nlp-词向量学习笔记1
什么是词向量?
词向量技术是将词转化成为稠密向量,并且对于相似的词,其对应的词向量也相近。
(稠密向量跟稀疏向量相对,稀疏向量指的是大多数元素等于0的向量)
一、词的表示
在自然语言处理任务中,首先需要考虑词如何在计算机中表示。通常,有两种表示方式:one-hot representation和distribution representation。
1.1离散表示(one-hot representation)
传统的基于规则或基于统计的自然语义处理方法将单词看作一个原子符号,被称作one-hot representation。one-hot representation把每个词表示为一个长向量。这个向量的维度是词表大小,向量中只有一个维度的值为1,其余维度为0,这个维度就代表了当前的词。
例如:苹果 [0,0,0,1,0,0,0,0,0,……]
one-hot representation相当于给每个词分配一个id,这就导致这种表示方式不能展示词与词之间的关系。另外,one-hot representation将会导致特征空间非常大,但也带来一个好处,就是在高维空间中,很多应用任务线性可分。
(线性可分就是说可以用一个线性函数把两类样本分开,比如二维空间中的直线、三维空间中的平面以及高维空间中的线性函数。)
1.2分布式表示(distribution representation)
word embedding指的是将词转化成一种分布式表示,又称词向量。分布式表示将词表示成一个定长的连续的稠密向量。
分布式表示优点:
(1)词之间存在相似关系:词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。
(2)包含更多信息:词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
二、如何生成词向量
生成词向量的方法有很多,这些方法都依照一个思想:任一词的含义可以用它的周边词来表示。生成词向量的方式可分为:基于统计的方法和基于语言模型(language model)的方法。
2.1 基于统计方法
2.1.1 共现矩阵
通过统计一个事先指定大小的窗口内的word共现次数,以word周边的共现词的次数做为当前word的vector。具体来说,我们通过从大量的语料文本中构建一个共现矩阵来定义word representation。
例如,有语料如下:
I like deep learning.
I like NLP.
I enjoy flying.
则其共现矩阵如下:
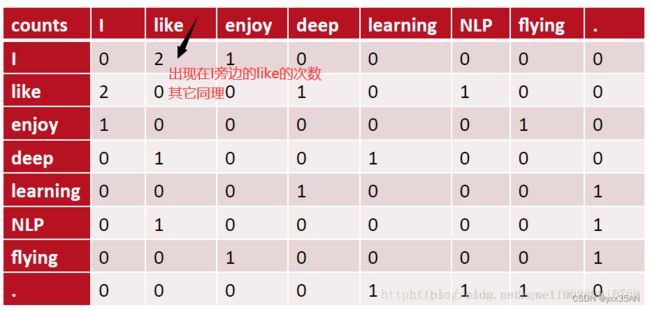
矩阵定义的词向量在一定程度上缓解了one-hot向量相似度为0的问题,但没有解决数据稀疏性和维度灾难的问题。
2.1.2 SVD(奇异值分解)
既然基于co-occurrence矩阵得到的离散词向量存在着高维和稀疏性的问题,一个自然而然的解决思路是对原始词向量进行降维,从而得到一个稠密的连续词向量。
SVD做降维的思路:
根据方阵的特征值分解,即用特征值+特征向量来替代原矩阵的方式:
可将长方阵分解为: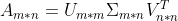
并规定 除对角线以外的元素都是0,对角线元素称为奇异值(类似特征值),
除对角线以外的元素都是0,对角线元素称为奇异值(类似特征值),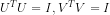 。
。
为了仿照特征值的求解方法,我们需要构造一个方阵,可以想到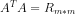 ,那么使用这个新矩阵R来求解特征值,即有
,那么使用这个新矩阵R来求解特征值,即有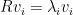 ,仿照上面特征值分解的方式将特征向量组合,可以得到矩阵V,称这些特征向量为右奇异向量。同理,构造
