数据分析可视化常用图介绍以及相关代码实现(箱型图、Q-Q图、Kde图、线性回归图、热力图)
文章目录
- 前言
- 一、箱型图是什么?
-
- 1-1、箱型图介绍
- 1-2、箱型图的作用
- 1-3、实战
- 二、Q-Q图是什么?
-
- 2-1、Q-Q图(分位数-分位数图:quantile-quantile plot)介绍
- 2-2、实战
- 2-3、为什么要使数据呈现正态分布以及出现了正态分布,数据应该如何处理?
- 三、Kde图是什么?
-
- 3-1、Kde图介绍
- 3-2、实战
- 3-3、分布不一致如何处理?
- 三、线性回归图
-
- 4-1、线性回归图绘制函数介绍
- 4-2、实战
- 4-3、相关性不高如何处理?
- 总结
前言
爱意随风起,风止意难平。
一、箱型图是什么?
1-1、箱型图介绍
箱型图:箱线图也称箱须图、箱形图、盒图,用于反映一组或多组连续型定量数据分布的中心位置和散布范围。箱形图包含数学统计量,不仅能够分析不同类别数据各层次水平差异,还能揭示数据间离散程度、异常值、分布差异等等。
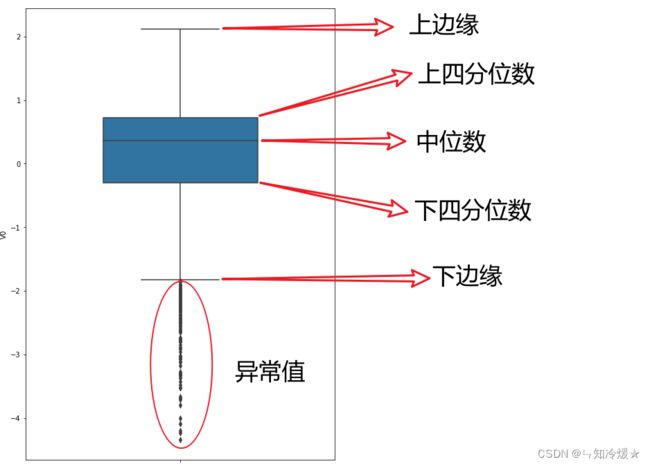
下边缘(Q1),表示最小值;下四分位数 - 1.5 ×(上四分位数-下四分位数)
下四分位数(Q2),又称“第一四分位数”,等于该样本中所有数值由小到大排列后第25%的数字;
中位数(Q3),又称“第二四分位数”等于该样本中所有数值由小到大排列后第50%的数字;
上四分位数(Q4),又称“第三四分位数”等于该样本中所有数值由小到大排列后第75%的数字;
上边缘(Q5),表述最大值。上四分位数 + 1.5 ×(上四分位数-下四分位数)
异常值:在上边缘和下边缘的范围之外,就是异常值。
1-2、箱型图的作用
1、箱子的宽度在一定程度上反映了数据的波动程度,箱体越扁说明数据越集中,而箱体越长,则说明数据越分散。
2、可以清晰地观察到数据的整体分布情况,可以清楚的看到数据的下边缘、下四分位数、中位数、上四分位数、上边缘、异常值。
3、箱型图最大的优点是不受异常值的影响,可以以一种相对稳定的方式描述数据的离散分布情况。
4、对于太离谱的值,可以直接删掉,亦或者是变为缺失值,按照缺失值来处理,比如说均值填充、众数填充、中位数填充、使用其他数据来预测该值等等。
1-3、实战
# 使用matplotlib和seaborn来绘制图像
import matplotlib.pyplot as plt
import seaborn as sns
# 设置尺寸。
fig = plt.figure(figsize=(8, 12)) # 指定绘图对象宽度和高度
# 以y为轴进行绘制
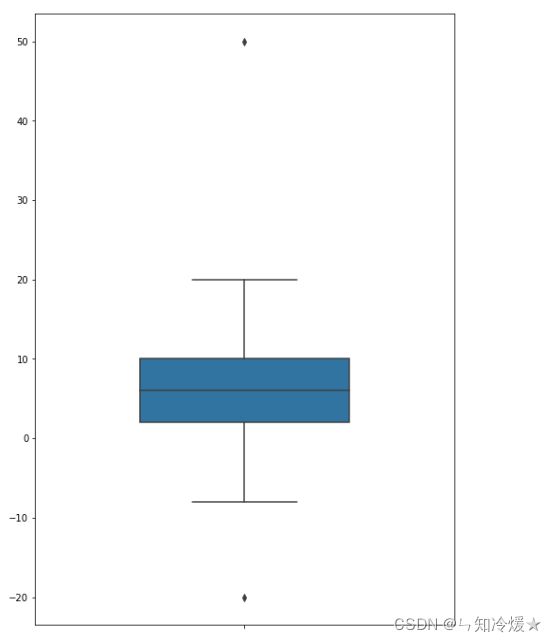
sns.boxplot(y = [2,4,6,8,10,20,-8,50,-20], width=0.5)
二、Q-Q图是什么?
