18 - Transformer原理及其PyTorch源码讲解
文章目录
- 1. CNN
- 2. RNN
- 3. Transformer
- 4. Transformer的结构
-
- 4.1 Transformer整体结构
- 4.2 torch.nn.Transformer
- 4.3 分解
-
- 4.3.1 Encoder
- 4.3.2 Decoder
1. CNN
CNN的特性如下:
- 权值共享
- 平移不变形:卷积核大小不变
- 可并行计算:可同时对多通道进行计算 - 滑动窗口,局部关联的建模依靠堆积进行长行程建模
- 对相对位置敏感,对绝对位置不敏感
2. RNN
- 对顺序敏感
- 串行计算耗时
- 长行程建模能力弱
- 计算复杂度与序列长度呈线性关系
- 单步计算复杂度不变
- 对相对位置敏感,对绝对位置敏感
3. Transformer
- 无局部性假设:
- 可并行计算
- 对相对位置不敏感
- 无有序假设
- 需要位置编码来反应位置变化对于特征的影响
- 对绝对位置不敏感
- 任意两个字符可以建模
- 擅长长短行程建模
- 自注意机制需要序列长度的平方级别复杂度
4. Transformer的结构
4.1 Transformer整体结构
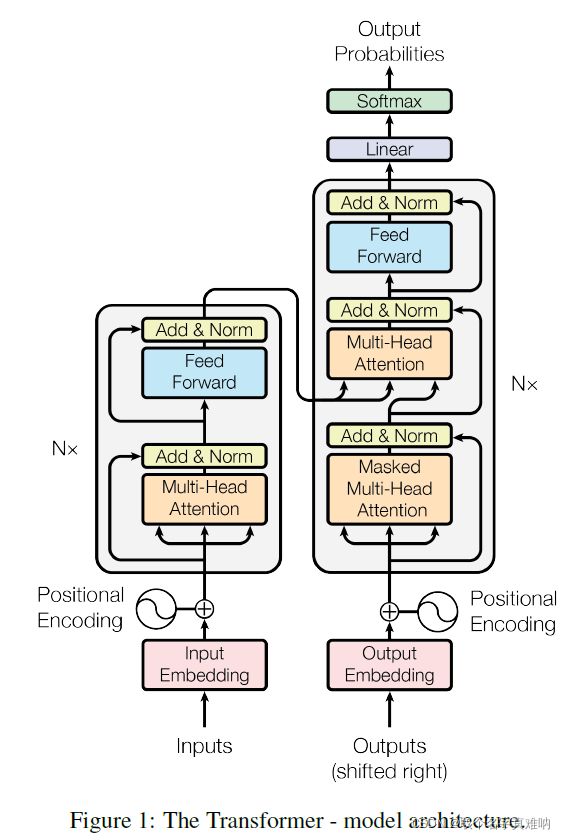
4.2 torch.nn.Transformer
pytorch 官网 transformer源代码
import copy
from typing import Optional, Any
import torch
from torch import Tensor
from .. import functional as F
from .module import Module
from .activation import MultiheadAttention
from .container import ModuleList
from ..init import xavier_uniform_
from .dropout import Dropout
from .linear import Linear
from .normalization import LayerNorm
class Transformer(Module):
r"""A transformer model. User is able to modify the attributes as needed. The architecture
is based on the paper "Attention Is All You Need". Ashish Vaswani, Noam Shazeer,
Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and
Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information
Processing Systems, pages 6000-6010. Users can build the BERT(https://arxiv.org/abs/1810.04805)
model with corresponding parameters.
Args:
d_model: the number of expected features in the encoder/decoder inputs (default=512).
nhead: the number of heads in the multiheadattention models (default=8).
num_encoder_layers: the number of sub-encoder-layers in the encoder (default=6).
num_decoder_layers: the number of sub-decoder-layers in the decoder (default=6).
dim_feedforward: the dimension of the feedforward network model (default=2048).
dropout: the dropout value (default=0.1).
activation: the activation function of encoder/decoder intermediate layer, relu or gelu (default=relu).
custom_encoder: custom encoder (default=None).
custom_decoder: custom decoder (default=None).
layer_norm_eps: the eps value in layer normalization components (default=1e-5).
