HBU_神经网络与深度学习 实验5 前馈神经网络:二分类任务
目录
- 写在前面的一些内容
- 一、神经元
-
- 1. 净活性值
- 2. 激活函数
-
- (1) Sigmoid 型函数
- (2) ReLU型函数
- 二、基于前馈神经网络的二分类任务
-
- 1. 数据集构建
- 2. 模型构建
-
- (1) 线性层算子
- (2) Logistic算子(激活函数)
- (3) 层的串行组合
- 3. 损失函数
- 4. 模型优化
-
- (1) 反向传播算法
- (2) 损失函数
- (3) Logistic算子
- (4) 线性层
- (5) 整个网络
- (6) 优化器
- 5. 完善Runner类:RunnerV2_1
- 6. 模型训练
- 7. 性能评价
- 三、实验Q&A
- 四、实验总结
写在前面的一些内容
- 本文为HBU_神经网络与深度学习实验(2022年秋)实验5的实验报告,此文的基本内容参照[1]Github/前馈神经网络-上.ipynb,并参考了HBU-NNDL 实验五 前馈神经网络(1)二分类任务的内容,检索时请按对应序号进行检索。
- 本实验编程语言为Python 3.10,使用Pycharm进行编程。
- 本实验报告目录标题级别顺序:一、 1. (1)
- 水平有限,难免有误,如有错漏之处敬请指正。
一、神经元
神经网络的基本组成单元为带有非线性激活函数的神经元,其结构如下图所示。神经元是对生物神经元的结构和特性的一种简化建模,接收一组输入信号并产生输出。

进行实验前,我们需要先导入torch包。
import torch
1. 净活性值
假设一个神经元接收的输入为 x ∈ R D \mathbf{x}\in \mathbb{R}^D x∈RD,其权重向量为 w ∈ R D \mathbf{w}\in \mathbb{R}^D w∈RD,神经元所获得的输入信号,即净活性值 z z z的计算方法为
z = w T x + b z =\mathbf{w}^T\mathbf{x}+b z=wTx+b其中 b b b为偏置。为了提高预测样本的效率,我们通常会将 N N N个样本归为一组进行成批地预测。
z = X w + b \boldsymbol{z} =\boldsymbol{X} \boldsymbol{w} + b z=Xw+b其中 X ∈ R N × D \boldsymbol{X}\in \mathbb{R}^{N\times D} X∈RN×D为 N N N个样本的特征矩阵, z ∈ R N \boldsymbol{z}\in \mathbb{R}^N z∈RN为 N N N个预测值组成的列向量。[1]
使用torch计算一组输入的净活性值。代码实现如下:
X = torch.rand(size=[2, 5])
# 含有5个参数的权重向量
w = torch.rand(size=[5, 1])
# 偏置项
b = torch.rand(size=[1, 1])
# 使用'torch.matmul'实现矩阵相乘
z = torch.matmul(X, w) + b
print("input X:", X)
print("weight w:", w, "\nbias b:", b)
print("output z:", z)
代码执行结果:
input X: tensor([[0.0307, 0.1197, 0.9164, 0.4694, 0.5517],
[0.2265, 0.9988, 0.1024, 0.1624, 0.3731]])
weight w: tensor([[0.2282],
[0.6387],
[0.5412],
[0.6965],
[0.8392]])
bias b: tensor([[0.8399]])
output z: tensor([[2.2092],
[2.0111]])
2. 激活函数
净活性值 z z z再经过一个非线性函数 f ( ⋅ ) f(·) f(⋅)后,得到神经元的活性值 a a a。
a = f ( z ) a = f(z) a=f(z)激活函数通常为非线性函数,可以增强神经网络的表示能力和学习能力。常用的激活函数有S型函数和ReLU函数。
(1) Sigmoid 型函数
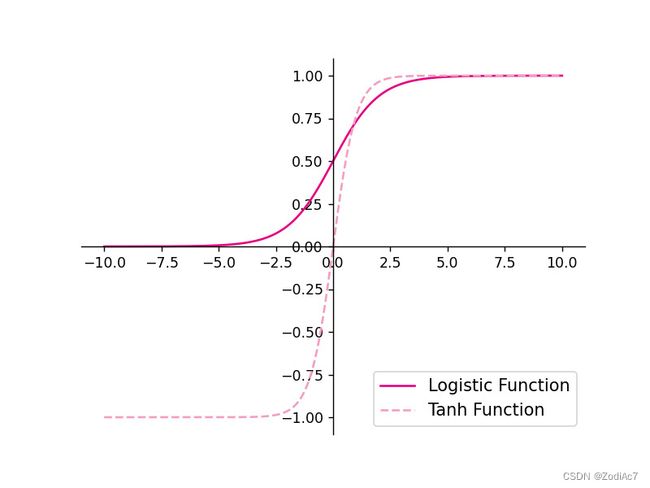
Sigmoid 型函数是指一类S型曲线函数,为两端饱和函数。常用的 Sigmoid 型函数有 Logistic 函数和 Tanh 函数,其数学表达式为
Logistic 函数:
σ ( z ) = 1 1 + exp ( − z ) \sigma(z) = \frac{1}{1+\exp(-z)} σ(z)=1+exp(−z)1Tanh 函数:
t a n h ( z ) = exp ( z ) − exp ( − z ) exp ( z ) + exp ( − z ) \mathrm{tanh}(z) = \frac{\exp(z)-\exp(-z)}{\exp(z)+\exp(-z)} tanh(z)=exp(z)+exp(−z)exp(z)−exp(−z)[1]
Logistic函数和Tanh函数的代码实现和可视化如下:
import matplotlib.pyplot as plt
# Logistic函数
def logistic(z):
return 1.0 / (1.0 + torch.exp(-z))
# Tanh函数
def tanh(z):
return (torch.exp(z) - torch.exp(-z)) / (torch.exp(z) + torch.exp(-z))
# 在[-10,10]的范围内生成10000个输入值,用于绘制函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), logistic(z).tolist(), color='#e4007f', label="Logistic Function")
plt.plot(z.tolist(), tanh(z).tolist(), color='#f19ec2', linestyle='--', label="Tanh Function")
ax = plt.gca() # 获取轴,默认有4个
