最全与最好的——CUDA入门教程

开篇一张图,后面听我编
1. 知识准备
1.1 中央处理器(CPU)
中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
中央处理器主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。它与内部存储器(Memory)和输入/输出(I/O)设备合称为电子计算机三大核心部件。
CPU的结构主要包括运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)和它们之间通讯的数据、控制及状态的总线。
简单来说就是:计算单元、控制单元和存储单元,架构如下图所示:
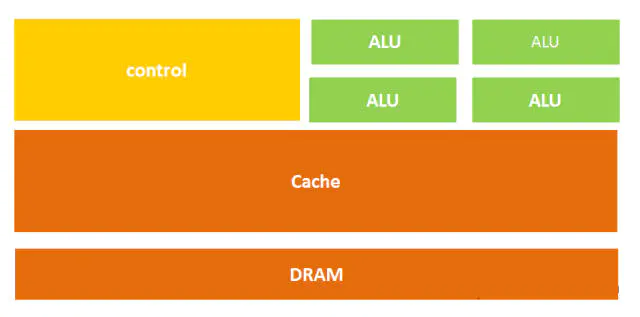
CPU微架构示意图
什么?架构记不住?来,我们换种表示方法:

CPU微架构示意图(改)
嗯,大概就是这个意思。
从字面上我们也很好理解,计算单元主要执行算术运算、移位等操作以及地址运算和转换;存储单元主要用于保存运算中产生的数据以及指令等;控制单元则对指令译码,并且发出为完成每条指令所要执行的各个操作的控制信号。
所以一条指令在CPU中执行的过程是这样的:读取到指令后,通过指令总线送到控制器(黄色区域)中进行译码,并发出相应的操作控制信号;然后运算器(绿色区域)按照操作指令对数据进行计算,并通过数据总线将得到的数据存入数据缓存器(大块橙色区域)。过程如下图所示:
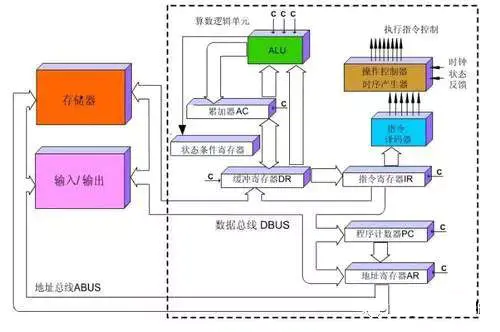
CPU执行指令图
是不是有点儿复杂?没关系,这张图完全不用记住,我们只需要知道,CPU遵循的是冯诺依曼架构,其核心就是:存储程序,顺序执行。
讲到这里,有没有看出问题,没错——在这个结构图中,负责计算的绿色区域占的面积似乎太小了,而橙色区域的缓存Cache和黄色区域的控制单元占据了大量空间。
高中化学有句老生常谈的话叫:结构决定性质,放在这里也非常适用。
因为CPU的架构中需要大量的空间去放置存储单元(橙色部分)和控制单元(黄色部分),相比之下计算单元(绿色部分)只占据了很小的一部分,所以它在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
另外,因为遵循冯诺依曼架构(存储程序,顺序执行),CPU就像是个一板一眼的管家,人们吩咐的事情它总是一步一步来做。但是随着人们对更大规模与更快处理速度的需求的增加,这位管家渐渐变得有些力不从心。
于是,大家就想,能不能把多个处理器放在同一块芯片上,让它们一起来做事,这样效率不就提高了吗?
没错,GPU便由此诞生了。
1.2 显卡
显卡(Video card,Graphics card)全称显示接口卡,又称显示适配器,是计算机最基本配置、最重要的配件之一。显卡作为电脑主机里的一个重要组成部分,是电脑进行数模信号转换的设备,承担输出显示图形的任务。显卡接在电脑主板上,它将电脑的数字信号转换成模拟信号让显示器显示出来,同时显卡还是有图像处理能力,可协助CPU工作,提高整体的运行速度。对于从事专业图形设计的人来说显卡非常重要。 民用和军用显卡图形芯片供应商主要包括AMD(超微半导体)和Nvidia(英伟达)2家。现在的top500计算机,都包含显卡计算核心。在科学计算中,显卡被称为显示加速卡。
为什么GPU特别擅长处理图像数据呢?这是因为图像上的每一个像素点都有被处理的需要,而且每个像素点处理的过程和方式都十分相似,也就成了GPU的天然温床。
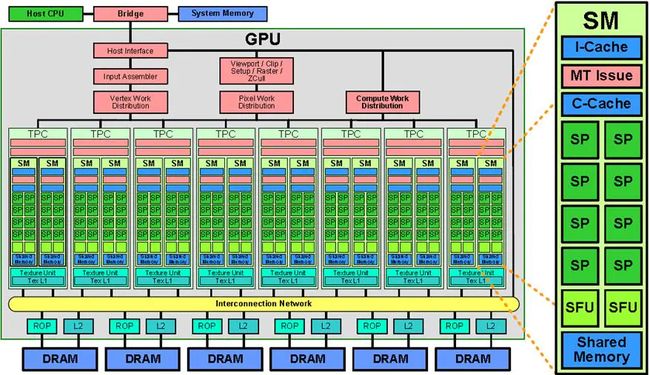
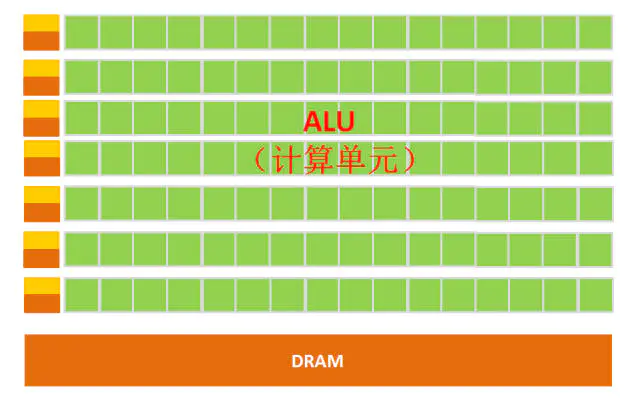
GPU微架构示意图
从架构图我们就能很明显的看出,GPU的构成相对简单,有数量众多的计算单元和超长的流水线,特别适合处理大量的类型统一的数据。
再把CPU和GPU两者放在一张图上看下对比,就非常一目了然了。

GPU的工作大部分都计算量大,但没什么技术含量,而且要重复很多很多次。
但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
借用知乎上某大佬的说法,就像你有个工作需要计算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已;而CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个?
