Hive实训任务
文章目录
- Hive 实训任务
-
- 一、创建外部表,上传加载数据
- 二、hive基本查询
-
- 1、模糊查询表
- 2、简单查询
-
- (1) limit
- (2) where
- (3) order by
- 三、hive复杂查询
-
- 1、准备数据创建外部表,加载数据
- 2、group by 聚合函数
-
- (1) sum
- (2) max
- (3) count
- 四、hive join 操作
-
- 1、准备数据创建外部表,加载数据
- 2、inner join 内连接
- 3、left outer join 左外连接
- 4、right outer join 右外连接
- 5、全外连接 full outer join
- 6、left semi join 左半开连接
- 7、笛卡尔 join 连接
- 8、map-side join连接
Hive 实训任务
一、创建外部表,上传加载数据
熟练掌握如何创建外部表,加载数据,查询等
先创建一个cx_stu02 外部表,external 指定外部表关键字
row format delimited fileds terminated by ',' stored as textfile
以“,”结尾的行格式分隔的文件存储为文本文件

create external table cx_stu02(
name string,
gender string,
age int
)
row format delimited fields terminated by ',' stored as textfile
然后再linux 准备一个数据文件 并且将它上传到hdfs

加载上传数据,输入命令:load data inpath '/user/stu01/cx_stu01.txt' into table cx_stu02
load data 加载数据 inpath 路径 into table 加载到哪个表

此时对这张表进行查看,数据已经导入进去了
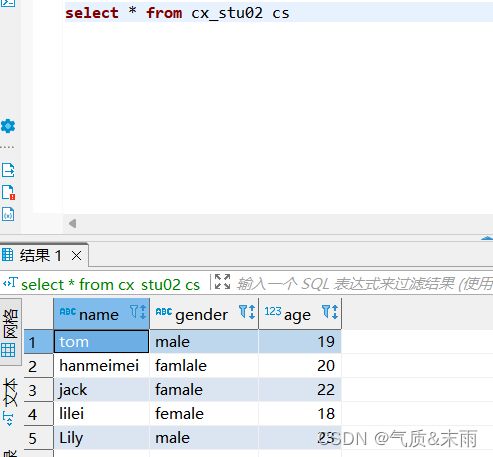
二、hive基本查询
1、模糊查询表
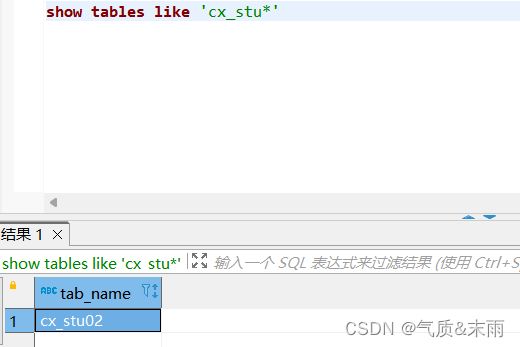
输入命令:show tables like 'cx_stu*' 查询出所有cx_stu 名字开头的表
2、简单查询
(1) limit
输入命令:select * from cx_stu02 limit 0 查询出cx_stu02 表的前两条数据

(2) where
输入命令:select * from cx_stu02 where gender = 'male' limit 2 查询出cx_stu02性别为male的前两条数据

(3) order by
输入命令:select * from cx_stu02 where gender = 'male' order by age desc limit 2
order by排序 desc 倒序 对cx_stu02表 性别为male 的前两条数据进行排序
注意desc 要放在排序字段的后面