# 隐藏两个轴,通过把颜色设置成none
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 调整坐标轴位置
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
plt.legend(loc='lower right', fontsize='large')
plt.savefig('fw-logistic-tanh.pdf')
plt.show()
代码执行结果如下图所示:
调用nn
plt.plot(z.tolist(), torch.sigmoid(z).tolist(), color='#e4007f', label="Logistic Function")
plt.plot(z.tolist(), torch.tanh(z).tolist(), color='#f19ec2', linestyle='--', label="Tanh Function")
实际运行结果和上图相同。
(2) ReLU型函数
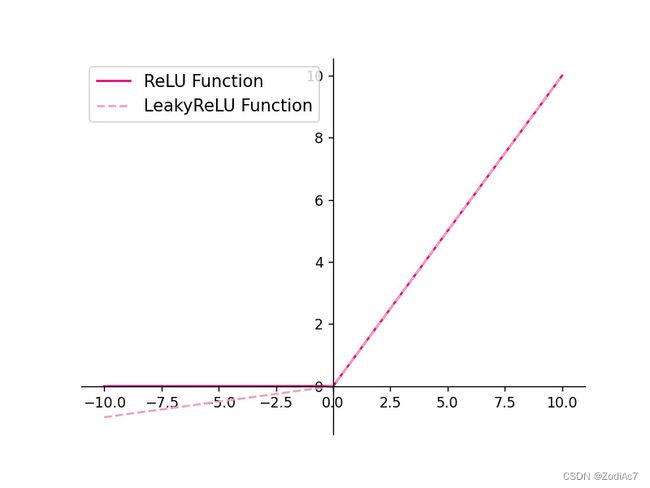
常见的ReLU函数有ReLU和带泄露的ReLU(Leaky ReLU),数学表达式分别为:
R e L U ( z ) = max ( 0 , z ) \mathrm{ReLU}(z) = \max(0,z) ReLU(z)=max(0,z) L e a k y R e L U ( z ) = max ( 0 , z ) + λ min ( 0 , z ) \mathrm{LeakyReLU}(z) = \max(0,z)+\lambda \min(0,z) LeakyReLU(z)=max(0,z)+λmin(0,z)其中 λ \lambda λ为超参数。[1]
可视化ReLU和带泄露的ReLU的函数的代码实现和可视化如下:
# ReLU
def relu(z):
return torch.maximum(z, torch.tensor(0.))
# 带泄露的ReLU
def leaky_relu(z, negative_slope=0.1):
# 当前版本torch暂不支持直接将bool类型转成int类型,因此调用了torch的tensor函数来进行显式转换
a1 = (torch.tensor((z > 0), dtype=torch.float32) * z)
a2 = (torch.tensor((z <= 0), dtype=torch.float32) * (negative_slope * z))
return a1 + a2
# 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), relu(z).tolist(), color="#e4007f", label="ReLU Function")
plt.plot(z.tolist(), leaky_relu(z).tolist(), color="#f19ec2", linestyle="--", label="LeakyReLU Function")
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
plt.legend(loc='upper left', fontsize='large')
plt.savefig('fw-relu-leakyrelu.pdf')
plt.show()
代码执行结果如下图所示:
调用nn
plt.plot(z.tolist(), torch.relu(z).tolist(), color='#e4007f', label="ReLU Function")
plt.plot(z.tolist(), torch.nn.functional.leaky_relu(z).tolist(), color='#f19ec2', linestyle ='--', label="LeakyReLU Function")
实际运行结果和上图相同。
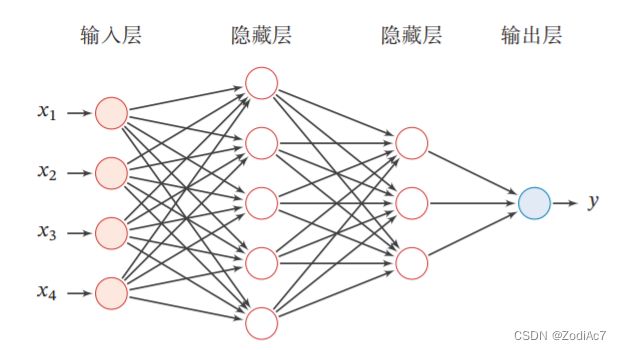
二、基于前馈神经网络的二分类任务
前馈神经网络的网络结构如下图所示。每一层获取前一层神经元的活性值,并重复上述计算得到该层的活性值,传入到下一层。整个网络中无反馈,信号从输入层向输出层逐层的单向传播,得到网络最后的输出 a ( L ) \boldsymbol{a}^{(L)} a(L)。
1. 数据集构建
此处我们使用上个实验的数据集构建中构建的二分类数据集:Moon1000数据集,其中训练集640条、验证集160条、测试集200条。
该数据集的数据是从两个带噪音的弯月形状数据分布中采样得到,每个样本包含2个特征。
# def make_moons
# 采样1000个样本
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1, 1])
y_dev = y_dev.reshape([-1, 1])
y_test = y_test.reshape([-1, 1])
代码执行结果:
outer_circ_x.shape: torch.Size([500]) outer_circ_y.shape: torch.Size([500])
inner_circ_x.shape: torch.Size([500]) inner_circ_y.shape: torch.Size([500])
after concat shape: torch.Size([1000])
X shape: torch.Size([1000, 2])
y shape: torch.Size([1000])
2. 模型构建
为了更高效的构建前馈神经网络,我们先定义每一层的算子,然后再通过算子组合构建整个前馈神经网络。
假设网络的第 l l l层的输入为第 l − 1 l-1 l−1层的神经元活性值 a ( l − 1 ) \boldsymbol{a}^{(l-1)} a(l−1),经过一个仿射变换,得到该层神经元的净活性值 z \boldsymbol{z} z,再输入到激活函数得到该层神经元的活性值 a \boldsymbol{a} a。