注:GPU中有很多的运算器ALU和很少的缓存cache,缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为线程thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram。
可爱的你如果对CUDA硬件有更多的兴趣,可移步NVIDIA中文官网进一步学习。
1.3 内存
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。 内存是由内存芯片、电路板、金手指等部分组成的。
1.4 显存
显存,也被叫做帧缓存,它的作用是用来存储显卡芯片处理过或者即将提取的渲染数据。如同计算机的内存一样,显存是用来存储要处理的图形信息的部件。
1.5 显卡、显卡驱动、CUDA之间的关系
显卡:(GPU)主流是NVIDIA的GPU,深度学习本身需要大量计算。GPU的并行计算能力,在过去几年里恰当地满足了深度学习的需求。AMD的GPU基本没有什么支持,可以不用考虑。
驱动:没有显卡驱动,就不能识别GPU硬件,不能调用其计算资源。但是呢,NVIDIA在Linux上的驱动安装特别麻烦,尤其对于新手简直就是噩梦。得屏蔽第三方显卡驱动。下面会给出教程。
CUDA:是NVIDIA推出的只能用于自家GPU的并行计算框架。只有安装这个框架才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
查看显卡驱动信息(以实验室服务器为例)
ssh [email protected]
输入服务器密码登陆
然后,进入cuda
cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
运行其中的可执行文件
./deviceQuery
得到如下信息
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 4 CUDA Capable device(s)
Device 0: "GeForce GTX 1080 Ti"
CUDA Driver Version / Runtime Version 9.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 11171 MBytes (11713708032 bytes)
(28) Multiprocessors, (128) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1620 MHz (1.62 GHz)
Memory Clock rate: 5505 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 2883584 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 1: "GeForce GTX 1080 Ti"
CUDA Driver Version / Runtime Version 9.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 11172 MBytes (11715084288 bytes)
(28) Multiprocessors, (128) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1620 MHz (1.62 GHz)
Memory Clock rate: 5505 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 2883584 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 3 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 2: "GeForce GTX 1080 Ti"
CUDA Driver Version / Runtime Version 9.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 11172 MBytes (11715084288 bytes)
(28) Multiprocessors, (128) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1620 MHz (1.62 GHz)
Memory Clock rate: 5505 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 2883584 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 130 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Device 3: "GeForce GTX 1080 Ti"
CUDA Driver Version / Runtime Version 9.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 11172 MBytes (11715084288 bytes)
(28) Multiprocessors, (128) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1620 MHz (1.62 GHz)
Memory Clock rate: 5505 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 2883584 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 131 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
> Peer access from GeForce GTX 1080 Ti (GPU0) -> GeForce GTX 1080 Ti (GPU1) : Yes
> Peer access from GeForce GTX 1080 Ti (GPU0) -> GeForce GTX 1080 Ti (GPU2) : No
> Peer access from GeForce GTX 1080 Ti (GPU0) -> GeForce GTX 1080 Ti (GPU3) : No
> Peer access from GeForce GTX 1080 Ti (GPU1) -> GeForce GTX 1080 Ti (GPU0) : Yes
