解密回声消除技术--转
一、前言
因为工作的关系,笔者从2004年开始接触回声消除(Echo Cancellation)技术,而后一直在某大型通讯企业从事与回声消除技术相关的工作,对回声消除这个看似神秘、高端和难以理解的技术领域可谓知之甚详。
要了解回声消除技术的来龙去脉,不得不提及作为现代通讯技术的理论基础——数字信号处理理论。首先,数字信号处理理论里面有一门重要的分支,叫做自适应信号处理。而在经典的教材里面,回声消除问题从来都是作为一个经典的自适应信号处理案例来讨论的。既然回声消除在教科书上都作为一种经典的具体的应用,也就是说在理论角度是没有什么神秘和新鲜的,那么回声消除的难度在哪里?为什么提供回声消除技术(不管是芯片还是算法)的公司都是来自国外?回声消除技术的神秘性在哪里?
二、回声消除原理
从通讯回音产生的原因看,可以分为声学回音(Acoustic Echo)和线路回音(Line Echo),相应的回声消除技术就叫声学回声消除(Acoustic Echo Cancellation,AEC)和线路回声消除(Line Echo Cancellation, LEC)。声学回音是由于在免提或者会议应用中,扬声器的声音多次反馈到麦克风引起的(比较好理解);线路回音是由于物理电子线路的二四线匹配耦合引起的(比较难理解)。
回音的产生主要有两种原因:
1. 由于空间声学反射产生的声学回音(见下图):
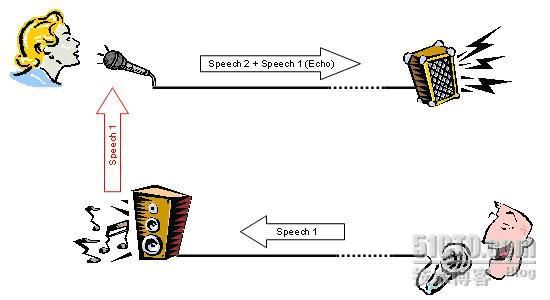
图中的男子说话,语音信号(speech1)传到女士所在的房间,由于空间的反射,形成回音speech1(Echo)重新从麦克风输入,同时叠加了女士的语音信号(speech2)。此时男子将会听到女士的声音叠加了自己的声音,影响了正常的通话质量。此时在女士所在房间应用回音抵消模块,可以抵消掉男子的回音,让男子只听到女士的声音。
2. 由于2-4线转换引入的线路回音(见下图):
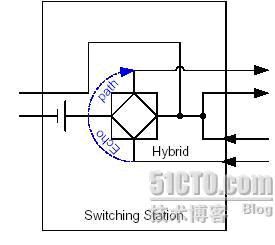
在ADSL Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。
不管产生的原因如何,对语音通讯终端或者语音中继交换机需要做的事情都一样:在发送时,把不需要的回音从语音流中间去掉。
试想一下,对一个至少混合了两个声音的语音流,要把它们分开,然后去掉其中一个,难度何其之大。就像一瓶蓝墨水和一瓶红墨水倒在一起,然后需要把红墨水提取出来,这恐怕不可能了。所以回声消除被认为是神秘和难以理解的技术也就不奇怪了。诚然,如果仅仅单独拿来一段混合了回音的语音信号,要去掉回音也是不可能的(就算是最先进的盲信号分离技术也做不到)。但是,实际上,除了这个混合信号,我们是可以得到产生回音的原始信号的,虽然不同于回音信号。
我们看下面的AEC声学回声消除框图(本图片转载)。
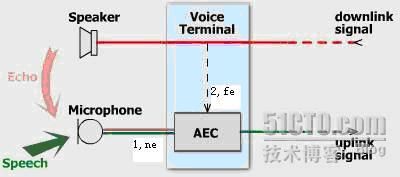
Figure Acoustic Echo Cancellation in a voice communication terminal
其中,我们可以得到两个信号:一个是蓝色和红色混合的信号1,也就是实际需要发送的speech和实际不需要的echo混合而成的语音流;另一个就是虚线的信号2,也就是原始的引起回音的语音。那大家会说,哦,原来回声消除这么简单,直接从混合信号1里面把把这个虚线的2减掉不就行了?请注意,拿到的这个虚线信号2和回音echo是有差异的,直接相减会使语音面目全非。我们把混合信号1叫做近端信号ne,虚线信号2叫做远端参考信号fe,如果没有fe这个信号,回声消除就是不可能完成的任务,就像“巧妇难为无米之炊”。