在实践中,为了提高模型的处理效率,通常将 N N N个样本归为一组进行成批地计算。假设网络第 l l l层的输入为 A ( l − 1 ) ∈ R N × M l − 1 \boldsymbol{A}^{(l-1)}\in \mathbb{R}^{N\times M_{l-1}} A(l−1)∈RN×Ml−1,其中每一行为一个样本,则前馈网络中第 l l l层的计算公式为
Z ( l ) = A ( l − 1 ) W ( l ) + b ( l ) ∈ R N × M l \mathbf Z^{(l)}=\mathbf A^{(l-1)} \mathbf W^{(l)} +\mathbf b^{(l)} \in \mathbb{R}^{N\times M_{l}} Z(l)=A(l−1)W(l)+b(l)∈RN×Ml A ( l ) = f l ( Z ( l ) ) ∈ R N × M l \mathbf A^{(l)}=f_l(\mathbf Z^{(l)}) \in \mathbb{R}^{N\times M_{l}} A(l)=fl(Z(l))∈RN×Ml其中 Z ( l ) \mathbf Z^{(l)} Z(l)为 N N N个样本第 l l l层神经元的净活性值, A ( l ) \mathbf A^{(l)} A(l)为 N N N个样本第 l l l层神经元的活性值, W ( l ) ∈ R M l − 1 × M l \boldsymbol{W}^{(l)}\in \mathbb{R}^{M_{l-1}\times M_{l}} W(l)∈RMl−1×Ml为第 l l l层的权重矩阵, b ( l ) ∈ R 1 × M l \boldsymbol{b}^{(l)}\in \mathbb{R}^{1\times M_{l}} b(l)∈R1×Ml为第 l l l层的偏置。[1]
为了使后续的模型搭建更加便捷,我们将神经层的计算(上述两个公式)都封装成算子,这些算子都继承Op基类。
(1) 线性层算子
上述第一个公式对应一个线性层算子,权重参数采用默认的随机初始化,偏置采用默认的零初始化。代码实现如下:
from op import Op
# 实现线性层算子
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=torch.randn, bias_init=torch.zeros):
"""
输入:
- input_size:输入数据维度
- output_size:输出数据维度
- name:算子名称
- weight_init:权重初始化方式,默认使用'torch.randn'进行标准正态分布初始化
- bias_init:偏置初始化方式,默认使用全0初始化
"""
self.params = {}
# 初始化权重
self.params['W'] = weight_init(size=[input_size, output_size])
# 初始化偏置
self.params['b'] = bias_init(size=[1, output_size])
self.inputs = None
self.name = name
def forward(self, inputs):
"""
输入:
- inputs:size=[N,input_size], N是样本数量
输出:
- outputs:预测值,size=[N,output_size]
"""
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs
(2) Logistic算子(激活函数)
本节我们采用Logistic函数来作为上述第二个中的激活函数。这里也将Logistic函数实现一个算子,代码实现如下:
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
def forward(self, inputs):
"""
输入:
- inputs: size=[N,D]
输出:
- outputs:size=[N,D]
"""
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
(3) 层的串行组合
在定义了神经层的线性层算子和激活函数算子之后,我们可以不断交叉重复使用它们来构建一个多层的神经网络。
下面我们实现一个两层的用于二分类任务的前馈神经网络,选用Logistic作为激活函数,可以利用上面实现的线性层和激活函数算子来组装。代码实现如下:
# 实现一个两层前馈神经网络
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
"""
输入:
- input_size:输入维度
- hidden_size:隐藏层神经元数量
- output_size:输出维度
"""
self.fc1 = Linear(input_size, hidden_size, name="fc1")
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
def __call__(self, X):
return self.forward(X)
def forward(self, X):
"""
输入:
- X:size=[N,input_size], N是样本数量
输出:
- a2:预测值,size=[N,output_size]
"""
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self.act_fn2(z2)
return a2
测试一下
现在,我们实例化一个两层的前馈网络,令其输入层维度为5,隐藏层维度为10,输出层维度为1;同时,随机生成一条长度为5的数据输入两层神经网络,观察输出结果。
# 实例化模型
model = Model_MLP_L2(input_size=5, hidden_size=10, output_size=1)
# 随机生成1条长度为5的数据
X = torch.rand(size=[1, 5])
result = model(X)
print("result: ", result)
代码执行结果:
result: tensor([[0.9337]])
3. 损失函数
二分类交叉熵损失函数见实验4.