> Peer access from GeForce GTX 1080 Ti (GPU1) -> GeForce GTX 1080 Ti (GPU2) : No
> Peer access from GeForce GTX 1080 Ti (GPU1) -> GeForce GTX 1080 Ti (GPU3) : No
> Peer access from GeForce GTX 1080 Ti (GPU2) -> GeForce GTX 1080 Ti (GPU0) : No
> Peer access from GeForce GTX 1080 Ti (GPU2) -> GeForce GTX 1080 Ti (GPU1) : No
> Peer access from GeForce GTX 1080 Ti (GPU2) -> GeForce GTX 1080 Ti (GPU3) : Yes
> Peer access from GeForce GTX 1080 Ti (GPU3) -> GeForce GTX 1080 Ti (GPU0) : No
> Peer access from GeForce GTX 1080 Ti (GPU3) -> GeForce GTX 1080 Ti (GPU1) : No
> Peer access from GeForce GTX 1080 Ti (GPU3) -> GeForce GTX 1080 Ti (GPU2) : Yes
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 9.0, CUDA Runtime Version = 8.0, NumDevs = 4, Device0 = GeForce GTX 1080 Ti, Device1 = GeForce GTX 1080 Ti, Device2 = GeForce GTX 1080 Ti, Device3 = GeForce GTX 1080 Ti
Result = PASS
大家可以在自己PC或者工作机上尝试一下。
再啰嗦两句
GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。
但有一点需要强调,虽然GPU是为了图像处理而生的,但是我们通过前面的介绍可以发现,它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以现在GPU不仅可以在图像处理领域大显身手,它还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
所以GPU也可以认为是一种较通用的芯片。
2. CUDA软件构架
CUDA是一种新的操作GPU计算的硬件和软件架构,它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。目前Tesla架构具有在笔记本电脑、台式机、工作站和服务器上的广泛可用性,配以C/C++语言的编程环境和CUDA软件,使这种架构得以成为最优秀的超级计算平台。

CUDA软件层次结构
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
3. 编程模型
CUDA程序构架分为两部分:Host和Device。一般而言,Host指的是CPU,Device指的是GPU。在CUDA程序构架中,主程序还是由CPU来执行,而当遇到数据并行处理的部分,CUDA 就会将程序编译成GPU能执行的程序,并传送到GPU。而这个程序在CUDA里称做核(kernel)。CUDA允许程序员定义称为核的C语言函数,从而扩展了C语言,在调用此类函数时,它将由N个不同的CUDA线程并行执行N次,这与普通的C语言函数只执行一次的方式不同。执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。在 CUDA 程序中,主程序在调用任何GPU内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。
3.1 线程层次结构
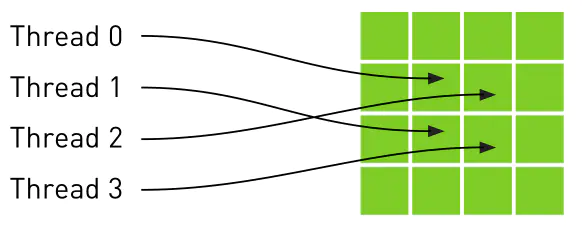
在GPU中要执行的线程,根据最有效的数据共享来创建块(Block),其类型有一维、二维或三维。在同一个块内的线程可彼此协作,通过一些共享存储器来共享数据,并同步其执行来协调存储器访问。一个块中的所有线程都必须位于同一个处理器核心中。因而,一个处理器核心的有限存储器资源制约了每个块的线程数量。在早期的NVIDIA 架构中,一个线程块最多可以包含 512个线程,而在后期出现的一些设备中则最多可支持1024个线程。一般GPGPU程序线程数目是很多的,所以不能把所有的线程都塞到同一个块里。但一个内核可由多个大小相同的线程块同时执行,因而线程总数应等于每个块的线程数乘以块的数量。这些同样维度和大小的块将组织为一个一维或二维线程块网格(Grid)。具体框架如下图所示。
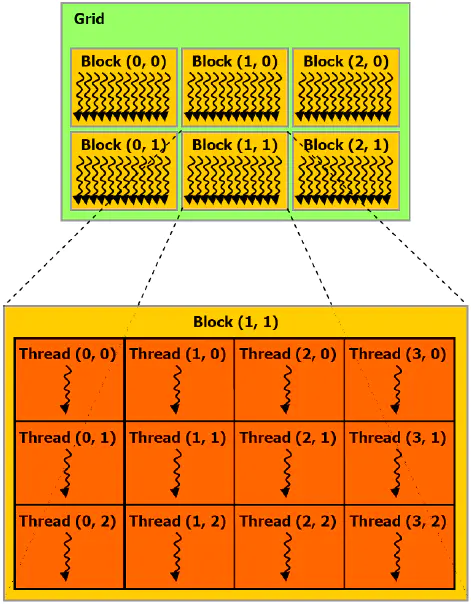
线程块网格
NOTICE:
线程(Thread)
一般通过GPU的一个核进行处理。(可以表示成一维,二维,三维,具体下面再细说)。
线程块(Block)
- 由多个线程组成(可以表示成一维,二维,三维,具体下面再细说)。
- 各block是并行执行的,block间无法通信,也没有执行顺序。
- 注意线程块的数量限制为不超过65535(硬件限制)。
线程格(Grid)
由多个线程块组成(可以表示成一维,二维,三维,具体下面再细说)。
线程束
在CUDA架构中,线程束是指一个包含32个线程的集合,这个线程集合被“编织在一起”并且“步调一致”的形式执行。在程序中的每一行,线程束中的每个线程都将在不同数据上执行相同的命令。
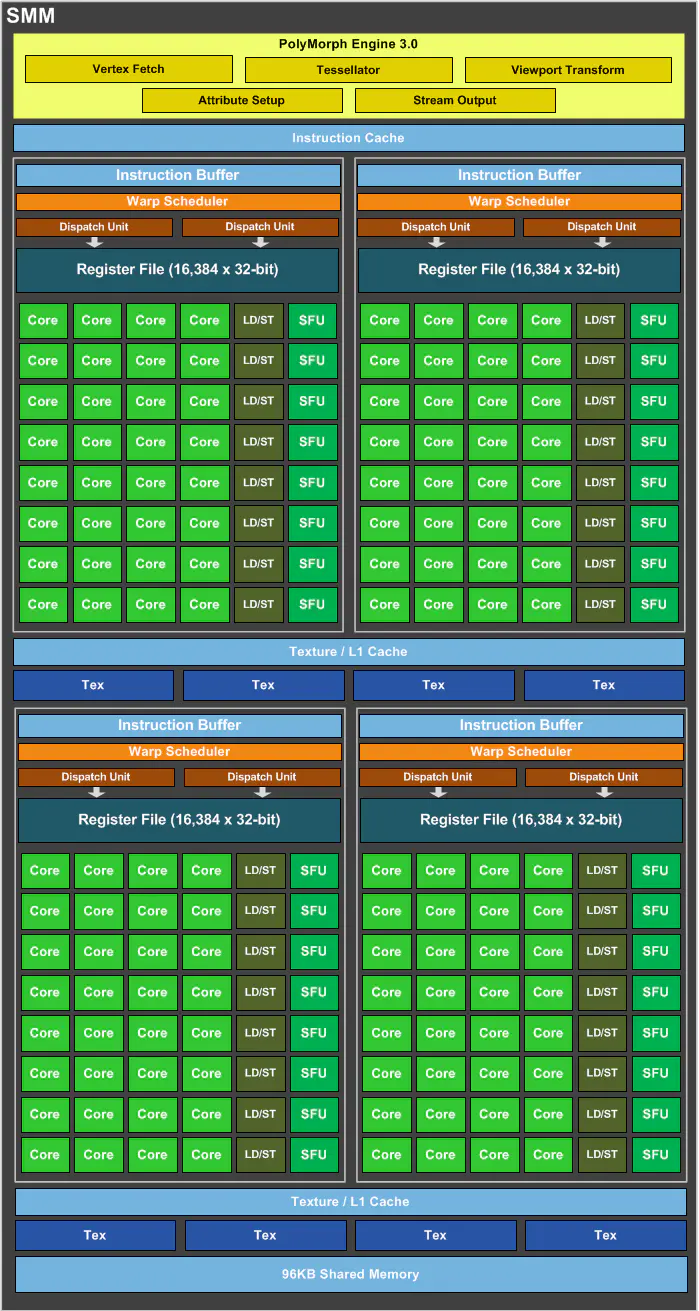
从硬件上看
SP:最基本的处理单元,streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。
从软件上看
thread:一个CUDA的并行程序会被以许多个threads来执行。
block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
grid:多个blocks则会再构成grid。
warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT。
3.2 存储器层次结构
CUDA设备拥有多个独立的存储空间,其中包括:全局存储器、本地存储器、共享存储器、常量存储器、纹理存储器和寄存器,如图
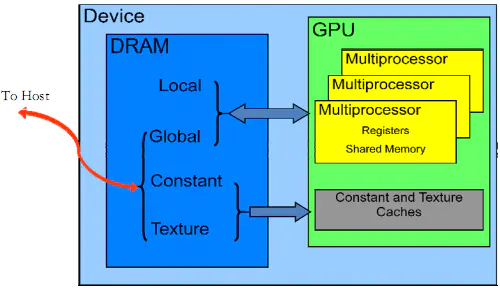
CUDA设备上的存储器
NOTICE:
主机(Host)
将CPU及系统的内存(内存条)称为主机。