虽然参考信号fe和echo不完全一样,存在差异,但是二者是高度相关的,这也是echo称之为回音的原因。至少,回音的语义和参考信号是一样的,也还听得懂,但是如果你说一句,马上又听到自己的话回来一句,那是比较难受的。既然fe和echo高度相关,echo又是fe引起的,我们可以把echo表示为fe的数学函数:echo=F(fe)。函数F被称之为回音路径。在声学回声消除里面,函数F表示声音在墙壁,天花板等表面多次反射的物理过程;在线路回声消除里面,函数F表示电子线路的二四线匹配耦合过程。很显然,我们下面要做的工作就是求解函数F。得到函数F就可以从fe计算得到echo,然后从混合信号1里面减掉echo就实现了回声消除。
尽管回声消除是非常复杂的技术,但我们可以简单的描述这种处理方法:
1、房间A的音频会议系统接收到房间B中的声音
2、声音被采样,这一采样被称为回声消除参考
3、随后声音被送到房间A的音箱和声学回声消除器中
4、房间B的声音和房间A的声音一起被房间A的话筒拾取
5、声音被送到声学回声消除器中,与原始的采样进行比较,移除房间B的声音
求解回音路径函数F的过程恐怕就是比较难以表达的数学公式了。鉴于通俗表达数学公式的难度比发现数学公式还难,笔者就不费力解释了。下面这段表达了利用自适应滤波器原理求解函数F的过程。(以下可以跳过)
自适应滤波器
自适应滤波器是以输入和输出信号的统计特性的估计为依据,采取特定算法自动地调整滤波器系数,使其达到最佳滤波特性的一种算法或装置。自适应滤波器可以是连续域的或是离散域的。离散域自适应滤波器由一组抽头延迟线、可变加权系数和自动调整系数的机构组成。附图表示一个离散域自适应滤波器用于模拟未知离散系统的信号流图。自适应滤波器对输入信号序列x(n)的每一个样值,按特定的算法,更新、调整加权系数,使输出信号序列y(n)与期望输出信号序列d(n)相比较的均方误差为最小,即输出信号序列y(n)逼近期望信号序列d(n)。
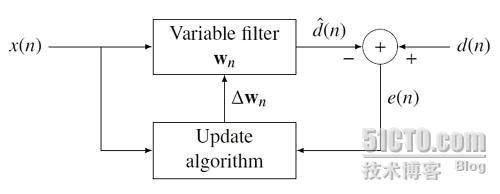
以最小均方误差为准则设计的自适应滤波器的系数可以由维纳-霍甫夫方程解得。
B.维德罗提出的一种方法,能实时求解自适应滤波器系数,其结果接近维纳-霍甫夫方程近似解。这种算法称为最小均方算法或简称 LMS法。这一算法利用最陡下降法,由均方误差的梯度估计从现时刻滤波器系数向量迭代计算下一个时刻的系数向量
式中ks为一负数,它的取值决定算法的收敛性, V【ε2(n)】为均方误差梯度估计,
自适应滤波器应用于通信领域的自动均衡、回声消除、天线阵波束形成,以及其他有关领域信号处理的参数识别、噪声消除、谱估计等方面。对于不同的应用,只是所加输入信号和期望信号不同,基本原理则是相同的。(以上部分可以跳过)
上面这段话表明,需要求解的回音路径函数F就是一个自适应滤波器W(n)收敛的过程。所加输入信号x(n)是fe,期望信号是echo,自适应滤波器收敛后的W(n)就是回音路径函数F。 收敛之后,当实际回音发生,我们把fe通过函数W(n),就可以得到一个很准确的echo,把混合信号直接减去echo,得到实际需要发送的语音speech,完成回声消除任务。
值得注意的两点:
1、 自适应滤波器收敛阶段,期望信号是完全的echo,不能混杂有speech。因为speech和fe是没有关系的,会扰乱W(n)的收敛过程。也就是说要求回声消除算法开始运转后收敛要非常快,最好对方还来不及说话,你一说就收敛好了;收敛好之后,如果对方开始说话,也就是有speech混合过来,这个W(n)系数就不要变化了,需要稳定下来。
2、 回音路径可能是变化的,一旦出现变化,回声消除算法要能判断出来,因为自适应滤波器学习要重新开始,也就是W(n)需要一个新的收敛过程,以逼近新的回音路径函数F。
基本上来说,上面这两点是两难的,一个需要自适应滤波器收敛后保持系数稳定,以保证不受speech说话干扰,另一个需要自适应滤波器随时保持更新状态,以保证能够追踪变化的回音路径。这样一来,仅从数学算法层面,回声消除已经是难上加难!简单地说,回声消除自适应滤波器的设计具有两个互相矛盾的特性,也就是快速收敛和高度的稳定性,如何同时实现这两项特性,正是设计上的主要挑战。
经过上面的分析,相信大家对回声消除的原理和技术有了深刻的理解,这是一门即容易理解又难以实现的技术。
