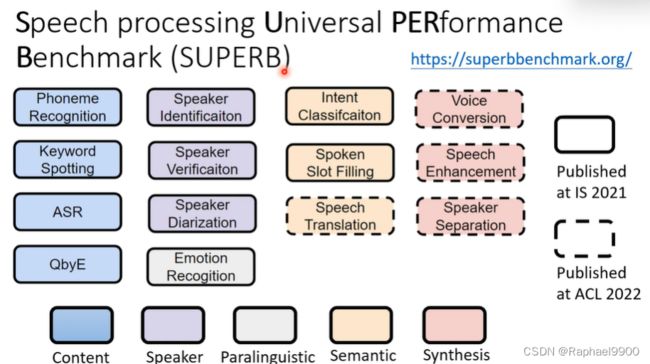
self-supervised learning 用在语音任务上

可以用在语音上的工具包:
![]()
self-supervised learning 用在图像上
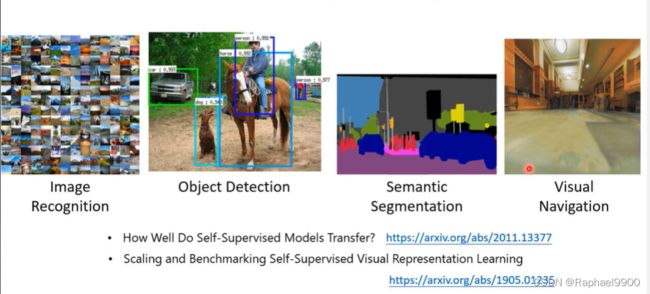
自监督学习是用大量的无标签数据和少量的有标注数据进行训练,下面1.0处的supervision虚线表示模型全使用标注资料进行训练,可以看出很多线(用大量无标签数据进行训练)都跟这个虚线差不多 了,很惊人。

1、生成方法(generative approach)
BERT和GPT如何应用在语音和图像上?
语音BERT
盖住某些语音片段,经过跟文字差不多的处理之后还原出语音:
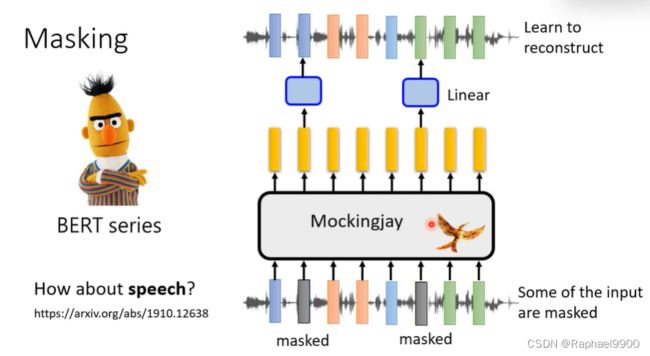
有一个很知名的语音模型mockingjay(学舌鸟),输入一段语音,输出同一段语音。
masking
但是语音和文字还是不一样的,我们需要注意什么吗?

声学特征的平滑度
声音信号的向量之间其实是很接近的!把某些向量盖住,可以根据旁边的向量做内差得到中间的向量。所以我们需要盖住一串向量(屏蔽连续特征)!

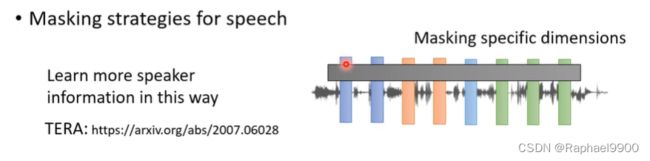
语音掩蔽策略
可以掩码住某几个声音向量的几个维度,而不是时间上的向量,这种方法比较容易让机器学会说话者的信息。
语音GPT
GPT在文字上是给一段文字,预测下一段token。
在声音上也可以,但是还是有些不一样的:
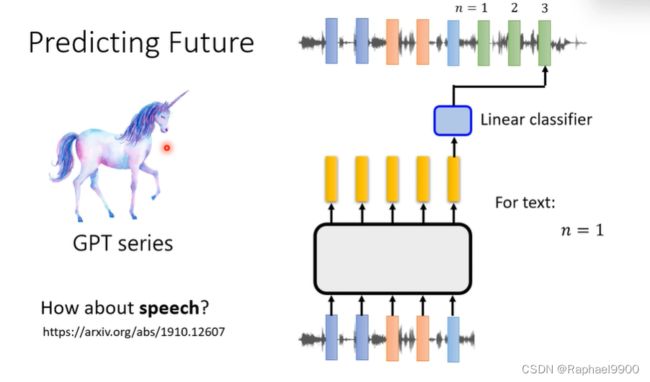
如果给一段声音信号预测下一段(简单,语音相邻的向量很接近),那就不能学到什么。所以我们可以让机器学一段时间之后的声音信号(n>3)。
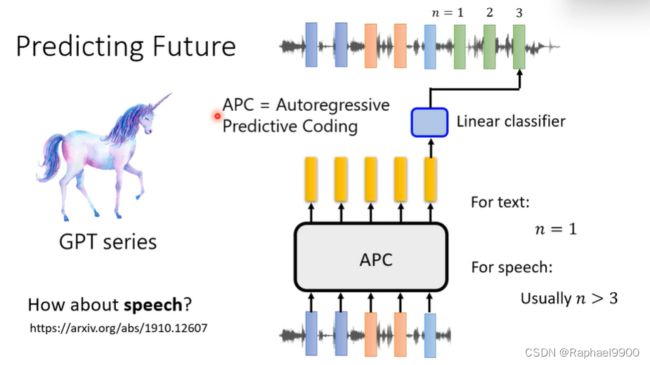
图像GPT/BERT
把图像的像素拉直成一排,然后套用GPT/BERT,用在下有任务。
用在文字上和用在语音/图像上是不一样的,因为语音/图像包含了很多细节。如果要模型把语音/图像完整还原是很困难的。语音和图像包含许多难以生成的细节。模型可以学习没有生成吗?机器能不能还原或者预测别的东西也能达到自监督学习的效果呢?
2、预测方法(predictive approach)
产生原来的声音/图像比较复杂,那可以还原/预测别的东西吗?
图像-预测旋转
把一张图片进行旋转,然后让图片进行预测旋转了多少度。