,仿照上面特征值分解的方式将特征向量组合,可以得到矩阵V,称这些特征向量为右奇异向量。同理,构造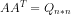 ,再解一批特征向量
,再解一批特征向量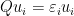 ,组合这些新特征向量
,组合这些新特征向量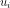 可得左奇异矩阵U。
可得左奇异矩阵U。
又因为:
特征值:用于表示变化幅度
特征向量:用于表示变化方向
因此我们可以只提取原始矩阵中的部分信息即特征值较大的那些对应的信息,假设我们只提取k个最大的特征值对应的信息,那么上述公式就变为: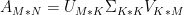
一般来说信息会集中在前面比较大的特征值上,而在SVD中,奇异值的大小降低得非常快,因此我们可以就取部分的奇异值及其对应的奇异向量来近似替代原矩阵做一个降维,这就是整个SVD做降维的思路。
对2.1.1中矩阵,进行SVD分解,得到正交矩阵U,对U进行归一化得到矩阵如下:
(归一化:统一量纲)

SVD得到了word的稠密(dense)矩阵,该矩阵具有很多良好的性质:语义相近的词在向量空间相近,甚至可以一定程度反映word间的线性关系。

2.2语言模型(language model)
语言模型生成词向量是通过训练神经网络语言模型NNLM(neural network language model),词向量作为语言模型的附带产出。NNLM背后的基本思想是对出现在上下文环境里的词进行预测,这种对上下文环境的预测本质上也是一种对共现统计特征的学习。
较著名的采用neural network language model生成词向量的方法有:Skip-gram、CBOW、LBL、NNLM、C&W、GloVe等。
其中,CBOW(Continuous Bag-of-Words)和Skip-gram是word2vec的两个经典模型
以“Pineapples are spiked and yellow”为例:
- CBOW:通过上下文的词向量推理中心词。
- Skip-gram:根据中心词推理上下文。

2.2.1 CBOW(Continuous Bag-of-Word)
2.2.1.1 CBOW的算法实现
CBOW是一个具有3层结构的神经网络,如图:
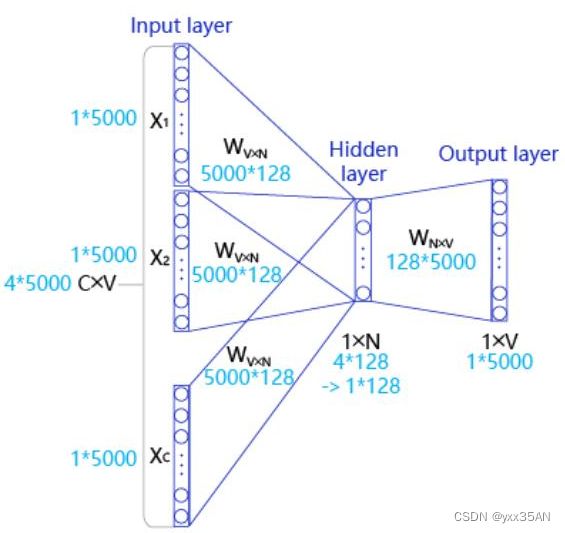
输入层: 一个形状为C×V的one-hot张量,其中C代表上下文中词的个数(上下文的选取采用窗口方式,即只将当前词窗口范围内的词作为上下文,窗口长度一般是奇数,每个窗口中间的词被认为是中心词,其余的词被认为是这个中心词的上下文),通常是一个偶数,我们假设为4;V表示词表大小,我们假设为5000,该张量的每一行都是一个上下文词的one-hot向量表示,比如“Pineapples, are, and, yellow”。
(张量:多维数组)
隐藏层: 一个形状为V×N的参数张量W1,一般称为word-embedding,N表示每个词的词向量长度,我们假设为128。输入张量和word embedding W1进行矩阵乘法,就会得到一个形状为C×N的张量。综合考虑上下文中所有词的信息去推理中心词,因此将上下文中C个词相加得一个1×N的向量,是整个上下文的一个隐含表示。
输出层: 创建另一个形状为N×V的参数张量,将隐藏层得到的1×N的向量乘以该N×V的参数张量,得到了一个形状为1×V的向量。最终,1×V的向量代表了使用上下文去推理中心词,每个候选词的打分,再经过softmax函数的归一化,即得到了对中心词的推理概率:
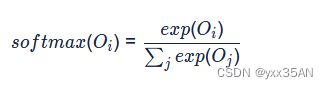
2.2.1.2 CBOW的实际实现
在实际中,为避免过于庞大的计算量,通常采用负采样的方法,来避免查询整个词表,从而将多分类问题转换为二分类问题,具体实现过程如图:
(负采样:用与正样本相同的上下文词,再在字典中随机选择一个单词)