设备(Device)
将GPU及GPU本身的显示内存称为设备。
动态随机存取存储器(DRAM)
DRAM(Dynamic Random Access Memory),即动态随机存取存储器,最为常见的系统内存。DRAM只能将数据保持很短的时间。为了保持数据,DRAM使用电容存储,所以必须隔一段时间刷新(refresh)一次,如果存储单元没有被刷新,存储的信息就会丢失。 (关机就会丢失数据)
CUDA线程可在执行过程中访问多个存储器空间的数据,如下图所示其中:
- 每个线程都有一个私有的本地存储器。
- 每个线程块都有一个共享存储器,该存储器对于块内的所有线程都是可见的,并且与块具有相同的生命周期。
- 所有线程都可访问相同的全局存储器。
- 此外还有两个只读的存储器空间,可由所有线程访问,这两个空间是常量存储器空间和纹理存储器空间。全局、固定和纹理存储器空间经过优化,适于不同的存储器用途。纹理存储器也为某些特殊的数据格式提供了不同的寻址模式以及数据过滤,方便Host对流数据的快速存取。
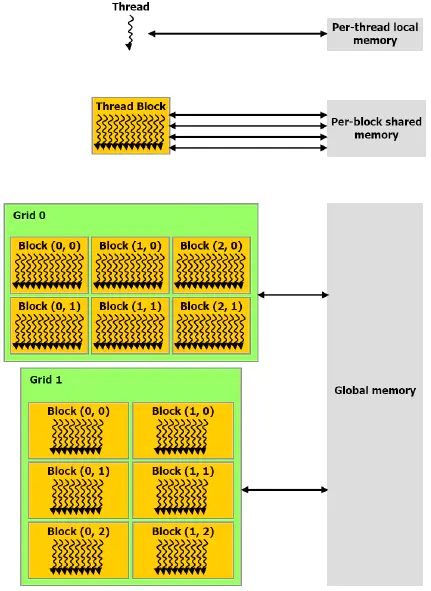
存储器的应用层次
3.3 主机(Host)和设备(Device)
如下图所示,CUDA假设线程可在物理上独立的设备上执行,此类设备作为运行C语言程序的主机的协处理器操作。内核在GPU上执行,而C语言程序的其他部分在CPU上执行(即串行代码在主机上执行,而并行代码在设备上执行)。此外,CUDA还假设主机和设备均维护自己的DRAM,分别称为主机存储器和设备存储器。因而,一个程序通过调用CUDA运行库来管理对内核可见的全局、固定和纹理存储器空间。这种管理包括设备存储器的分配和取消分配,还包括主机和设备存储器之间的数据传输。
4. CUDA软硬件
4.1 CUDA术语
由于CUDA中存在许多概念和术语,诸如SM、block、SP等多个概念不容易理解,将其与CPU的一些概念进行比较,如下表所示。
| CPU | GPU | 层次 |
|---|---|---|
| 算术逻辑和控制单元 | 流处理器(SM) | 硬件 |
| 算术单元 | 批量处理器(SP) | 硬件 |
| 进程 | Block | 软件 |
| 线程 | thread | 软件 |
| 调度单位 | Warp | 软件 |
4.2 硬件利用率
当为一个GPU分配一个内核函数,我们关心的是如何才能充分利用GPU的计算能力,但由于不同的硬件有不同的计算能力,SM一次最多能容纳的线程数也不尽相同,SM一次最多能容纳的线程数量主要与底层硬件的计算能力有关,如下表显示了在不同的计算能力的设备上,每个线程块上开启不同数量的线程时设备的利用率。
| 计算能力 每个线 程块的线程数 | 1.0 | 1.1 | 1.2 | 1.3 | 2.0 | 2.1 | 3.0 |
|---|---|---|---|---|---|---|---|
| 64 | 67 | 50 | 50 | 50 | 33 | 33 | 50 |
| 96 | 100 | 100 | 75 | 75 | 50 | 50 | 75 |
| 128 | 100 | 100 | 100 | 100 | 67 | 67 | 100 |
| 192 | 100 | 100 | 94 | 94 | 100 | 100 | 94 |
| 96 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| ··· | ··· |
查看显卡利用率 (以实验室服务器为例)
输入以下命令
nvidia-smi
Thu Aug 23 21:06:36 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.130 Driver Version: 384.130 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... Off | 00000000:02:00.0 Off | N/A |
| 29% 41C P0 58W / 250W | 0MiB / 11171MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 108... Off | 00000000:03:00.0 Off | N/A |
| 33% 47C P0 57W / 250W | 0MiB / 11172MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 108... Off | 00000000:82:00.0 Off | N/A |
| 36% 49C P0 59W / 250W | 0MiB / 11172MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX 108... Off | 00000000:83:00.0 Off | N/A |
| 33% 46C P0 51W / 250W | 0MiB / 11172MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
5. 并行计算
5.1 并发性
CUDA将问题分解成线程块的网格,每块包含多个线程。快可以按任意顺序执行。不过在某个时间点上,只有一部分块处于执行中。一旦被调用到GUP包含的N个“流处理器簇(SM)”中的一个上执行,一个块必须从开始到结束。网格中的块可以被分配到任意一个有空闲槽的SM上。起初,可以采用“轮询调度”策略,以确保分配到每一个SM上的块数基本相同。对绝大多数内核程序而言,分块的数量应该是GPU中物理SM数量的八倍或更多倍。
以一个军队比喻,假设有一支由士兵(线程)组成的部队(网格)。部队被分成若干个连(块),每个连队由一位连长来指挥。按照32名士兵一个班(一个线程束),连队又进一步分成若干个班,每个班由一个班长来指挥。

基于GPU的线程视图
要执行某个操作,总司令(内核程序/ 主机程序)必须提供操作名称及相应的数据。每个士兵(线程)只处理分配给他的问题中的一小块。在连长(负责一个块)或班长(负责一个束)的控制下,束与束之间的线程或者一个束内部的线程之间,要经常地交换数据。但是,连队(块)之间的协同就得由总司令(内核函数/ 主机程序)来控制。
5.2 局部性
对于GPU程序设计,程序员必须处理局部性。对于一个给定的工作,他需要事先思考需要哪些工具或零件(即存储地址或数据结构),然后一次性地把他们从硬件仓库(全局内存)可能把与这些数据相关的不同工作都执行了,避免发生“取来--存回--为了下一个工作再取”。
5.3 缓存一致性
GPU与CPU在缓存上的一个重要差别就是“缓存一致性”问题。对于“缓存一致”的系统,一个内存的写操作需要通知所有核的各个级别的缓存。因此,无论何时,所有的处理器核看到的内存视图是完全一样的。随着处理器中核数量的增多,这个“通知”的开销迅速增大,使得“缓存一致性”成为限制一个处理器中核数量不能太多的一重要因素。“缓存一致”系统中最坏的情况是,一个内存操作会强迫每个核的缓存都进行更新,进而每个核都要对相邻的内存单元写操作。