图像-预测内容
给一张图片,切出两个小块,让机器预测两个小块的关系(在哪个方向)。

给两个声音信号预测之间的时间间隔。

上面两个方法都能让机器在下游任务表现的好。
那什么样的小任务能让机器学的更好呢?这里没有明确的定义,需要摸索。
这里有一个比较普遍的方法,可以让机器不做生成也能做自监督学习。简化方法。
有一段声音信号,直接取样无法做到,可以进行特征提取得到一些向量,然后进行离散化,每个向量就变成了token(classer id,让机器训练预测产生id),这样就比较容易一点。
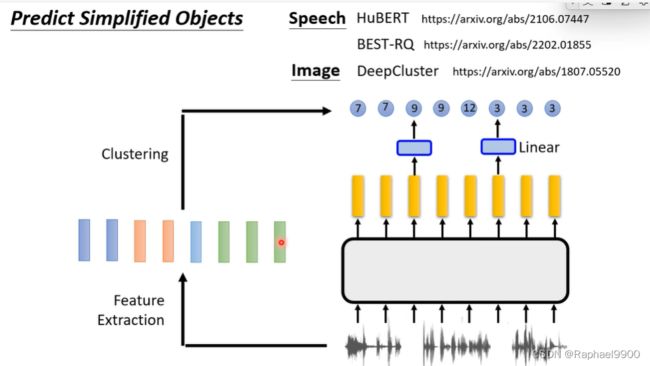
3、对比学习(contrastive learning)
语音和图像包含许多难以生成的细节。
有没有让机器在自监督学习上不产生任何东西的方法?
给定两张图片,如果是同一个类别就是positive的一对。我们输入到encoder里面希望得到的结果越接近越好。如果是negative的,那就希望他们的向量越远越好。

但是在自监督学习的时候我们不知道那些图片是什么类别。下面是一个对比学习的方法:simCLR
图像对比学习:simCLR
数据增大(Data Augmentation)
论文会做:随机裁剪(主要,不可缺)、颜色失真、高斯模糊等,然后判断这些数据增大的关系:

那怎么做数据增大呢?不能太难(还是原图或者是变了内容)和太简单(学不到东西)。

图像对比学习:MoCo
增加memory bank和momentum encoder。吸收simCLR产生moco v2.

语音对比学习:CPC、wav2vec
encoder的输出与相邻的encoder输出的向量是positive的,跟不相邻或者其他句子的encoder的输出是negative的。我们希望输出经过linear之后跟positive越接近越好,跟negative越远越好。做完之后可以把这个模型用在下游任务上。
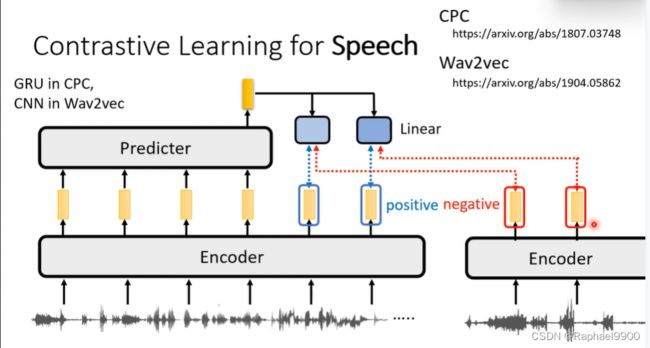
语音对比学习:VQ-wav2vec
encoder的输出不是向量而是token(分离的)。