4. 模型优化
神经网络的参数主要是通过梯度下降法进行优化的,因此需要计算最终损失对每个参数的梯度。
由于神经网络的层数通常比较深,其梯度计算和上一章中的线性分类模型的不同的点在于:线性模型通常比较简单可以直接计算梯度,而神经网络相当于一个复合函数,需要利用链式法则进行反向传播来计算梯度。
(1) 反向传播算法
前馈神经网络的参数梯度通常使用误差反向传播算法来计算。使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:
- 前馈计算每一层的净活性值 Z ( l ) \boldsymbol{Z}^{(l)} Z(l)和激活值 A ( l ) \boldsymbol{A}^ {(l)} A(l),直到最后一层;
- 反向传播计算每一层的误差项 δ ( l ) = ∂ R ∂ Z ( l ) \delta^{(l)}=\frac{\partial R}{\partial \boldsymbol{Z}^{(l)}} δ(l)=∂Z(l)∂R;
- 计算每一层参数的梯度,并更新参数。
在上面实现算子的基础上,来实现误差反向传播算法。在上面的三个步骤中,
- 第1步是前向计算,可以利用算子的
forward()方法来实现;- 第2步是反向计算梯度,可以利用算子的
backward()方法来实现;- 第3步中的计算参数梯度也放到
backward()中实现,更新参数放到另外的优化器中专门进行。这样,在模型训练过程中,我们首先执行模型的
forward(),再执行模型的backward(),就得到了所有参数的梯度,之后再利用优化器迭代更新参数。[1]
以本节中构建的两层全连接前馈神经网络Model_MLP_L2为例,下图给出了其前向和反向计算过程:
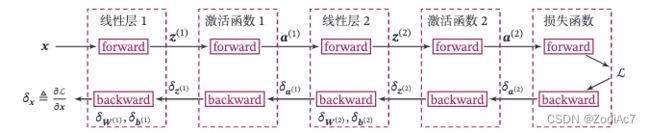
下面我们按照反向的梯度传播顺序,为每个算子添加backward()方法,并在其中实现每一层参数的梯度的计算。
(2) 损失函数
二分类交叉熵损失函数对神经网络的输出 y ^ \hat{\boldsymbol{y}} y^的偏导数为:
∂ R ∂ y ^ = − 1 N ( d i a l o g ( 1 y ^ ) y − d i a l o g ( 1 1 − y ^ ) ( 1 − y ) ) = − 1 N ( 1 y ^ ⊙ y − 1 1 − y ^ ⊙ ( 1 − y ) ) \frac{\partial R}{\partial \hat{\boldsymbol{y}}} = -\frac{1}{N}(\mathrm{dialog}(\frac{1}{\hat{\boldsymbol{y}}})\boldsymbol{y}-\mathrm{dialog}(\frac{1}{1-\hat{\boldsymbol{y}}})(1-\boldsymbol{y}))\\ = -\frac{1}{N}(\frac{1}{\hat{\boldsymbol{y}}}\odot\boldsymbol{y}-\frac{1}{1-\hat{\boldsymbol{y}}}\odot(1-\boldsymbol{y})) ∂y^∂R=−N1(dialog(y^1)y−dialog(1−y^1)(1−y))=−N1(y^1⊙y−1−y^1⊙(1−y))其中 d i a l o g ( x ) dialog(\boldsymbol{x}) dialog(x)表示以向量 x \boldsymbol{x} x为对角元素的对角阵, 1 x = 1 x 1 , . . . , 1 x N \frac{1}{\boldsymbol{x}}=\frac{1}{x_1},...,\frac{1}{x_N} x1=x11,...,xN1表示逐元素除, ⊙ \odot ⊙表示逐元素积。[1]
实现损失函数的backward(),代码实现如下:
# 实现交叉熵损失函数
class BinaryCrossEntropyLoss(Op):
def __init__(self, model):
self.predicts = None
self.labels = None
self.num = None
self.model = model
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
"""
输入:
- predicts:预测值,size=[N, 1],N为样本数量
- labels:真实标签,size=[N, 1]
输出:
- 损失值:size=[1]
"""
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts))
+ torch.matmul((1 - self.labels.t()), torch.log(1 - self.predicts)))
loss = torch.squeeze(loss, dim=1)
return loss
def backward(self):
# 计算损失函数对模型预测的导数
loss_grad_predicts = -1.0 * (self.labels / self.predicts -
(1 - self.labels) / (1 - self.predicts)) / self.num
# 梯度反向传播
self.model.backward(loss_grad_predicts)
(3) Logistic算子
在本节中,我们使用Logistic激活函数,所以这里为Logistic算子增加的反向函数。
Logistic算子的前向过程表示为 A = σ ( Z ) \boldsymbol{A}=\sigma(\boldsymbol{Z}) A=σ(Z),其中 σ \sigma σ为Logistic函数, Z ∈ R N × D \boldsymbol{Z} \in R^{N \times D} Z∈RN×D和 A ∈ R N × D \boldsymbol{A} \in R^{N \times D} A∈RN×D的每一行表示一个样本。
为了简便起见,我们分别用向量 a ∈ R D \boldsymbol{a} \in R^D a∈RD 和 z ∈ R D \boldsymbol{z} \in R^D z∈RD表示同一个样本在激活函数前后的表示,则 a \boldsymbol{a} a对 z \boldsymbol{z} z的偏导数为:
∂ a ∂ z = d i a g ( a ⊙ ( 1 − a ) ) ∈ R D × D \frac{\partial \boldsymbol{a}}{\partial \boldsymbol{z}}=diag(\boldsymbol{a}\odot(1-\boldsymbol{a}))\in R^{D \times D} ∂z∂a=diag(a⊙(1−a))∈RD×D按照反向传播算法,令 δ a = ∂ R ∂ a ∈ R D \delta_{\boldsymbol{a}}=\frac{\partial R}{\partial \boldsymbol{a}} \in R^D δa=∂a∂R∈RD表示最终损失 R R R对Logistic算子的单个输出 a \boldsymbol{a} a的梯度,则