从应用平台来看,根据笔者多年的经验,可以把回声消除分为两大类:基于DSP等实时平台的回声消除技术和基于Windows等非实时平台的回声消除技术。两者的技术难度和重点是不一样的。
三、基于DSP平台的回声消除技术
回声消除技术传统的应用领域是各种嵌入式设备,包括各种电信网络设备和终端设备。网络设备比如交换机,网关等等,终端则包括移动电话终端,视频会议终端等。现代通讯产品里面大量应用了回声消除技术,包括在我们看得到的终端产品(比如手机)和看不到的局端产品(比如交换机)。这种嵌入式设备的共同点就是采用各种型号的DSP芯片作为回声消除的载体。一个有效的回声消除算法需要持续的在一颗DSP芯片上面运行,会遇到以下方面的难点:
实时性与高效性,因为DSP芯片资源有限。虽然自从二十世纪七十年代DSP应用以来,日新月异的硬件芯片技术使许多沉睡在教科书上的信号处理理论算法大规模应用,但是回声消除算法需要的资源还是大得惊人。以视频会议系统,大规模的会议室可以产生超过512ms的回音,要消除这么长延时的回音,即使按照8k赫兹采样率计算,自适应滤波器W(n)的长度都会达到4096个点,这样一方面需要非常大的存储空间来存储W(n),另一方面,W(n)的更新需要的计算量也是成倍增长,同时,W(n)的收敛难度也在加大,传统自适应滤波器的效率很难保证。对于电信设备中的应用,虽然回声消除不需要这么长的延时,但是在交换机等设备中,成本和效率就是生命,所有的处理算法都是按路或按线计算的,对算法的优化效率提出了无止境的要求。相对而言,只有像车载免提这种应用对效率要求不那么高,因为车内空间小,回音延时有限,又不要求多路应用。
传统的回声消除技术是从国外二十世纪七十年代的早期算法发展而来,这类技术的采用一直相当昂贵,提供电信级回声消除硬件应用(包括芯片或者设备)的厂家都是国外的。对于移动网络用户来说,语音品质一直是他们最关切的议题,对电信业者来说,语音也仍是他们最能获利的服务项目,因此语音的品质是不容妥协的。为了满足今日与未来的网路需求,回声消除技术的挑战正在于如何有效地降低成本并持续改善语音品质。
算法级的DSP软件解决方案,也是解决嵌入式设备回音问题的一种途径,对用户也有一定的灵活性,用户只需要把回声消除模块集成到自己的DSP软件中,再简单调整几个相关参数,就能达到较好的回声消除效果。
目前基于DSP的回声消除算法已经比较成熟,市场上也有一批专门的算法/芯片公司的能够对外提供已经优化好的基于DSP的软件回声消除模块:如俄罗斯Spririt DSP、加拿大Octastic Semiconductor、瑞典GIPS、国内科莱特斯科技Conatus Technologies以及美国Adaptive Digital、和GAO Research、英国CSR等等,另外还有美国Fortemedia、Acoustic Technologies和日本OKI等可以提供专用的回声消除DSP芯片。其中性能较好的有Octastic、Conatus、和Spririt这三家,Octastic可以提供完整的从专用芯片、板卡到DSP算法的完整方案,而Conatus和Spririt的回声消除效果更好,值得一提的是Conatus公司是目前市面上唯一提供针对专业视讯会议应用宽带回声消除模块的公司,其音频采样率可以达到48k赫兹。
四、基于Windows平台的回声消除技术
回声消除技术最新的应用领域是基于Windows平台的各种VoIP应用,比如软件视频会议,VoIP软件电话等。当回声消除算法应用到Windows平台,相对于传统的DSP平台,既带来优势,也带来了新的难点。高效性在Windows平台已经不是问题,现在的pc机,拥有丰富的cpu资源和海量的内存资源,再复杂的回声消除算法都可以运行自如。但是,新增加的麻烦比带来的好处要多。