相比之下,非“缓存一致”系统不会自动地更新其他核的缓存。它需要由程序员写清楚每个处理器核输出的各自不同的目标区域。从程序的视角看,这支持一个核仅负责一个输出或者一个小的输出集。通常,CPU遵循“缓存一致性”原则,而GPU则不是。故GPU能够扩展到一个芯片内具有大数量的核心(流处理器簇)。
5.4 弗林分类法
根据弗林分类法,计算机的结构类型有:
SIMD--单指令,多数据
MIMD--多指令,多数据
SISD--单指令,单数据
MISD--多指令,单数据
5.5 分条 / 分块
CUDA提供的简单二维网格模型。对于很多问题,这样的模型就足够了。如果在一个块内,你的工作是线性分布的,那么你可以很好地将其他分解成CUDA块。由于在一个SM内,最多可以分配16个块,而在一个GPU内有16个(有些是32个)SM,所以问题分成256个甚至更多的块都可以。实际上,我们更倾向于把一个块内的元素总数限制为128、256、或者512,这样有助于在一个典型的数据集内划分出更多数量的块。
5.6 快速傅氏变换(FFT)
FFT: FFT(Fast Fourier Transformation)是离散傅氏变换(DFT)的快速算法。即为快速傅氏变换。它是根据离散傅氏变换的奇、偶、虚、实等特性,对离散傅立叶变换的算法进行改进获得的。
由于不是刚需,这里不展开讲。好奇的你可以点击楼下时光机,通过下面的教程进行学习。
FFT(最详细最通俗的入门手册)
5.7 CUDA计算能力的含义
体现GPU计算能力的两个重要特征:
1)CUDA核的个数;
2)存储器大小。
描述GPU性能的两个重要指标: :
1)计算性能峰值;
2)存储器带宽。
参考
1.CUDA计算能力的含义
2.CUDA GPUs
6. 实践
6.1 Ubuntu 系统下环境搭建
6.1.1 系统要求
要搭建 CUDA 环境,我们需要自己的计算机满足以下这三个条件:
1. 有至少一颗支持 CUDA 的 GPU(我的是GeForece GT 650M)
2. 有满足版本要求的 gcc 编译器和链接工具
3. 有 NVIDIA 提供的 CUDA 工具包(点击神奇的小链接下载)
6.1.2 准备工作
下面,我们一步一步来验证自己的系统是否满足安装要求。
Step 1: 验证计算机是否拥有至少一颗支持 CUDA 的 GPU
打开终端(Ctrl + Alt + T),键入以下命令:
lspci | grep -i nvidia
可以看到以下内容(结果因人而异,与具体的GPU有关)

看到这个就说明至少有一颗支持 CUDA 的 GPU,可以进入下一步了。
Step 2: 验证一下自己操作系统的版本
键入命令:
lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.4 LTS
Release: 16.04
Codename: xenial
更多信息请移步Ubuntu查看版本信息
Step 3: 验证 gcc 编译器的版本
键入命令:
gcc --version
或者
gcc -v
得到如下信息
gcc (Ubuntu 5.4.0-6ubuntu1~16.04.10) 5.4.0 20160609
Copyright (C) 2015 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Step 4: 验证系统内核版本
键入命令:
uname -r
得到如下信息

对照官方提供的对各种 Linux 发行版的安装要求进行安装
6.1.3 搭建 CUDA 环境
Step 1: 安装 CUDA 工具包
在前面几项验证都顺利通过以后就来到最关键的一步。首先下载对应自己系统版本的 CUDA 工具包(以CUDA Toolkit 9.2 为例),然后进入到安装包所在目录:
sudo dpkg -i cuda-repo-ubuntu1604-9-2-local_9.2.148-1_amd64.deb
sudo apt-key add /var/cuda-repo-/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda
NOTICE:
Other installation options are available in the form of meta-packages. For example, to install all the library packages, replace "cuda" with the "cuda-libraries-9-2" meta package. For more information on all the available meta packages click here.
此时静静地等待安装完成。不出意外,一段时间后安装完成了。
Step 2: 设置环境变量
首先在 PATH 变量中加入 /usr/local/cuda-9.2/bin,在Terminal中执行:
export PATH=/usr/local/cuda-9.2/bin:$PATH
然后在 LD_LIBRARY_PATH 变量中添加 /usr/local/cuda-9.2/lib64,执行:
export LD_LIBRARY_PATH=/usr/local/cuda-9.2/lib64:$LD_LIBRARY_PATH
Step 3: 验证环境搭建是否成功
首先执行命令:
nvcc -V
关于测试...聪明的你一定想起来了,我们前面是讲过怎么做的。
对,没错,就在1.5小节,话不多说,自行上翻吧。
看到通过测试,到这里,64位 Ubuntu 16.04 系统下 CUDA 环境搭建就完成了。
6.2 CUDA编程
6.2.1 核函数
1. 在GPU上执行的函数通常称为核函数。
2. 一般通过标识符__global__修饰,调用通过<<<参数1,参数2>>>,用于说明内核函数中的线程数量,以及线程是如何组织的。
3. 以线程格(Grid)的形式组织,每个线程格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。
4.是以block为单位执行的。
5. 叧能在主机端代码中调用。
6. 调用时必须声明内核函数的执行参数。
7. 在编程时,必须先为kernel函数中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界或报错,甚至导致蓝屏和死机。
看完基本知识,装好CUDA以后,就可以开始写第一个CUDA程序了:
#include
int main(){
printf("Hello world!\n");
}
慢着,这个程序和C有什么区别?用到显卡了吗?