δ z ≜ ∂ R ∂ z = ∂ a ∂ z δ a = d i a g ( a ⊙ ( 1 − a ) ) δ ( a ) = a ⊙ ( 1 − a ) ⊙ δ ( a ) \delta_{\boldsymbol{z}} \triangleq \frac{\partial R}{\partial \boldsymbol{z}} = \frac{\partial \boldsymbol{a}}{\partial \boldsymbol{z}}\delta_{\boldsymbol{a}}\\ = diag(\boldsymbol{a}\odot(1-\boldsymbol{a}))\delta_{\boldsymbol(a)}\\ = \boldsymbol{a}\odot(1-\boldsymbol{a})\odot\delta_{\boldsymbol(a)} δz≜∂z∂R=∂z∂aδa=diag(a⊙(1−a))δ(a)=a⊙(1−a)⊙δ(a)将上面公式利用批量数据表示的方式重写,令 δ A = ∂ R ∂ A ∈ R N × D \delta_{\boldsymbol{A}} =\frac{\partial R}{\partial \boldsymbol{A}} \in R^{N \times D} δA=∂A∂R∈RN×D表示最终损失 R R R对Logistic算子输出 A A A的梯度,损失函数对Logistic函数输入 Z \boldsymbol{Z} Z的导数为
δ Z = A ⊙ ( 1 − A ) ⊙ δ A ∈ R N × D \delta_{\boldsymbol{Z}}=\boldsymbol{A} \odot (1-\boldsymbol{A})\odot \delta_{\boldsymbol{A}} \in R^{N \times D} δZ=A⊙(1−A)⊙δA∈RN×D δ Z \delta_{\boldsymbol{Z}} δZ为Logistic算子反向传播的输出。[1]
由于Logistic函数中没有参数,这里不需要在backward()方法中计算该算子参数的梯度。
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
self.params = None
def forward(self, inputs):
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
def backward(self, grads):
# 计算Logistic激活函数对输入的导数
outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))
return torch.multiply(grads, outputs_grad_inputs)
(4) 线性层
线性层算子Linear的前向过程表示为 Y = X W + b \boldsymbol{Y}=\boldsymbol{X}\boldsymbol{W}+\boldsymbol{b} Y=XW+b,其中输入为 X ∈ R N × M \boldsymbol{X} \in R^{N \times M} X∈RN×M,输出为 Y ∈ R N × D \boldsymbol{Y} \in R^{N \times D} Y∈RN×D,参数为权重矩阵 W ∈ R M × D \boldsymbol{W} \in R^{M \times D} W∈RM×D和偏置 b ∈ R 1 × D \boldsymbol{b} \in R^{1 \times D} b∈R1×D。 X \boldsymbol{X} X和 Y \boldsymbol{Y} Y中的每一行表示一个样本。
为了简便起见,我们用向量 x ∈ R M \boldsymbol{x}\in R^M x∈RM和 y ∈ R D \boldsymbol{y}\in R^D y∈RD表示同一个样本在线性层算子中的输入和输出,则有 y = W T x + b T \boldsymbol{y}=\boldsymbol{W}^T\boldsymbol{x}+\boldsymbol{b}^T y=WTx+bT。 y \boldsymbol{y} y对输入 x \boldsymbol{x} x的偏导数为
∂ y ∂ x = W ∈ R D × M \frac{\partial \boldsymbol{y}}{\partial \boldsymbol{x}} = \boldsymbol{W}\in R^{D \times M} ∂x∂y=W∈RD×M线性层输入的梯度 按照反向传播算法,令 δ y = ∂ R ∂ y ∈ R D \delta_{\boldsymbol{y}}=\frac{\partial R}{\partial \boldsymbol{y}}\in R^D δy=∂y∂R∈RD表示最终损失 R R R对线性层算子的单个输出 y \boldsymbol{y} y的梯度,则
δ x ≜ ∂ R ∂ x = W δ y \delta_{\boldsymbol{x}} \triangleq \frac{\partial R}{\partial \boldsymbol{x}}= \boldsymbol{W} \delta_{\boldsymbol{y}} δx≜∂x∂R=Wδy将上面公式利用批量数据表示的方式重写,令 δ Y = ∂ R ∂ Y ∈ R N × D \delta_{\boldsymbol{Y}}=\frac{\partial R}{\partial \boldsymbol{Y}}\in \mathbb{R}^{N\times D} δY=∂Y∂R∈RN×D表示最终损失 R R R对线性层算子输出 Y \boldsymbol{Y} Y的梯度,公式可以重写为
δ X = δ Y W T \delta_{\boldsymbol{X}} =\delta_{\boldsymbol{Y}} \boldsymbol{W}^T δX=δYWT其中 δ X \delta_{\boldsymbol{X}} δX为线性层算子反向函数的输出。计算线性层参数的梯度 由于线性层算子中包含有可学习的参数 W \boldsymbol{W} W和 b \boldsymbol{b} b,因此
backward()除了实现梯度反传外,还需要计算算子内部的参数的梯度。
令 δ y = ∂ R ∂ y ∈ R D \delta_{\boldsymbol{y}}=\frac{\partial R}{\partial \boldsymbol{y}}\in \mathbb{R}^D δy=∂y∂R∈RD表示最终损失 R R R对线性层算子的单个输出 y \boldsymbol{y} y的梯度,则
δ W ≜ ∂ R ∂ W = x δ y T \delta_{\boldsymbol{W}} \triangleq \frac{\partial R}{\partial \boldsymbol{W}} = \boldsymbol{x}\delta_{\boldsymbol{y}}^T δW≜∂W∂R=xδyT δ b ≜ ∂ R ∂ b = δ y T \delta_{\boldsymbol{b}} \triangleq \frac{\partial R}{\partial \boldsymbol{b}} = \delta_{\boldsymbol{y}}^T δb≜∂b∂R=δyT将上面公式利用批量数据表示的方式重写,令 δ Y = ∂ R ∂ Y ∈ R N × D \delta_{\boldsymbol{Y}}=\frac{\partial R}{\partial \boldsymbol{Y}}\in \mathbb{R}^{N\times D} δY=∂Y∂R∈RN×D表示最终损失 R R R对线性层算子输出 Y \boldsymbol{Y} Y的梯度,则公式可以重写为