首先,Windows平台是一个非实时的平台,音频的采集和播放对回声消除算法而言,也是非实时的。和DSP平台不一样,DSP平台可以直接控制AD/DA芯片的采集播放,获得实时的音频流(不存在同步问题),但是Windows平台下,应用程序很难在底层直接控制声卡的采集播放,获得的是非实时的音频流,从而带来了采集和播放音频流的同步问题。
实际应用时,传给回声消除算法的两个声音信号(采集的回音信号ne和播放的参考信号fe),必须同步得非常的好。就是说,本地接收到远端说的话以后,要把这些话音数据传给回声消除算法做参考,这是一个算法需要的输入信号;然后再传给声卡,声卡放出来后经过回音路径,这时,本地再采集,然后传给回声消除算法,这是算法需要的另一个输入信号。这里的同步是指:两个信号虽然存在延时,但这个延时必须固定,在时序上要保持连贯,不能一个信号多来几个帧,另外一个信号少来几个帧。如果传给回声消除算法的两个信号同步得不好,即两个信号发生帧错位,就没有办法进行消除了。因为这时系统会变成了非因果系统,比如期望信号收到了,参考信号还没来,时间上都没有因果关系,肯定是没有办法消除的。
实际情况是,在一般的VoIP软件中,接收对方的声音并传到声卡中播放是在一个线程中进行的,而采集本地的声音并传送到对方又是在另一个线程中进行的,而声学回声消除算法在对采集到的声音进行回声消除的同时,还需要播放线程中的数据作为参考,而要同步这两个线程中的数据是非常重要的,因为稍稍有些不同步,声学回声消除算法中的自适应滤波器就会发散,不但消除不了回音,还会破坏原始采集到的声音,使声音难以分辨。
另外,pc机器的声卡种类繁多,各种各样的声卡特性进一步加剧了同步问题的复杂性。所以,同步和声卡等问题对回声消除算法的内部特性提出了更多苛刻的要求。
从上面分析来看,由于Windows平台的非实时性,基于Windows平台的回声消除技术比DSP平台要难得多。
在PC平台语音通讯领域,目前公认音质做得比较好的国外软件是Skype,记得几年前Skype一直是在用瑞典一家叫GIPS(Global IP Sound)公司的语音引擎技术。GIPS是最早介入PC平台语音通讯领域的厂商之一,在改领域具有一定的权威性,其主要优势表现在对IP网络的延时、抖动和丢包等处理较好,基于Windows平台的回音消除也做得不错,不过最近的新版本Skype上已经看不到GIPS的标志了,据说是因为Skype自己研发了一套新的更好的语音引擎的缘故。 目前大家接触最多的采用了GIPS语音引擎技术的通讯软件就是腾讯QQ了,其超级语音的效果普遍评价都还不错。另外微软经过多年的研发,其最新版本的MSN语音特别是回音消除效果终于有了质的提升,目前网上评价也还不错。另外还有一些专业厂商也对外提供包含回音消除功能的语音引擎,如俄罗斯的Spirit DSP、美国的GH Innovation和国内的科莱特斯科技(Conatus Technologies)以及赛声科技(Soft Acoustic)等等。除此之外,网络上还可以下载到一个很好的开源的语音软件Speex也提供了回音消除功能。为了进一步了解目前PC Windows平台回音消除技术的业界水平,笔者对各家的回音消除技术做一个详细的横向对比测试(所有测试都是免提状态)
为了对比,各家语音引擎的版本信息列举如下:
国外厂商:
Skype V3.8.4.182
Spirit DSP(厂家DEMO)
GIPS(QQ 2009beta)
Micorsoft (Windows Live Messenger 2009 V14.0.8064.2006)
GH Innovation(厂家DEMO)
国内厂商:
Conatus Technologies(厂家DEMO)
Soft Acoustic(厂家DEMO)
开源算法:
Speex(V1.2RC1 自己写了测试软件)
测试结果:
| 测试项目
|
Skype |
MSN |
|
Conatus |
Spirit |
Speex |
SoftAcoustic |
GH I |
| 笔记本免提模式,外接麦克风和音箱应用模式的适应性 |
两种模式都无回音 |
笔记本免提模式有时一直有较小回音 |
笔记本免提模式偶尔有较小回音 |