答:没有区别,没用显卡。如果你非要用显卡干点什么事情的话,可以改成这个样子:
/*
* @file_name HelloWorld.cu 后缀名称.cu
*/
#include
#include //头文件
//核函数声明,前面的关键字__global__
__global__ void kernel( void ) {
}
int main( void ) {
//核函数的调用,注意<<<1,1>>>,第一个1,代表线程格里只有一个线程块;第二个1,代表一个线程块里只有一个线程。
kernel<<<1,1>>>();
printf( "Hello, World!\n" );
return 0;
}
6.2.2 dim3结构类型
- dim3是基于uint3定义的矢量类型,相当亍由3个unsigned int型组成的结构体。uint3类型有三个数据成员
unsigned int x;unsigned int y;unsigned int z; - 可使用于一维、二维或三维的索引来标识线程,构成一维、二维或三维线程块。
dim3结构类型变量用在核函数调用的<<<,>>>中。- 相关的几个内置变量
4.1.threadIdx,顾名思义获取线程thread的ID索引;如果线程是一维的那么就取threadIdx.x,二维的还可以多取到一个值threadIdx.y,以此类推到三维threadIdx.z。
4.2.blockIdx,线程块的ID索引;同样有blockIdx.x,blockIdx.y,blockIdx.z。
4.3.blockDim,线程块的维度,同样有blockDim.x,blockDim.y,blockDim.z。
4.4.gridDim,线程格的维度,同样有gridDim.x,gridDim.y,gridDim.z。 - 对于一维的
block,线程的threadID=threadIdx.x。 - 对于大小为
(blockDim.x, blockDim.y)的 二维block,线程的threadID=threadIdx.x+threadIdx.y*blockDim.x。- 对于大小为
(blockDim.x, blockDim.y, blockDim.z)的 三维block,线程的threadID=threadIdx.x+threadIdx.y*blockDim.x+threadIdx.z*blockDim.x*blockDim.y。 - 对于计算线程索引偏移增量为已启动线程的总数。如
stride = blockDim.x * gridDim.x; threadId += stride。
- 对于大小为
6.2.3 函数修饰符
1.__global__,表明被修饰的函数在设备上执行,但在主机上调用。
__device__,表明被修饰的函数在设备上执行,但只能在其他__device__函数或者__global__函数中调用。
6.2.4 常用的GPU内存函数
cudaMalloc()
1. 函数原型: cudaError_t cudaMalloc (void **devPtr, size_t size)。
2. 函数用处:与C语言中的malloc函数一样,只是此函数在GPU的内存你分配内存。
3. 注意事项:
3.1. 可以将cudaMalloc()分配的指针传递给在设备上执行的函数;
3.2. 可以在设备代码中使用cudaMalloc()分配的指针进行设备内存读写操作;
3.3. 可以将cudaMalloc()分配的指针传递给在主机上执行的函数;
3.4. 不可以在主机代码中使用cudaMalloc()分配的指针进行主机内存读写操作(即不能进行解引用)。
cudaMemcpy()
1. 函数原型:cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)。
2. 函数作用:与c语言中的memcpy函数一样,只是此函数可以在主机内存和GPU内存之间互相拷贝数据。
3. 函数参数:cudaMemcpyKind kind表示数据拷贝方向,如果kind赋值为cudaMemcpyDeviceToHost表示数据从设备内存拷贝到主机内存。
4. 与C中的memcpy()一样,以同步方式执行,即当函数返回时,复制操作就已经完成了,并且在输出缓冲区中包含了复制进去的内容。
5. 相应的有个异步方式执行的函数cudaMemcpyAsync(),这个函数详解请看下面的流一节有关内容。
cudaFree()
1. 函数原型:cudaError_t cudaFree ( void* devPtr )。
2. 函数作用:与c语言中的free()函数一样,只是此函数释放的是cudaMalloc()分配的内存。
下面实例用于解释上面三个函数
#include
#include
__global__ void add( int a, int b, int *c ) {
*c = a + b;
}
int main( void ) {
int c;
int *dev_c;
//cudaMalloc()
cudaMalloc( (void**)&dev_c, sizeof(int) );
//核函数执行
add<<<1,1>>>( 2, 7, dev_c );
//cudaMemcpy()
cudaMemcpy( &c, dev_c, sizeof(int),cudaMemcpyDeviceToHost ) ;
printf( "2 + 7 = %d\n", c );
//cudaFree()
cudaFree( dev_c );
return 0;
}
6.2.5 GPU内存分类
全局内存
通俗意义上的设备内存。
共享内存
1. 位置:设备内存。
2. 形式:关键字__shared__添加到变量声明中。如__shared__ float cache[10]。
3. 目的:对于GPU上启动的每个线程块,CUDAC编译器都将创建该共享变量的一个副本。线程块中的每个线程都共享这块内存,但线程却无法看到也不能修改其他线程块的变量副本。这样使得一个线程块中的多个线程能够在计算上通信和协作。
常量内存
1. 位置:设备内存
2. 形式:关键字__constant__添加到变量声明中。如__constant__ float s[10];。
3. 目的:为了提升性能。常量内存采取了不同于标准全局内存的处理方式。在某些情况下,用常量内存替换全局内存能有效地减少内存带宽。
4. 特点:常量内存用于保存在核函数执行期间不会发生变化的数据。变量的访问限制为只读。NVIDIA硬件提供了64KB的常量内存。不再需要cudaMalloc()或者cudaFree(),而是在编译时,静态地分配空间。
5. 要求:当我们需要拷贝数据到常量内存中应该使用cudaMemcpyToSymbol(),而cudaMemcpy()会复制到全局内存。
6. 性能提升的原因:
6.1. 对常量内存的单次读操作可以广播到其他的“邻近”线程。这将节约15次读取操作。(为什么是15,因为“邻近”指半个线程束,一个线程束包含32个线程的集合。)
6.2. 常量内存的数据将缓存起来,因此对相同地址的连续读操作将不会产生额外的内存通信量。
纹理内存
1. 位置:设备内存
2. 目的:能够减少对内存的请求并提供高效的内存带宽。是专门为那些在内存访问模式中存在大量空间局部性的图形应用程序设计,意味着一个线程读取的位置可能与邻近线程读取的位置“非常接近”。如下图:
3. 纹理变量(引用)必须声明为文件作用域内的全局变量。
4. 形式:分为一维纹理内存 和 二维纹理内存。
4.1. 一维纹理内存
4.1.1. 用texture<类型>类型声明,如texture。texIn
4.1.2. 通过cudaBindTexture()绑定到纹理内存中。
4.1.3. 通过tex1Dfetch()来读取纹理内存中的数据。
4.1.4. 通过cudaUnbindTexture()取消绑定纹理内存。
4.2. 二维纹理内存
4.2.1. 用texture<类型,数字>类型声明,如texture。texIn
4.2.2. 通过cudaBindTexture2D()绑定到纹理内存中。
4.2.3. 通过tex2D()来读取纹理内存中的数据。
4.2.4. 通过cudaUnbindTexture()取消绑定纹理内存。