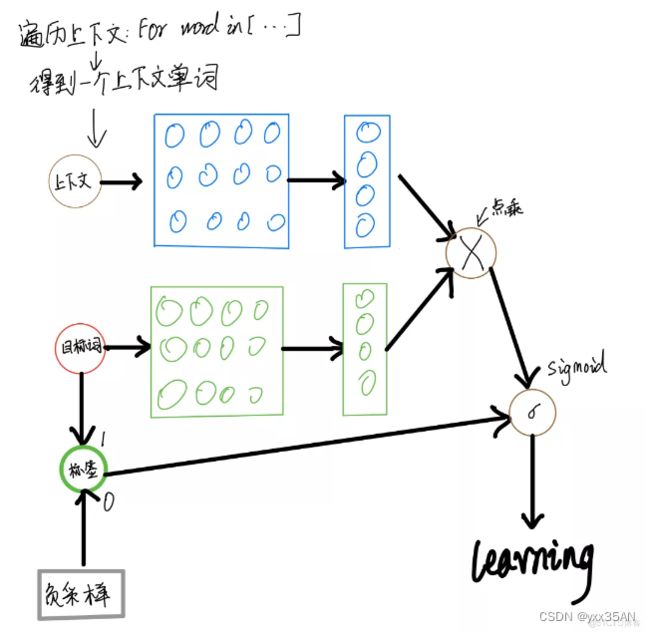
在实现的过程中,通常会让模型接收3个tensor(张量)输入:
代表上下文单词的tensor:假设我们称之为context_words V,一般来说,这个tensor是一个形状为[batch_size, vocab_size(词表大小)]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
(mini-batch是将所有数据分批,然后按顺序处理,每一批计算一次loss,更新参数,然后下一批。例如batch_size=128)
代表目标词的tensor:假设我们称之为target_words T,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
代表目标词标签的tensor:假设我们称之为labels L,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
为了减少时间复杂度,CBOW还采用一种Hierarchical softmax技术,利用哈夫曼树对词表进行分类,用一连串的二分类来近似多分类。
2.2.1 Skip-gram
2.2.1.1 Skip-gram的算法实现
Skip-gram结构:
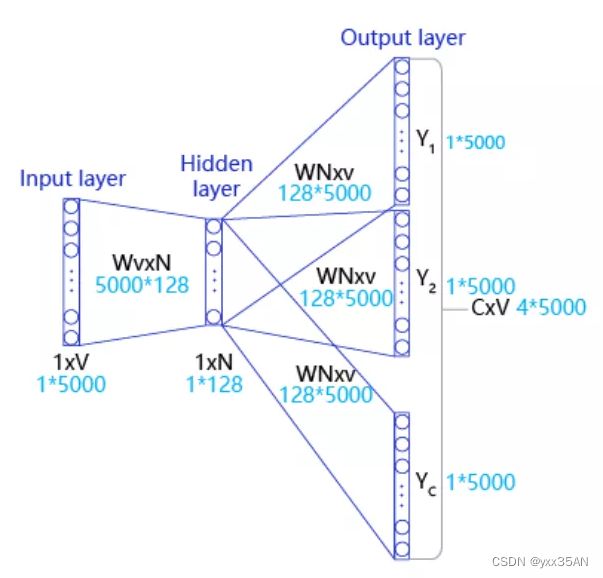
Input Layer(输入层):接收一个one-hot张量![]() 作为网络的输入,里面存储着当前句子中心词的one-hot表示。
作为网络的输入,里面存储着当前句子中心词的one-hot表示。
Hidden Layer(隐藏层):将张量V乘以一个word embedding张量![]() ,并把结果作为隐藏层的输出,得到一个形状为
,并把结果作为隐藏层的输出,得到一个形状为![]() 的张量,里面存储着当前句子中心词的词向量。
的张量,里面存储着当前句子中心词的词向量。
Output Layer(输出层):将隐藏层的结果乘以另一个word embedding张量![]() ,得到一个形状为
,得到一个形状为![]() 的张量。这个张量经过softmax变换后,就得到了使用当前中心词对上下文的预测结果。根据这个softmax的结果,我们就可以去训练词向量模型。
的张量。这个张量经过softmax变换后,就得到了使用当前中心词对上下文的预测结果。根据这个softmax的结果,我们就可以去训练词向量模型。
2.2.1.2 Skip-gram的实际实现
同样采用负采样的方法。
假设有一个中心词c和一个上下文词正样本tp。在Skip-gram的理想实现里,需要最大化使用c推理tp的概率。在使用softmax学习时,需要最大化tp的推理概率,同时最小化其他词表中词的推理概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再随机在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
在实现的过程中,通常会让模型接收3个tensor输入:
代表中心词的tensor:假设我们称之为center_words V,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
代表目标词的tensor:假设我们称之为target_words T,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
代表目标词标签的tensor:假设我们称之为labels L,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
学习资料参考:
【自然语言处理(NLP)】基于CBOW实现Word2Vec_51CTO博客_自然语言处理(NLP)
【自然语言处理(NLP)】基于Skip-gram实现Word2Vec_灵彧universe的技术博客_51CTO博客