δ W = X T δ Y δ b = 1 T δ Y \delta_{\boldsymbol{W}} = \boldsymbol{X}^T \delta_{\boldsymbol{Y}}\\ \delta_{\boldsymbol{b}} = \mathbf{1}^T \delta_{\boldsymbol{Y}} δW=XTδYδb=1TδY[1]
具体实现代码如下:
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=torch.rand, bias_init=torch.zeros):
self.params = {}
self.params['W'] = weight_init(size=[input_size, output_size])
self.params['b'] = bias_init(size=[1, output_size])
self.inputs = None
self.grads = {}
self.name = name
def forward(self, inputs):
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs
def backward(self, grads):
"""
输入:
- grads:损失函数对当前层输出的导数
输出:
- 损失函数对当前层输入的导数
"""
self.grads['W'] = torch.matmul(self.inputs.T, grads)
self.grads['b'] = torch.sum(grads, dim=0)
# 线性层输入的梯度
return torch.matmul(grads, self.params['W'].T)
(5) 整个网络
实现完整的两层神经网络的前向和反向计算。代码实现如下:
# 实现一个两层前馈神经网络
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
# 线性层
self.fc1 = Linear(input_size, hidden_size, name="fc1")
# Logistic激活函数层
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
self.layers = [self.fc1, self.act_fn1, self.fc2, self.act_fn2]
def __call__(self, X):
return self.forward(X)
# 前向计算
def forward(self, X):
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self.act_fn2(z2)
return a2
# 反向计算
def backward(self, loss_grad_a2):
loss_grad_z2 = self.act_fn2.backward(loss_grad_a2)
loss_grad_a1 = self.fc2.backward(loss_grad_z2)
loss_grad_z1 = self.act_fn1.backward(loss_grad_a1)
loss_grad_inputs = self.fc1.backward(loss_grad_z1)
(6) 优化器
在计算好神经网络参数的梯度之后,我们将梯度下降法中参数的更新过程实现在优化器中。
与第3章中实现的梯度下降优化器SimpleBatchGD不同的是,此处的优化器需要遍历每层,对每层的参数分别做更新。
# def Optimizer
class BatchGD(Optimizer):
def __init__(self, init_lr, model):
super(BatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# 参数更新
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
for key in layer.params.keys():
layer.params[key] = layer.params[key] - self.init_lr * layer.grads[key]
5. 完善Runner类:RunnerV2_1
基于实验4 完善Runner类中实现的 RunnerV2 类主要针对比较简单的模型。而在本章中,模型由多个算子组合而成,通常比较复杂,因此本节继续完善并实现一个改进版:RunnerV2_1类,其主要加入的功能有:
- 支持自定义算子的梯度计算,在训练过程中调用
self.loss_fn.backward()从损失函数开始反向计算梯度; - 每层的模型保存和加载,将每一层的参数分别进行保存和加载。
import os
class RunnerV2_1(object):
def __init__(self, model, optimizer, metric, loss_fn, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
# 记录训练过程中的评估指标变化情况
self.train_scores = []
self.dev_scores = []
# 记录训练过程中的评价指标变化情况
self.train_loss = []
self.dev_loss = []
def train(self, train_set, dev_set, **kwargs):
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_epochs = kwargs.get("log_epochs", 100)
# 传入模型保存路径
save_dir = kwargs.get("save_dir", None)
# 记录全局最优指标
best_score = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
X, y = train_set
# 获取模型预测
logits = self.model(X)
# 计算交叉熵损失
trn_loss = self.loss_fn(logits, y) # return a tensor
self.train_loss.append(trn_loss.item())
# 计算评估指标
trn_score = self.metric(logits, y).item()
self.train_scores.append(trn_score)
self.loss_fn.backward()
# 参数更新
self.optimizer.step()
dev_score, dev_loss = self.evaluate(dev_set)
# 如果当前指标为最优指标,保存该模型
if dev_score > best_score:
print(f"[Evaluate] best accuracy performence has been updated: {best_score:.5f} --> {dev_score:.5f}")
best_score = dev_score
if save_dir:
self.save_model(save_dir)
if log_epochs and epoch % log_epochs == 0:
print(f"[Train] epoch: {epoch}/{num_epochs}, loss: {trn_loss.item()}")
