全网首个OpenPrompt尝鲜报告:Prompt研究者必备实验利器

©PaperWeekly 原创 · 作者 | 李国趸
学校 | 浙江大学硕士生
研究方向 | 少样本学习

前言
THUNLP 团队前不久发布了 OpenPrompt 工具包和相关技术报告,笔者迫不及待上手尝试了一下,特意撰写此文来报告一下作为研究人员的使用感受。
本文将结合作者发布的技术报告以及个人使用感受向大家分享和介绍这个强大易用的 Prompt Learning 工具包。
主要分为四个部分:
为什么我们需要 Prompt 工具包?
OpenPrompt 是什么?
OpenPrompt 的优势:为什么我们需要 OpenPrompt?
Next Step towards PromptCenter:不仅仅是 OpenPrompt

为什么我们需要Prompt工具包?
从 LAMA 和 GPT-3 起,Prompt Learning 在近两年开始飞速发展,涌现了一大批优秀的论文,粗略总结下可以分为 few-shot learning 和 parameter-efficient learning 两种应用场景。
尽管开源社区有很多相关论文的优秀实现,但是基于以下理由,我们仍然需要一个针对初学者可以开箱即用,对于研究者可以方便修改迭代,对于工业界容易部署的 Prompt 工具包。
Prompt learning 的性能并不是很稳定,需要考虑诸多的因素,诸如 template 和 verbalizer 的设计,tunable token 和 label words 的初始化和预训练模型的选择等。
一些 Prompt 的工作仍基于传统 fine-tuning 的代码模版,用最小的更改成本来实现 Prompt learning,代码耦合程度较高,缺乏可读性和可复现性。
从上述两个因素看,作为 Prompt learning 的研究者而言,我们急需一个能够稳定实现各种经典的 Prompt learning 方法,同时对不同策略可以灵活配置,不同模块灵活组合的开源工具包。
于是,OpenPrompt 出现了。

OpenPrompt到底是什么?
回顾 Prompt learning 的几个关键流程,我们可以总结出 Prompt learning 一般可以分为以下步骤:1)选择预训练模型;2)设计 template;3)设计 verbalizer:确定答案空间;4)确定 tuning 策略。每个步骤中我们又需要考虑若干因秦,诸如设计 soft 还是 hard 或者 hybrid 的模版,soft token 怎么初始化,tuning 策略是什么等。
Open Prompt 就是这样一个覆盖 Prompt learning 全生命周期的工具包,提供了一套完整的 pipeline 以及每个 step 中灵活配置的模块。
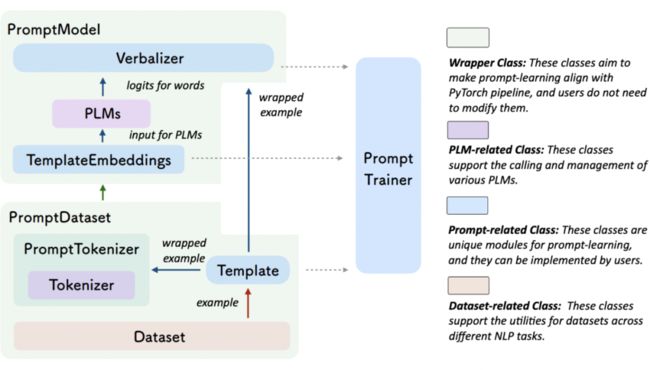
从上图不难看出,OpenPrompt 提供一套完整的 Prompt Learning Pipeline,而其中每个 class 都继承了 torch 的类或者 huggingface 的类来实现,完美兼容最流行的深度学习框架和最流行的预训练模型框架,在代码风格和 pipeline 设计上也是完美贴合 huggingface 框架,让研究者可以以最少的学习成本上手和修改。
下面,笔者通过一个 example 来讲解整个框架的运行流程。
首先是一些基本的设置:
定义 tokenizer,然后用 PromptTokenizer 包起来,PromptTokenizer 中实现了额外的一些辅助方法;
定义 template:按照需要选择 soft,或者 hard,或者 hybrid,每个都有相应的类;
定义 verbalizer:同样按照需要可以选择 soft,或者 hard 等;
定义 model:一般有两种,PromptForClassification 和 PromptForGeneration,当然里面要传入预训练模型,可以是 BERT,也可以是 T5,还要传入定义的 template 和 verbalizer。
然后就是数据的流动:raw text 被包成一个个 InputExamp|e,并送到 template中按照 template 进行“改造”,改造后的 example(被叫做 wrapped example)送到 tokenizer 中,最后组织成 dataset。dataloader 从 dataset 中取出一个个 batch 送入预训练模型中进行 tuning(可以选择是否 freeze 预训练模型)并进行优化。听起来是不是很简单?实际流程也是和传统的写法并无二致。
当然,和 huggingface 一样,作者除了上述写法,还提供了 PromptTrainer 这种封装的更好的写法,使用习惯也和 huggingface 一样,没有太大学习成本。
值得一提的是,作者也提供了一种小样本设置的 DataSampler,即从数据集中采少量样本来模拟小样本环境。