2-1、Q-Q图(分位数-分位数图:quantile-quantile plot)介绍
Q-Q图:Q-Q(分位数 - 分位数)图是概率图,其是通过将绘制两个概率分布的分位数来比较两者分布关系的图形方法,主要作用是判断样本是否近似于某种类型的分布,这里以正态分布为例。
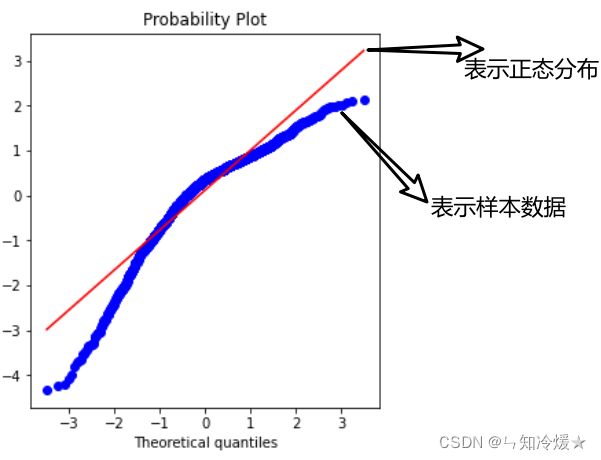
注意:蓝色越接近红色参考线,说明越符合预期分布。
2-2、实战
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
fig = plt.figure()
# 第一个参数:从哪个样本中创建。
res = stats.probplot(train[‘SalePrice’], plot=plt)
# 默认检测是正态分布
# 完整写
# stats.probplot(grade, dist=stats.norm, plot=plt) #正态分布
# stats.probplot(grade, dist=stats.expon, plot=plt) #指数分布
# stats.probplot(grade, dist=stats.logistic, plot=plt) # 对数正态分布
plt.show()
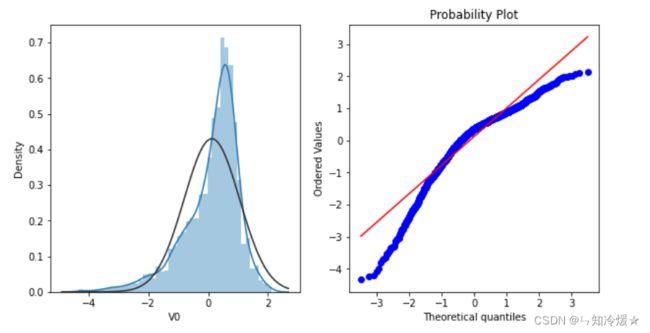
通常配合直方图来一起分析
# 直方图又称质量分布图,它是表示资料变化情况的一种主要工具。用直方图可以解析出资料的规则性,比较直观地看出产品质量特性的分布状态,
# -> 对于资料分布状况一目了然,便于判断其总体质量分布情况。直方图表示通过沿数据范围形成分箱,
# -> 然后绘制条以显示落入每个分箱的观测次数的数据分布。
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
plt.figure(figsize=(10,5))
ax=plt.subplot(1,2,1)
sns.distplot(train_data['V0'],fit=stats.norm)
ax=plt.subplot(1,2,2)
res = stats.probplot(train_data['V0'], plot=plt)
2-3、为什么要使数据呈现正态分布以及出现了正态分布,数据应该如何处理?
为什么要使数据呈现正态分布:很多模型假设数据服从正态分布后,它的样本均值和方差就相互独立,这样能更好地进行统计推断和假设验证。
数据应该如何处理?数据预处理—4.为什么要趋近于正态分布?详解.
三、Kde图是什么?
3-1、Kde图介绍
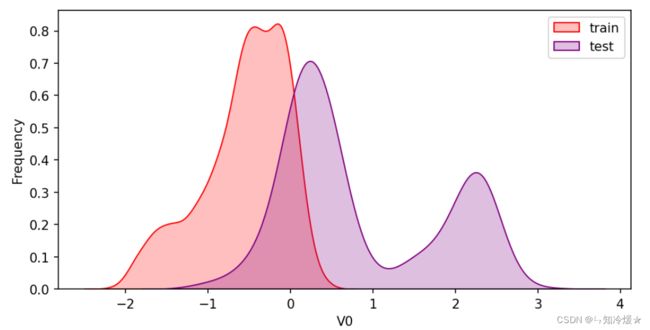
Kde图介绍: 是指Kernel Density Estimation核概率密度估计。可以理解为是对直方图的加窗平滑。通过KDE分布图,可以查看并对训练数据集和测试数据集中特征变量的分布情况。它描述了连续变量中不同值的概率密度。在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
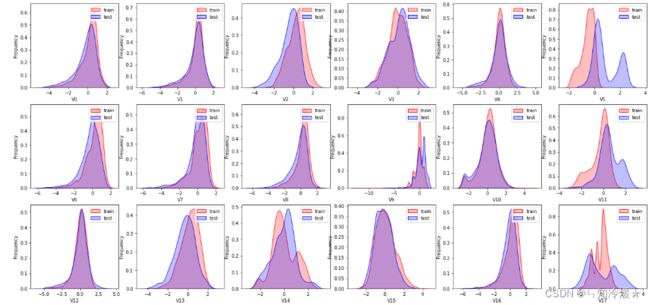
3-2、实战
# 把每一个特征对应的分布图都画出来,分别调节。
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
ax = sns.kdeplot(train_data['V0'], color="Red", shade=True)
ax = sns.kdeplot(test_data['V0'], color="Blue", shade=True)
ax.set_xlabel('V0')
ax.set_ylabel("Frequency")
ax = ax.legend(["train","test"])

3-3、分布不一致如何处理?