def evaluate(self, data_set):
X, y = data_set
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
self.dev_loss.append(loss)
# 计算评估指标
score = self.metric(logits, y).item()
self.dev_scores.append(score)
return score, loss
def predict(self, X):
return self.model(X)
def save_model(self, save_dir):
# 对模型每层参数分别进行保存,保存文件名称与该层名称相同
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
torch.save(layer.params, os.path.join(save_dir, layer.name + ".pdparams"))
def load_model(self, model_dir):
# 获取所有层参数名称和保存路径之间的对应关系
model_file_names = os.listdir(model_dir)
name_file_dict = {}
for file_name in model_file_names:
name = file_name.replace(".pdparams", "")
name_file_dict[name] = os.path.join(model_dir, file_name)
# 加载每层参数
for layer in self.model.layers: # 遍历所有层
if isinstance(layer.params, dict):
name = layer.name
file_path = name_file_dict[name]
layer.params = torch.load(file_path)
6. 模型训练
基于RunnerV2_1,使用训练集和验证集进行模型训练,共训练2000个epoch。评价指标为第章介绍的accuracy。代码实现如下:
from metric import accuracy
torch.random.manual_seed(123)
epoch_num = 1000
model_saved_dir = "model"
# 输入层维度为2
input_size = 2
# 隐藏层维度为5
hidden_size = 5
# 输出层维度为1
output_size = 1
# 定义网络
model = Model_MLP_L2(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 损失函数
loss_fn = BinaryCrossEntropyLoss(model)
# 优化器
learning_rate = 0.2
optimizer = BatchGD(learning_rate, model)
# 评价方法
metric = accuracy
# 实例化RunnerV2_1类,并传入训练配置
runner = RunnerV2_1(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=epoch_num, log_epochs=50, save_dir=model_saved_dir)
代码执行结果:
result: tensor([[0.9337]])
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.50000
[Train] epoch: 0/1000, loss: 0.7818825840950012
[Evaluate] best accuracy performence has been updated: 0.50000 --> 0.50625
[Evaluate] best accuracy performence has been updated: 0.50625 --> 0.51250
[Evaluate] best accuracy performence has been updated: 0.51250 --> 0.53750
[Evaluate] best accuracy performence has been updated: 0.53750 --> 0.55625
[Evaluate] best accuracy performence has been updated: 0.55625 --> 0.56250
[Evaluate] best accuracy performence has been updated: 0.56250 --> 0.58125
[Evaluate] best accuracy performence has been updated: 0.58125 --> 0.59375
[Evaluate] best accuracy performence has been updated: 0.59375 --> 0.60625
[Evaluate] best accuracy performence has been updated: 0.60625 --> 0.61875
[Evaluate] best accuracy performence has been updated: 0.61875 --> 0.63750
[Evaluate] best accuracy performence has been updated: 0.63750 --> 0.64375
[Evaluate] best accuracy performence has been updated: 0.64375 --> 0.65000
[Evaluate] best accuracy performence has been updated: 0.65000 --> 0.66250
[Evaluate] best accuracy performence has been updated: 0.66250 --> 0.66875
[Evaluate] best accuracy performence has been updated: 0.66875 --> 0.67500
[Evaluate] best accuracy performence has been updated: 0.67500 --> 0.68125
[Evaluate] best accuracy performence has been updated: 0.68125 --> 0.69375
[Evaluate] best accuracy performence has been updated: 0.69375 --> 0.70000
[Train] epoch: 50/1000, loss: 0.6381711959838867
[Evaluate] best accuracy performence has been updated: 0.70000 --> 0.70625
[Evaluate] best accuracy performence has been updated: 0.70625 --> 0.71875
[Evaluate] best accuracy performence has been updated: 0.71875 --> 0.72500