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
Examples::
>>> transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12)
>>> src = torch.rand((10, 32, 512))
>>> tgt = torch.rand((20, 32, 512))
>>> out = transformer_model(src, tgt)
Note: A full example to apply nn.Transformer module for the word language model is available in
https://github.com/pytorch/examples/tree/master/word_language_model
"""
def __init__(self, d_model: int = 512, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation: str = "relu", custom_encoder: Optional[Any] = None, custom_decoder: Optional[Any] = None,
layer_norm_eps: float = 1e-5, batch_first: bool = False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(Transformer, self).__init__()
if custom_encoder is not None:
self.encoder = custom_encoder
else:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first,
**factory_kwargs)
encoder_norm = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
if custom_decoder is not None:
self.decoder = custom_decoder
else:
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first,
**factory_kwargs)
decoder_norm = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.batch_first = batch_first
def forward(self, src: Tensor, tgt: Tensor, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Take in and process masked source/target sequences.
Args:
src: the sequence to the encoder (required).
tgt: the sequence to the decoder (required).
src_mask: the additive mask for the src sequence (optional).
tgt_mask: the additive mask for the tgt sequence (optional).
memory_mask: the additive mask for the encoder output (optional).
src_key_padding_mask: the ByteTensor mask for src keys per batch (optional).
tgt_key_padding_mask: the ByteTensor mask for tgt keys per batch (optional).
memory_key_padding_mask: the ByteTensor mask for memory keys per batch (optional).
Shape:
- src: :math:`(S, N, E)`, `(N, S, E)` if batch_first.
- tgt: :math:`(T, N, E)`, `(N, T, E)` if batch_first.
- src_mask: :math:`(S, S)`.
- tgt_mask: :math:`(T, T)`.
- memory_mask: :math:`(T, S)`.
- src_key_padding_mask: :math:`(N, S)`.
- tgt_key_padding_mask: :math:`(N, T)`.
- memory_key_padding_mask: :math:`(N, S)`.
Note: [src/tgt/memory]_mask ensures that position i is allowed to attend the unmasked
positions. If a ByteTensor is provided, the non-zero positions are not allowed to attend
while the zero positions will be unchanged. If a BoolTensor is provided, positions with ``True``
are not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
is provided, it will be added to the attention weight.
[src/tgt/memory]_key_padding_mask provides specified elements in the key to be ignored by
the attention. If a ByteTensor is provided, the non-zero positions will be ignored while the zero
positions will be unchanged. If a BoolTensor is provided, the positions with the
value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
- output: :math:`(T, N, E)`, `(N, T, E)` if batch_first.
Note: Due to the multi-head attention architecture in the transformer model,
the output sequence length of a transformer is same as the input sequence
(i.e. target) length of the decode.
where S is the source sequence length, T is the target sequence length, N is the
batch size, E is the feature number
Examples:
>>> output = transformer_model(src, tgt, src_mask=src_mask, tgt_mask=tgt_mask)
"""
if not self.batch_first and src.size(1) != tgt.size(1):
raise RuntimeError("the batch number of src and tgt must be equal")
elif self.batch_first and src.size(0) != tgt.size(0):
raise RuntimeError("the batch number of src and tgt must be equal")
if src.size(2) != self.d_model or tgt.size(2) != self.d_model:
raise RuntimeError("the feature number of src and tgt must be equal to d_model")
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, sz: int) -> Tensor:
r"""Generate a square mask for the sequence. The masked positions are filled with float('-inf').
Unmasked positions are filled with float(0.0).
"""
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def _reset_parameters(self):
r"""Initiate parameters in the transformer model."""
for p in self.parameters():
if p.dim() > 1:
xavier_uniform_(p)
class TransformerEncoder(Module):
r"""TransformerEncoder is a stack of N encoder layers
Args:
encoder_layer: an instance of the TransformerEncoderLayer() class (required).
num_layers: the number of sub-encoder-layers in the encoder (required).
norm: the layer normalization component (optional).
Examples::
>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.rand(10, 32, 512)
>>> out = transformer_encoder(src)
"""
__constants__ = ['norm']
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the input through the encoder layers in turn.
Args:
src: the sequence to the encoder (required).
mask: the mask for the src sequence (optional).
src_key_padding_mask: the mask for the src keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
output = src
for mod in self.layers:
output = mod(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
class TransformerDecoder(Module):
r"""TransformerDecoder is a stack of N decoder layers
Args:
decoder_layer: an instance of the TransformerDecoderLayer() class (required).
num_layers: the number of sub-decoder-layers in the decoder (required).
norm: the layer normalization component (optional).
Examples::
>>> decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
>>> transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = transformer_decoder(tgt, memory)
"""
__constants__ = ['norm']
def __init__(self, decoder_layer, num_layers, norm=None):
super(TransformerDecoder, self).__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the inputs (and mask) through the decoder layer in turn.
Args:
tgt: the sequence to the decoder (required).
memory: the sequence from the last layer of the encoder (required).
tgt_mask: the mask for the tgt sequence (optional).
memory_mask: the mask for the memory sequence (optional).
tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
memory_key_padding_mask: the mask for the memory keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
output = tgt
for mod in self.layers:
output = mod(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
class TransformerEncoderLayer(Module):
r"""TransformerEncoderLayer is made up of self-attn and feedforward network.