分布不一致: 如果出现分布不一致的情况,我们需要将特征直接删除。
原因: 如果训练数据和测试数据的某个特征分布不一致,会导致模型的泛化能力差,我们要直接删除此类特征方法。
三、线性回归图
4-1、线性回归图绘制函数介绍
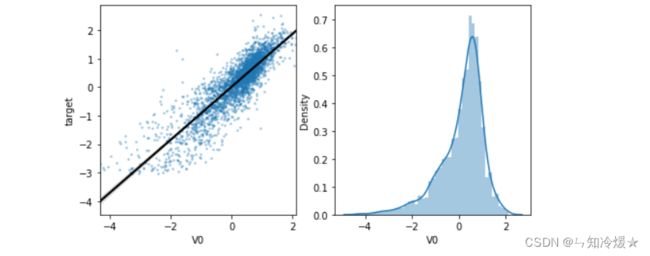
seaborn.regplot():: 该方法用于绘制数据和线性回归模型拟合。有许多相互排斥的选项可用于估计回归模型。
4-2、实战
# 探索特征变量V0与target变量的线性回归关系。
fcols = 2
frows = 1
plt.figure(figsize=(8,4))
ax=plt.subplot(1,2,1)
sns.regplot(x='V0', y='target', data=train_data, ax=ax,
scatter_kws={'marker':'.','s':3,'alpha':0.3},
line_kws={'color':'k'});
plt.xlabel('V0')
plt.ylabel('target')
ax=plt.subplot(1,2,2)
sns.distplot(train_data['V0'].dropna())
plt.xlabel('V0')
plt.show()
4-3、相关性不高如何处理?
相关性不高:相关系数越大,则认为这些特征变量对target变量的线性影响越大,相关性系数较小的话,特征对于模型的拟合会起到反作用,通常和热力图一起来查看相关性。
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
# 调用dataframe的相关性矩阵。
train_corr = data_train1.corr()
# 画出相关性热力图
ax = plt.subplots(figsize=(20, 16))#调整画布大小
ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True)#画热力图 annot=True 显示系数
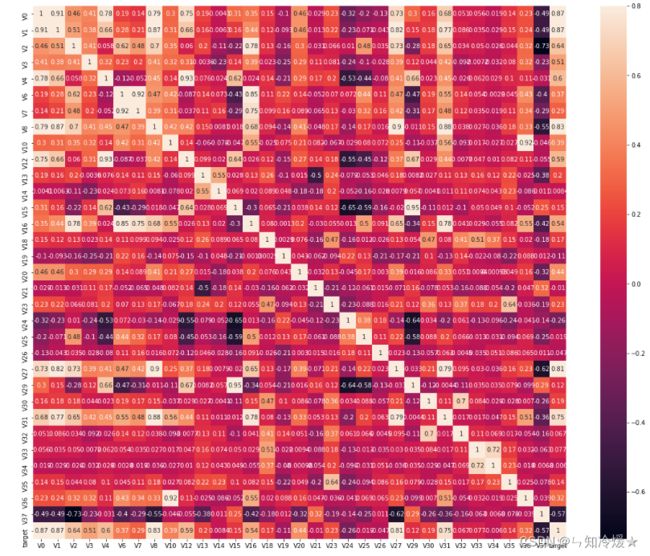
数据应该如何处理?与目标变量相关系数小于0.5的特征变量一般都会直接被删掉。
注意:对于target变量如果存在更复杂的函数形式的影响,建议使用树模型的特征重要性去选择。
多重共线性: 多重共线性是指自变量彼此相关的一种情况。当你拟合模型并解释结果时,多重共线性可能会导致问题。数据集的变量应该是相互独立的,以避免出现多重共线性问题。对于一个数据集,如果一些自变量彼此高度独立,就会导致多重共线性。
如何处理多重共线性?即如何处理特征之间的高度相关?我们可以删除一些高度相关的特征(相关性大于0.9),去除数据中的多重共线性,但是!!! 可能会导致信息的丢失,对于高维数据也是不可行的技术。但是可以使用PCA算法来降低数据的维数,从而去除低方差的变量。
结语:以上都是瞎扯,请自行调参,实践是检验真理的唯一标准。
参考文章:
统计学(二)——从箱型图去理解数据.
什么是箱线图,箱线图要怎么做?.
如何深刻理解箱线图(boxplot).
箱形图怎么看,以及它反映了什么?.
通俗讲解qq plot.
QQ plot图——评价你的统计模型是否合理.
使用 Pandas 和 Seaborn 进行 KDE 绘图可视化.
工业蒸汽 02数据探索.
总结
OS:这篇文章写的很好,以后不许再写了。