[Evaluate] best accuracy performence has been updated: 0.72500 --> 0.73125
[Evaluate] best accuracy performence has been updated: 0.73125 --> 0.73750
[Train] epoch: 100/1000, loss: 0.5681211352348328
[Evaluate] best accuracy performence has been updated: 0.73750 --> 0.74375
[Evaluate] best accuracy performence has been updated: 0.74375 --> 0.75000
[Evaluate] best accuracy performence has been updated: 0.75000 --> 0.75625
[Train] epoch: 150/1000, loss: 0.4989375174045563
[Train] epoch: 200/1000, loss: 0.45416688919067383
[Train] epoch: 250/1000, loss: 0.43067389726638794
[Evaluate] best accuracy performence has been updated: 0.75625 --> 0.76250
[Train] epoch: 300/1000, loss: 0.4188295304775238
[Train] epoch: 350/1000, loss: 0.4127233028411865
[Train] epoch: 400/1000, loss: 0.4094739854335785
[Train] epoch: 450/1000, loss: 0.40769463777542114
[Train] epoch: 500/1000, loss: 0.40669116377830505
[Train] epoch: 550/1000, loss: 0.406104177236557
[Train] epoch: 600/1000, loss: 0.40574273467063904
[Train] epoch: 650/1000, loss: 0.4055047035217285
[Train] epoch: 700/1000, loss: 0.40533486008644104
[Train] epoch: 750/1000, loss: 0.40520358085632324
[Train] epoch: 800/1000, loss: 0.40509477257728577
[Train] epoch: 850/1000, loss: 0.40499982237815857
[Train] epoch: 900/1000, loss: 0.4049137234687805
[Train] epoch: 950/1000, loss: 0.4048336446285248
可视化观察训练集与验证集的损失函数变化情况。
# 打印训练集和验证集的损失
plt.figure()
plt.plot(range(epoch_num), runner.train_loss, color="#e4007f", label="Train loss")
plt.plot(range(epoch_num), runner.dev_loss, color="#f19ec2", linestyle='--', label="Dev loss")
plt.xlabel("epoch", fontsize='large')
plt.ylabel("loss", fontsize='large')
plt.legend(fontsize='x-large')
plt.savefig('fw-loss2.pdf')
plt.show()
代码执行结果如下图所示:
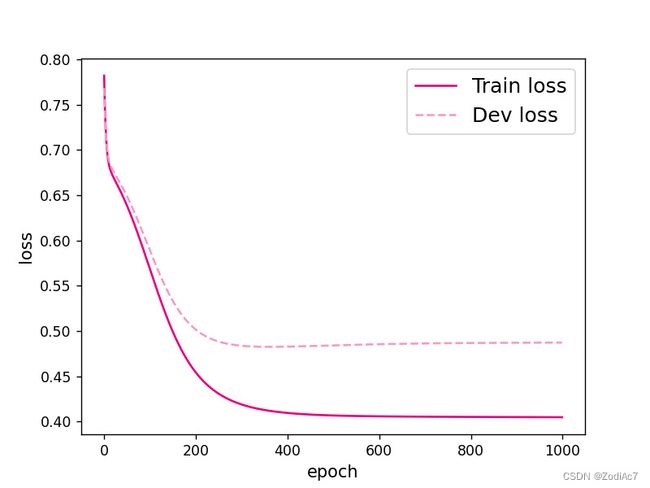
7. 性能评价
使用测试集对训练中的最优模型进行评价,观察模型的评价指标。代码实现如下:
# 加载训练好的模型
runner.load_model(model_saved_dir)
# 在测试集上对模型进行评价
score, loss = runner.evaluate([X_test, y_test])
print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))
代码执行结果:
[Test] score/loss: 0.7950/0.4844
从结果来看,模型在测试集上取得了较高的准确率。
下面对结果进行可视化:
import math
# 均匀生成40000个数据点
x1, x2 = torch.meshgrid(torch.linspace(-math.pi, math.pi, 200), torch.linspace(-math.pi, math.pi, 200))
x = torch.stack([torch.flatten(x1), torch.flatten(x2)], axis=1)
# 预测对应类别
y = runner.predict(x)
y = torch.squeeze(torch.tensor((y >= 0.5), dtype=torch.float32), axis=-1)
# 绘制类别区域
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(x[:, 0].tolist(), x[:, 1].tolist(), c=y.tolist(), cmap=plt.cm.Spectral)
plt.scatter(X_train[:, 0].tolist(), X_train[:, 1].tolist(), marker='*', c=torch.squeeze(y_train, axis=-1).tolist())
plt.scatter(X_dev[:, 0].tolist(), X_dev[:, 1].tolist(), marker='*', c=torch.squeeze(y_dev, axis=-1).tolist())
plt.scatter(X_test[:, 0].tolist(), X_test[:, 1].tolist(), marker='*', c=torch.squeeze(y_test, axis=-1).tolist())
plt.show()
代码执行结果如下图所示:
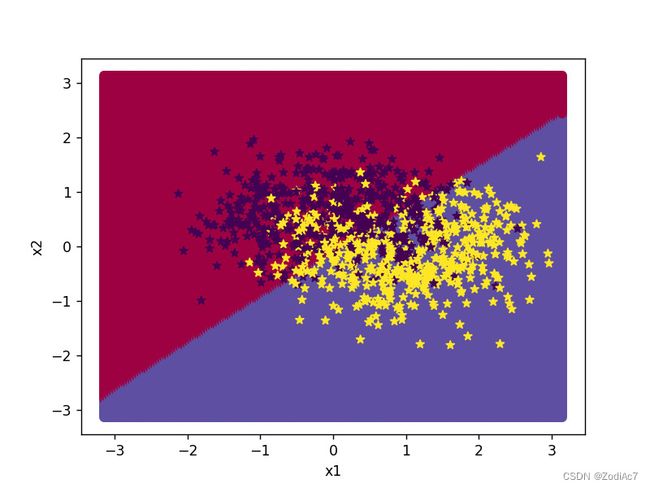
三、实验Q&A
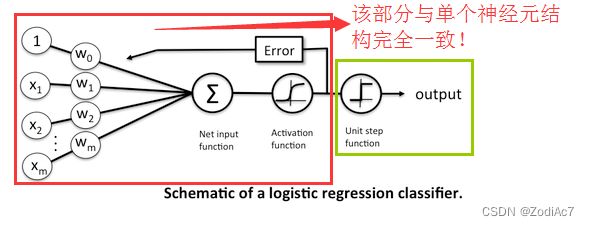
对比 3.1 基于Logistic回归的二分类任务 4.2 基于前馈神经网络的二分类任务。
Logistic回归实际上就是神经网络中的一个神经元结构。
3.1中的回归算是一种线性分类器,在前面的实验中我们验证过了当噪声很大(noise=0.5)时,线性回归不能很好的将两类数据分开。
4.2中的神经网络由于激活函数的存在,使得神经网络变成了一个非线性模型,故能够很好的完成3.1中的分类任务,即使是在噪声较大的情况下。
四、实验总结
实话说,在做思考题前,其实我还是不清楚神经网络和之前的线性分类有何区别,参考了相关内容后,大概理解了神经网络做分类任务的优势点罢(笑)
分类任务,有时真的不只是非黑即白这么简单,而且也没有那么多的分类任务能够简单粗暴的用一条直线完成。