This standard encoder layer is based on the paper "Attention Is All You Need".
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in
Neural Information Processing Systems, pages 6000-6010. Users may modify or implement
in a different way during application.
Args:
d_model: the number of expected features in the input (required).
nhead: the number of heads in the multiheadattention models (required).
dim_feedforward: the dimension of the feedforward network model (default=2048).
dropout: the dropout value (default=0.1).
activation: the activation function of intermediate layer, relu or gelu (default=relu).
layer_norm_eps: the eps value in layer normalization components (default=1e-5).
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False``.
Examples::
>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
>>> src = torch.rand(10, 32, 512)
>>> out = encoder_layer(src)
Alternatively, when ``batch_first`` is ``True``:
>>> encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8, batch_first=True)
>>> src = torch.rand(32, 10, 512)
>>> out = encoder_layer(src)
"""
__constants__ = ['batch_first']
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu",
layer_norm_eps=1e-5, batch_first=False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.activation = _get_activation_fn(activation)
def __setstate__(self, state):
if 'activation' not in state:
state['activation'] = F.relu
super(TransformerEncoderLayer, self).__setstate__(state)
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the input through the encoder layer.
Args:
src: the sequence to the encoder layer (required).
src_mask: the mask for the src sequence (optional).
src_key_padding_mask: the mask for the src keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
class TransformerDecoderLayer(Module):
r"""TransformerDecoderLayer is made up of self-attn, multi-head-attn and feedforward network.
This standard decoder layer is based on the paper "Attention Is All You Need".
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in
Neural Information Processing Systems, pages 6000-6010. Users may modify or implement
in a different way during application.
Args:
d_model: the number of expected features in the input (required).
nhead: the number of heads in the multiheadattention models (required).
dim_feedforward: the dimension of the feedforward network model (default=2048).
dropout: the dropout value (default=0.1).
activation: the activation function of intermediate layer, relu or gelu (default=relu).
layer_norm_eps: the eps value in layer normalization components (default=1e-5).
batch_first: If ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False``.
Examples::
>>> decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = decoder_layer(tgt, memory)
Alternatively, when ``batch_first`` is ``True``:
>>> decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8, batch_first=True)
>>> memory = torch.rand(32, 10, 512)
>>> tgt = torch.rand(32, 20, 512)
>>> out = decoder_layer(tgt, memory)
"""
__constants__ = ['batch_first']
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu",
layer_norm_eps=1e-5, batch_first=False, device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm3 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.dropout3 = Dropout(dropout)
self.activation = _get_activation_fn(activation)
def __setstate__(self, state):
if 'activation' not in state:
state['activation'] = F.relu
super(TransformerDecoderLayer, self).__setstate__(state)
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r"""Pass the inputs (and mask) through the decoder layer.
Args:
tgt: the sequence to the decoder layer (required).
memory: the sequence from the last layer of the encoder (required).
tgt_mask: the mask for the tgt sequence (optional).
memory_mask: the mask for the memory sequence (optional).
tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
memory_key_padding_mask: the mask for the memory keys per batch (optional).
Shape:
see the docs in Transformer class.
"""
tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def _get_clones(module, N):
return ModuleList([copy.deepcopy(module) for i in range(N)])
def _get_activation_fn(activation):
if activation == "relu":
return F.relu
elif activation == "gelu":
return F.gelu
raise RuntimeError("activation should be relu/gelu, not {}".format(activation))
4.3 分解
4.3.1 Encoder
Input_word_Embedding:
由稀疏的one-hot进入一个不带bias的FNN得到一个稠密的连续向量position_encoding:- 通过sin/cos来固定表征
- 每个位置确定性
- 对于不同的句子,相同的位置的距离一致
- 可以推广到更长的测试句子 - pe(pos+k)可以携程pe(pos)的线性组合
- 通过残差连接来使得位置信息流入深层
- 通过sin/cos来固定表征
MultiHead_Attention:- 使得建模能力更强,表征空间更丰富
- 由多组Q,K,V构成,每组单独计算一个attention向量
- 把每组的attention向量拼起来,并进入一个不带bias的FFN得到最终的向量
Feed_Forward_Network:- 只考虑每个单独位置进行建模
- 不同位置参数共享
- 类似于1x1的卷积网络和pointwise-convolution
4.3.2 Decoder
output_word_EnbeddingMasked_Multi_Head_AttentionMulti_Head_Cross_AttentionFeed_Forward_Networksoftmaxt