三、hive复杂查询
1、准备数据创建外部表,加载数据
首先在linux 本地,准备数据文件cx_stu03.txt

然后将数据文件上传到hdfs ,输入命令:hdfs dfs -put cx_stu03.txt /user/stu01

创建外部表并且导入数据 external 指定外部表

导入数据
输入命令:load data inpath '/user/stu01/cx_stu03.txt' into table cx_stu03

查看表,数据已经导入
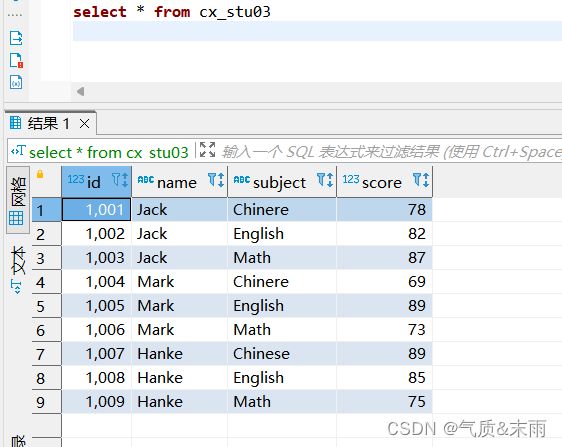
2、group by 聚合函数
(1) sum
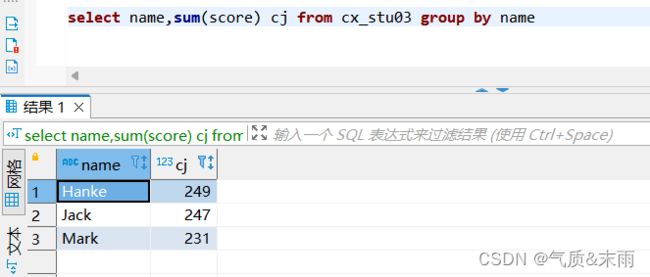
求每个学生的总成绩 输入命令:select name,sum(score) from cx_stu03 group by name
以每个学生为分组,对成绩字段进行求和
having 子句,只有在group by 聚合函数里面用 相当于where子句
求每个学生的总成绩,过滤出总分大于230的学生
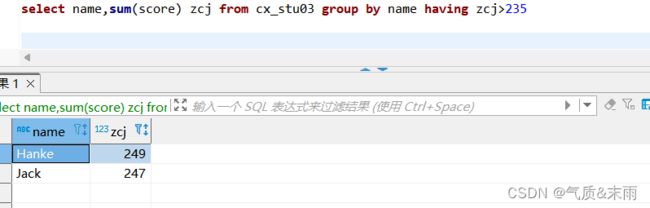
输入命令:select name,sum(score) zcj from cx_stu03 group by name having zcj>235
(2) max
查询出所有科目的最高分,输出命令:select subject,max(score) zgf from cx_stu03 group by subject
以每一个科目名为分组,然后对成绩字段求最大值

(3) count
统计每门课有多少人参加考试
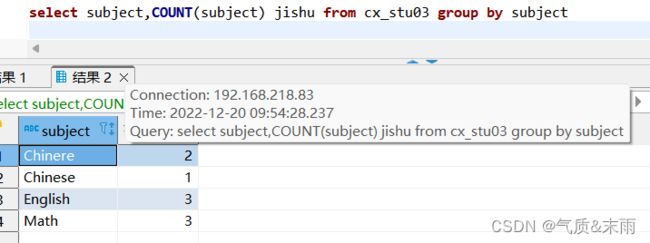
输入命令:select subject,count(subject) jishu from cx_stu03 group by subject
以每一个科目为分组,对每一个科目出现的次数做统计,出现了好多次,就是有几个人参加了考试
四、hive join 操作
Hive 支持常用的sql join 语句,例如内连接,左外连接,右外连接,以及Hive独有的map端连接
1、准备数据创建外部表,加载数据
首先创建三张表,cx_table_employess(员工表),cx_table_department(部门表),cx_table_salary(薪资表),分别导入数据
先在linux上准备好三张表的数据
员工表数据:

部门表数据:
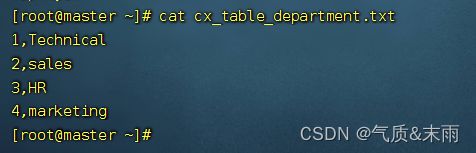
工资表数据:

将他们上传到hdfs

然后下一步进行三张表的创建,并且导入数据
员工表:

导入数据

部门表:
创建表和导入数据,最好分别执行命令,不然容易报错

工资表:
创建表并且导入数据

对三张表进行查询,数据都已经导入进去了

2、inner join 内连接
使用 inner join 进行内连接 员工表 然后用 on 两个表相同的字段进行相等 t1.class=t2.class
注意使用join进行多表关联,一定要有相同的字段 内连接连接两个表都有的相同的字段,里面都有的数据,才会显示出来,比如员工表没有dept_id=4,而部门表有那么连接两个表这个就不会显示,只会显示两个表都有的 可以看到下面查询的结果没有部门id没有4
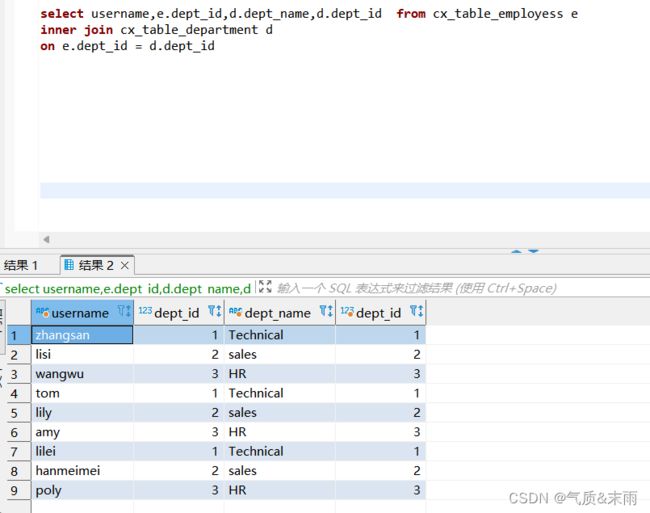
查询员工名字,部门名字,以及薪水 需要连接三张表
跟上面连接两张表是一样的,只是要多来一次 inner join 操作,然后将两个相同的字段用on连接起来

3、left outer join 左外连接
内连接是,两个表连接的字段,相同的才会显示出来,只有一个表有的不会显示出来,
左外连接是是以,左边那个表为基准,只有左边那个表有的才会显示出来,如果左边那个表有的,右边那个表没有,那么右边那个表的那个位置会显示null
查询员工的id和员工工资,把员工表和工资表用左外连接起来 左边的那个表有员工id 8,9右边的没得,那么就会显示为空,右边的

4、right outer join 右外连接
右外连接跟左外连接,刚好相反,以右边那个表为基准,如果左边那个表和on条件匹配的数据则显示出现,不匹配的数据显示NULL
Hive 是处理大数据的组件,经常处理几百G甚至以T为单位的数据,因此在编写sql时,尽量用where条件过滤掉不符合条件的数据,但是对于左外连接和右外连接where条件是在on条件实行之后才会执行,因此优化了Hive sql 执行的效率,在需要使用外连接的场景,尽量使用子查询然后再子查询中使用where条件过滤掉不符合条件的数据
先过滤出员工id小于8的数据,然后再用这个数据与工资表用y右外连接与这个表连接起来,然后查询出员工的id,姓名和工资

5、全外连接 full outer join
全外连接返回所有表中满足where条件的数据,不满足条件的数据用null代替
全外连接得到的结果跟左外连接得到的结果是一样的

6、left semi join 左半开连接
左半开连接就是只查询出满足左边表的数据
左半开连接是内连接的优化,但左边表的一条数据,在右边表存在时,hive就停止扫描,因此效率比join高,但是左半开连接的select和where 关键字只能出现左边表的字段,不能出现右边表的字段,hive不支持右半开连接

7、笛卡尔 join 连接
笛卡尔积连接的结果是将左边表的数据乘以右边表的数据
笛卡尔积连接,就只有一个join 连接

8、map-side join连接
map 端连接是对hve sql 的优化,Hive 是将sql转化为Mapreduce Job任务,因此Map端的连接就是对应的就是Hadoop join 连接中的map端的连接,将小表加载到内存中,以提高hive sql 的执行速度,可以通过下面两种方法,使用 hive sql map 端的 join连接:
1、使用 /*+MAP JOIN*/ 标记

2、第二种方式是设置hive.auto.convent.JOIN 的值设置为true