两种模式都无回音 |
笔记本免提模式有时一直有较小回音 |
两种模式都有一直较小回音 |
两种模式有时都会出现较大回音 |
笔记本免提模式一直有很小回音 |
|
单方讲话效果 |
无回音,效果很好 |
基本无回音,效果好 |
基本无回音,效果好 |
无回音,效果很好 |
基本无回音,效果好 |
一直有较小回音,效果差 |
有时有很大回音,效果差 |
基本无回音,效果好 |
|
双方同时讲话效果 |
双方交流流畅无回音,对方声音偶尔有轻微断续 |
双方交流流畅,但对方声音中会夹杂着轻微回音 |
双方交流流畅,但对方声音中会夹杂着一些回音 |
双方交流流畅无回音,对方声音偶尔有轻微断续 |
双方交流流畅,但对方声音中间会夹杂着一些回音 |
双方交流比较流畅,但一直听到一个较小的回音 |
双方交流不流畅,对方声音经常会断续 |
双方交流无回音,但对方声音很小很难听清楚 |
|
麦克风和扬声器相对的位置改变等 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛速度慢,有好几句回音 |
收敛速度慢,有好几句回音 |
收敛比较快,基本没有回音出现。 |
|
CPU重载(CPU负载达到100%)时效果 |
XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 |
XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 |
XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 |
XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 |
XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 |
此项未测 |
XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 |
XP下声音流畅,基本不会出现回音;Vista下不加负载声音都是断续的 |
|
PC和声卡适应性 |
稳定,基本都能消除回音 |
稳定,基本都能消除回音 |
比较稳定,偶尔有些笔记本免提时有回音 |
稳定,基本都能消除回音 |
稳定,基本都能消除回音 |
不稳定,有时无法消除回音 |
不稳定,经常无法消除回音 |
稳定,基本都能消除回音 |
|
噪声抑制
|
噪声抑制效果弱 |
噪声抑制效果一般 |
噪声抑制效果弱 |
噪声抑制效果强 |
噪声抑制效果一般 |
噪声抑制效果强 |
噪声抑制效果强 |
噪声抑制效果强 |
| 自动硬件增益控制和免提时能达到的最大播放音量 |
支持,音量较大 |
支持,音量较小 |
支持,音量适中 |
支持,音量适中 |
支持,音量较小 |
不支持 |
支持,音量较小 |
支持,音量非常小 |
|
整体效果评价(0-10分评分) |
很好,基本没有回音,双方交流很顺畅,9分 |
较好,有的笔记本免提时偶尔有回音且音量较小,双方交流比较顺畅,7.5分 |
较好,有的笔记本免提时偶尔有回音,双方交流顺畅,8分 |
很好,基本没有回音,音量比skype略小,双方交流很顺畅,8.5分 |
较好,有的笔记本免提效果稍差且音量比较小,vista效果稍差,7分 |
不好,一直有个较小的残余回音,双方交流困难,3分 |
不好,经常有完整的回音,感觉不稳定,双方交流比较困难,5分 |
一般,没有回音,但是音量太小,双方交流困难,且VISTA下声音断续,5.5分 |
| 测试项目
|
Skype |
MSN |
|
Conatus |
Spirit |
Speex |
SoftAcoustic |
GH I |
可以看出,Skype、 Conatus和 QQ(GIPS)的效果最好, MSN和Spirit的效果还不错,而GH Innovation、Soft Acoustic效果一般,Speex的效果较差。