VQ-wav2vec接了一个encoder(是BERT架构的)。训练的方法就是:encoder(VQ)固定,然后传入第二个encoder进行预测(两个encoder分开训练)。这种结构确实比较好。

然后出现了两个encoder一起训练的VQ-wav2ve 2.0。前一个encoder输出连续的东西(embedding),接给第二个encoder(输出一个序列)。然后mask一些向量,用输出的向量预测同一个位置的token(3),同时希望产生其他token的概率越小越好(9/7)。
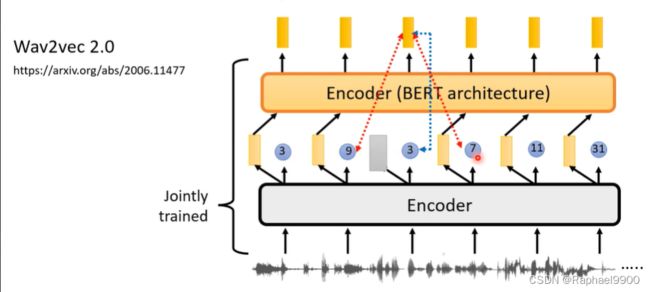
这样确实很复杂。如果第二个encoder不输入连续的输入,而是输出离散的token就会很差(影响大)。
量化目标提高性能(影响不是很大):输出的向量预测同一个位置的token(3),同时希望产生其他token的概率越小越好(9/7)。
为什么不制定为典型分类问题?可能是语音对应的token的数量很大,那么negative example会很大,运算复杂。所以只把部分negative 概率压低。
VQ-wav2ve 2.0与BERT的关系
文字上能用对比学习吗?其实可以把BERT看成是对比学习的方法,bert的重构可以看成是分类问题(跟正确的越近越好)。
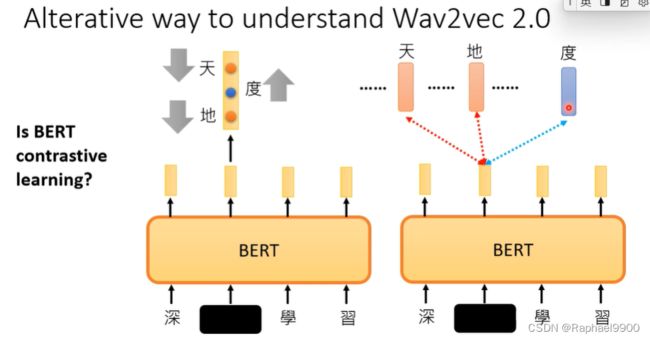
分类和对比
对于分类,我们希望正确的值越大越好;对于对比,我们希望跟正确值是positive的,跟其他值是negative的。

对于token比较大的,可以用对比学习,让一些判断为negative就行。
语音上负样本是不能穷举的,但是文字上可以。

所以把声音信号转化为离散的东西。

选择负样本并不简单
负样本应该足够难:

但是也不能太难了:分辨同样是猫的图片

有什么方法可以避免选择负样本呢?
4、自举方法(Bootstrapping Approaches)
为什么不只用正样本呢?因为如果全是正样本,那就会collapse。有右边的例子:只更新右边,不更新左边的encoder,然后把右边的参数复制到左边。让左右两边的结构不一样,同时他们的参数更新方法也不一样。

理解自举的另一种方式:
典型的知识蒸馏
用学生模型(小)学习教师模型(大),让输出越近越好。

类似:
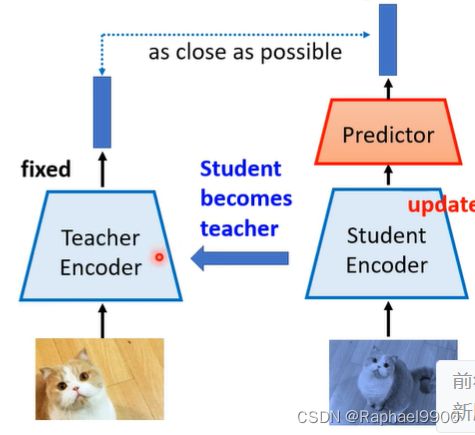
随机的学生encoder也可以学到东西,BYOL这种方法不是直接复制,而是moving average(不断接近)。
simsiam直接复制。

语音上的自举方法:data2vec跟byol类似。
5、简单额外正则化(Simply Extra Regularization)
加上regularization,不用负样本。

VICReg
invariance不变性:用正样本训练,但是这样会总是输出一样的向量。
variance(关键):大于阈值的方差,同一个维度的数值的variance要够大,避免输出一样的向量。
covariance:把向量拿出来计算covariance的向量,非对角线接近0的元素。
如果只有variance和invariance就会让分布成线没有很多地方空白,使用covariance会分布平均。


结束语