固定内存
1. 位置:主机内存。
2. 概念:也称为页锁定内存或者不可分页内存,操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中。因此操作系统能够安全地使某个应用程序访问该内存的物理地址,因为这块内存将不会破坏或者重新定位。
3. 目的:提高访问速度。由于GPU知道主机内存的物理地址,因此可以通过“直接内存访问DMA(Direct Memory Access)技术来在GPU和主机之间复制数据。由于DMA在执行复制时无需CPU介入。因此DMA复制过程中使用固定内存是非常重要的。
4. 缺点:使用固定内存,将失去虚拟内存的所有功能;系统将更快的耗尽内存。
5. 建议:对cudaMemcpy()函数调用中的源内存或者目标内存,才使用固定内存,并且在不再需要使用它们时立即释放。
6. 形式:通过cudaHostAlloc()函数来分配;通过cudaFreeHost()释放。
7. 只能以异步方式对固定内存进行复制操作。
原子性
1. 概念:如果操作的执行过程不能分解为更小的部分,我们将满足这种条件限制的操作称为原子操作。
2. 形式:函数调用,如atomicAdd(addr,y)将生成一个原子的操作序列,这个操作序列包括读取地址addr处的值,将y增加到这个值,以及将结果保存回地址addr。
6.2.6 常用线程操作函数
同步方法__syncthreads(),这个函数的调用,将确保线程块中的每个线程都执行完__syscthreads()前面的语句后,才会执行下一条语句。
使用事件来测量性能
1. 用途:为了测量GPU在某个任务上花费的时间。CUDA中的事件本质上是一个GPU时间戳。由于事件是直接在GPU上实现的。因此不适用于对同时包含设备代码和主机代码的混合代码设计。
2. 形式:首先创建一个事件,然后记录事件,再计算两个事件之差,最后销毁事件。如:
cudaEvent_t start, stop;
cudaEventCreate( &start );
cudaEventCreate( &stop );
cudaEventRecord( start, 0 );
//do something
cudaEventRecord( stop, 0 );
float elapsedTime;
cudaEventElapsedTime( &elapsedTime,start, stop );
cudaEventDestroy( start );
cudaEventDestroy( stop );
6.2.7 流
- 扯一扯:并发重点在于一个极短时间段内运行多个不同的任务;并行重点在于同时运行一个任务。
- 任务并行性:是指并行执行两个或多个不同的任务,而不是在大量数据上执行同一个任务。
- 概念:CUDA流表示一个GPU操作队列,并且该队列中的操作将以指定的顺序执行。我们可以在流中添加一些操作,如核函数启动,内存复制以及事件的启动和结束等。这些操作的添加到流的顺序也是它们的执行顺序。可以将每个流视为GPU上的一个任务,并且这些任务可以并行执行。
- 硬件前提:必须是支持设备重叠功能的GPU。支持设备重叠功能,即在执行一个核函数的同时,还能在设备与主机之间执行复制操作。
- 声明与创建:声明
cudaStream_t stream;,创建cudaSteamCreate(&stream);。 cudaMemcpyAsync():前面在cudaMemcpy()中提到过,这是一个以异步方式执行的函数。在调用cudaMemcpyAsync()时,只是放置一个请求,表示在流中执行一次内存复制操作,这个流是通过参数stream来指定的。当函数返回时,我们无法确保复制操作是否已经启动,更无法保证它是否已经结束。我们能够得到的保证是,复制操作肯定会当下一个被放入流中的操作之前执行。传递给此函数的主机内存指针必须是通过cudaHostAlloc()分配好的内存。(流中要求固定内存)- 流同步:通过
cudaStreamSynchronize()来协调。 - 流销毁:在退出应用程序之前,需要销毁对GPU操作进行排队的流,调用
cudaStreamDestroy()。 - 针对多个流:
9.1. 记得对流进行同步操作。
9.2. 将操作放入流的队列时,应采用宽度优先方式,而非深度优先的方式,换句话说,不是首先添加第0个流的所有操作,再依次添加后面的第1,2,…个流。而是交替进行添加,比如将a的复制操作添加到第0个流中,接着把a的复制操作添加到第1个流中,再继续其他的类似交替添加的行为。
9.3. 要牢牢记住操作放入流中的队列中的顺序影响到CUDA驱动程序调度这些操作和流以及执行的方式。
TIPS:
- 当线程块的数量为GPU中处理数量的2倍时,将达到最优性能。
- 核函数执行的第一个计算就是计算输入数据的偏移。每个线程的起始偏移都是0到线程数量减1之间的某个值。然后,对偏移的增量为已启动线程的总数。
6.2.8 这是一个栗子
我们尝试用一个程序来比较cuda/c在GPU/CPU的运行效率,来不及了,快上车。
这是一个CUDA程序,请保存文件名为“文件名.cu”,在你的PC或者服务器上运行。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
#define N (1024*1024)
#define M (10000)
#define THREADS_PER_BLOCK 1024
void serial_add(double *a, double *b, double *c, int n, int m)
{
for(int index=0;index>>( d_a, d_b, d_c );
cudaMemcpy( c, d_c, size, cudaMemcpyDeviceToHost );
printf( "c[%d] = %f\n",0,c[0] );
printf( "c[%d] = %f\n",N-1, c[N-1] );
free(a);
free(b);
free(c);
cudaFree( d_a );
cudaFree( d_b );
cudaFree( d_c );
end = clock();
float time2 = ((float)(end-start))/CLOCKS_PER_SEC;
printf("CUDA: %f seconds, Speedup: %f\n",time2, time1/time2);
return 0;
}
效率对比
我们通过修改count的值并且加大循环次数来观察变量的效率的差别。
运行结果:
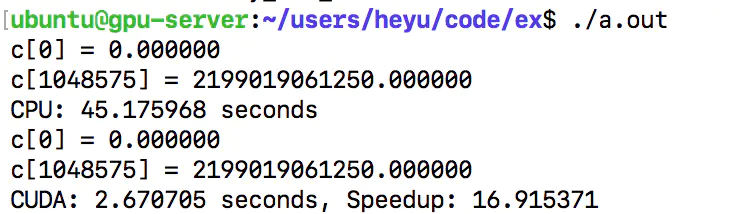
可见在数据量大的情况下效率还是相当不错的。
7. GPU or FPGA
GPU优势
1.从峰值性能来说,GPU(10Tflops)远远高于FPGA(<1TFlops);
2.GPU相对于FPGA还有一个优势就是内存接口, GPU的内存接口(传统的GDDR5,最近更是用上了HBM和HBM2)的带宽远好于FPGA的传统DDR接口(大约带宽高4-5倍);
3.功耗方面,虽然GPU的功耗远大于FPGA的功耗,但是如果要比较功耗应该比较在执行效率相同时需要的功耗。如果FPGA的架构优化能做到很好以致于一块FPGA的平均性能能够接近一块GPU,那么FPGA方案的总功耗远小于GPU,散热问题可以大大减轻。反之,如果需要二十块FPGA才能实现一块GPU的平均性能,那么FPGA在功耗方面并没有优势。
4.FPGA缺点有三点:
第一,基本单元的计算能力有限。为了实现可重构特性,FPGA 内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠LUT 查找表)都远远低于CPU 和GPU 中的ALU模块。
第二,速度和功耗相对专用定制芯片(ASIC)仍然存在不小差距。
第三,FPGA 价格较为昂贵,在规模放量的情况下单块FPGA 的成本要远高于专用定制芯片。最后谁能胜出, 完全取决于FPGA架构优化能否弥补峰值性能的劣势。
5.个人更推荐: CPU+FPGA的组合模式; 其中FPGA用于整形计算,cpu进行浮点计算和调度,此组合的拥有更高的单位功耗性能和更低的时延。最后更想GPU稳定开放,发挥其长处, 达到真正的物美价廉!