OpenPrompt的优势:为什么我们需要 Open Prompt?
刚刚知道 OpenPrompt 的时候,我对这个工具包还有些许不屑,觉得多半是现有方法的简单集成,我不禁在想,虽然我们需要 Prompt 工具包,可为什么一定要用 OpenPrompt?
仔细了解和使用了 OpenPrompt 以后,我对 OpenPrompt 的设计赞不绝口,下面分享下我的一些个人感受。
什么模块化设计,容易配置和灵活修改,适用于生成和分类任务,集成了各种 prompt 的优点我就不说了,让我觉得井常妙的一点是作者提出的: Template Language。
实际上,prompt learning 发展到现在,有各种各样的 template 和 template 组合。在做实验的时候,设计各种各样的 template 的实现成本是比较高的,很难实现快速迭代和尝试。为了解决这一痛点,作者设计一种 template language 来统一各种各样的 template 设计,然后用一个统一的函数去解析 template。

上图展示了一些具体的例子,大家可以看论文了解详情。具体来说,template language 有这些功能:
利用 Python 的 dict 的 key-value 形式表示 template,每个 dict 表示一个特殊的节点及其描述。
meta 标签表示了一些特殊的 slot,填入对应的输入,比如 {"meta":"premise"} 表示这个 slot 填入的是 premise sentence。
shortenable 标签表示了该 slot 在面临预训练模型输入长度限制时能否被截断,比如一些特殊的 token 就不能被截断,而一些输入句子是可以被截断的。
soft 标签指定当前位置是 soft token,其 value 表示用什么词进行初始化,duplicate 表示 soft token 在该位置周围重复多少次。soft id 标签则指如果两个 soft token 有相同的 soft id,则共享 word embedding。
mask 标签则表示此位需要被预测,post_ processing 标签则表示该位置的内容可以传入一个函数去后处理。
从以上笔者的介绍可以看出 template language 的强大之处!这也是我觉得该工具包最大的亮点之一。

Next Step towards PromptCenter:不仅仅是OpenPrompt
尽管 OpenPrompt 已经很强大,作者并不局限于构建这样一个集成了各种 prompt 的工具包。该工具的作者在智源社区的分享会提到了下一步的想法,这里我不再赘述,给大家分享其中一张 PPT,则可以窥见一二。

回顾 SPoT 这篇工作,把一个 unified 的 task 形式(seq2seq)和一个强大的生成模型(T5)作为基础,在 multi-task 上预训练的各个 prompt 可以在下游任务上有无限的可能。
我们有理由相信,在不远的未来,有了 Prompt Center 这一强大的工具,融合各种预训练的 prompt,应用在各种下游任务上,将进一步激发 prompt learning 的实力。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