FPGA优势
人工智能目前仍处于早期阶段,未来人工智能的主战场是在推理环节,远没有爆发。未来胜负尚未可知,各家技术路线都有机会胜出。目前英伟达的GPU在训练场景中占据着绝对领导地位,但是在未来,专注于推理环节的FPGA必将会发挥巨大的价值。
FPGA和GPU内都有大量的计算单元,因此它们的计算能力都很强。在进行神经网络运算的时候,两者的速度会比CPU快很多。但是GPU由于架构固定,硬件原生支持的指令也就固定了,而FPGA则是可编程的。其可编程性是关键,因为它让软件与终端应用公司能够提供与其竞争对手不同的解决方案,并且能够灵活地针对自己所用的算法修改电路。
在平均性能方面,GPU逊于FPGA,FPGA可以根据特定的应用去编程硬件,例如如果应用里面的加法运算非常多就可以把大量的逻辑资源去实现加法器,而GPU一旦设计完就不能改动了,所以不能根据应用去调整硬件资源。
目前机器学习大多使用SIMD架构,即只需一条指令可以平行处理大量数据,因此用GPU很适合。但是有些应用是MISD,即单一数据需要用许多条指令平行处理,这种情况下用FPGA做一个MISD的架构就会比GPU有优势。 所以,对于平均性能,看的就是FPGA加速器架构上的优势是否能弥补运行速度上的劣势。如果FPGA上的架构优化可以带来相比GPU架构两到三个数量级的优势,那么FPGA在平均性能上会好于GPU。
在功耗能效比方面,同样由于FPGA的灵活性,在架构优化到很好时,一块FPGA的平均性能能够接近一块GPU,那么FPGA方案的总功耗远小于GPU,散热问题可以大大减轻。 能效比的比较也是类似,能效指的是完成程序执行消耗的能量,而能量消耗等于功耗乘以程序的执行时间。虽然GPU的功耗远大于FPGA的功耗,但是如果FPGA执行相同程序需要的时间比GPU长几十倍,那FPGA在能效比上就没有优势了;反之如果FPGA上实现的硬件架构优化得很适合特定的机器学习应用,执行算法所需的时间仅仅是GPU的几倍或甚至于接近GPU,那么FPGA的能效比就会比GPU强。
在峰值性能比方面,虽然GPU的峰值性能(10Tflops)远大于FPGA的峰值性能(<1Tflops),但针对特定的场景来讲吞吐量并不比GPU差。
8. 深度学习的三种硬件方案:ASIC,FPGA,GPU
8.1 对深度学习硬件平台的要求
要想明白“深度学习”需要怎样的硬件,必须了解深度学习的工作原理。首先在表层上,我们有一个巨大的数据集,并选定了一种深度学习模型。每个模型都有一些内部参数需要调整,以便学习数据。而这种参数调整实际上可以归结为优化问题,在调整这些参数时,就相当于在优化特定的约束条件。

-
矩阵相乘(Matrix Multiplication)——几乎所有的深度学习模型都包含这一运算,它的计算十分密集。
-
卷积(Convolution)——这是另一个常用的运算,占用了模型中大部分的每秒浮点运算(浮点/秒)。
-
循环层(Recurrent Layers )——模型中的反馈层,并且基本上是前两个运算的组合。
-
All Reduce——这是一个在优化前对学习到的参数进行传递或解析的运算序列。在跨硬件分布的深度学习网络上执行同步优化时(如AlphaGo的例子),这一操作尤其有效。
除此之外,深度学习的硬件加速器需要具备数据级别和流程化的并行性、多线程和高内存带宽等特性。 另外,由于数据的训练时间很长,所以硬件架构必须低功耗。 因此,效能功耗比(Performance per Watt)是硬件架构的评估标准之一。
CNN在应用中,一般采用GPU加速,请解释为什么GPU可以有加速效果,主要加速算法的哪一个部分?
这里默认gpu加速是指NVIDIA的CUDA加速。CPU是中央处理单元,gpu是图形处理单元,gpu由上千个流处理器(core)作为运算器。执行采用单指令多线程(SIMT)模式。相比于单核CPU(向量机)流水线式的串行操作,虽然gpu单个core计算能力很弱,但是通过大量线程进行同时计算,在数据量很大是会活动较为可观的加速效果。
具体到cnn,利用gpu加速主要是在conv(卷积)过程上。conv过程同理可以像以上的向量加法一样通过cuda实现并行化。具体的方法很多,不过最好的还是利用fft(快速傅里叶变换)进行快速卷积。NVIDIA提供了cufft库实现fft,复数乘法则可以使用cublas库里的对应的level3的cublasCgemm函数。
GPU加速的基本准则就是“人多力量大”。CNN说到底主要问题就是计算量大,但是却可以比较有效的拆分成并行问题。随便拿一个层的filter来举例子,假设某一层有n个filter,每一个需要对上一层输入过来的map进行卷积操作。那么,这个卷积操作并不需要按照线性的流程去做,每个滤波器互相之间并不影响,可以大家同时做,然后大家生成了n张新的谱之后再继续接下来的操作。既然可以并行,那么同一时间处理单元越多,理论上速度优势就会越大。所以,处理问题就变得很简单粗暴,就像NV那样,暴力增加显卡单元数(当然,显卡的架构、内部数据的传输速率、算法的优化等等也都很重要)。
GPU主要是针对图形显示及渲染等技术的出众,而其中的根本是因为处理矩阵算法能力的强大,刚好CNN中涉及大量的卷积,也就是矩阵乘法等,所以在这方面具有优势。
机器学习的算法一定得经过gpu加速吗?
不一定。只有需要大量浮点数计算,例如矩阵乘法,才需要GPU加速。 用CNN对图像进行分类就是一个需要大量浮点数计算的典型案例,通常需要GPU加速
对于ASIC、FPGA、分布式计算,这里不再展开讲,有兴趣的小伙伴可以,自行学习。不过....说不定某天博主心情好,就会梳理一下这几种硬件方案在端到端上应用的区别了。
菜鸟入门教程就到这里了,聪明的你一定不满足这个入门教程,如有兴趣进一步学习CUDA编程,可移步NVIDIA官方的课程平台CUDA ZONE(PS:中文网站,英文课程)

欢迎交流 ʕ•ᴥ•ʔ
Author:He_Yu
Email:[email protected]
原文:https://www.jianshu.com/p/34a504af8d51