Transformer pytorch 代码解读(4)Decoder Layer层
目录
0.总览DecoderLayer层
1.第一个Masked Multi-Head Attention
2.第二个Multi-Head Attention
第三次的PoswiseFeedForwardNet
0.总览DecoderLayer层
进入decoder层的输入是
1.dec_inputs = decoder_outputs里面的经过词编码和位置编码的输出,是(2,6,512)维度的数据,
2.enc_outputs是(2,5,512)的数据,其他两个是:
3.dec_self_attn_mask:是消除了后续影响的矩阵,维度是(2,6,6)
4.dec_enc_attn_mask:是两个inputs做的矩阵,维度是(2,6,5)
一共三个部分,每个部分的对应如下图所示: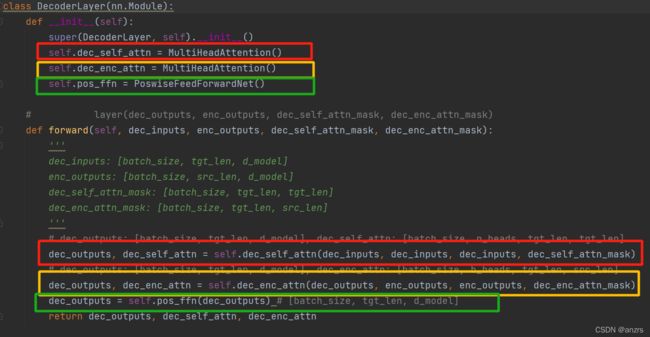

1.第一个Masked Multi-Head Attention
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask),传入的三个参数,前三个是decoder中经过词编码和位置编码的输入,也就是(2,6,512)的维度的数据。而dec_self_attn_mask是经过处理为了防止该位置之后的词对这个词产生影响的矩阵,维度是(2,6,6)。如下图所示:

(1)获得Q,K,V矩阵,以及将attn进行展开,这个attn是encoder的输入自己和自己做的矩阵。
第一步获得了,torch.Size([2, 6, 512]) -> torch.Size([2, 8, 6, 64]),获得了三个维度都是
(2,8,6,64)的Q,K,V。
第二步,将attn_mask进行展开,获得了一个(2,8,6,6)的attn_mask。
(2)做内积获得context,如下绿色部分
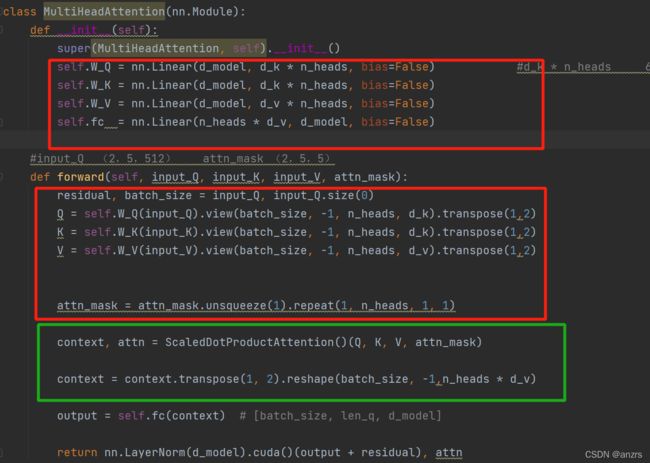
(1)ScaledDotProductAttention

传入的是Q,K,V,维度都是(2,8,6,64),attn_mask的维度是(2,8,6,6)。
(1)scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k), 经过这一步是,(2,8,6,64)* (2,8,64,6)->(2,8,6,6)
(2)scores.masked_fill_(attn_mask, -1e9) 经过这一步是,将这个(2,8,6,6)的矩阵的该置负无穷的地方都置了。
(3)attn = nn.Softmax(dim=-1)(scores) context = torch.matmul(attn, V) 在这一步之后,获得了一个(2,8,6,6)*(2,8,6,64)=(2,8,6,64)的context。返回了一个经过了softmax的attn(2,8,6,6)以及一个context(2,8,6,64)
(2)维度变换
(2,8,6,64)->(2,6,8,64)->(2,6,512)最终输出的是一个output(2,6,512)
2.第二个Multi-Head Attention
enc_outputs是(2,5,512)
dec_outputs是(2,6,512)
dec_enc_attn_mask是(2,6,5)

第二次的MultiHeadAttention
dec_outputs是(2,6,512)是Q,enc_outputs是(2,5,512)是K和V,
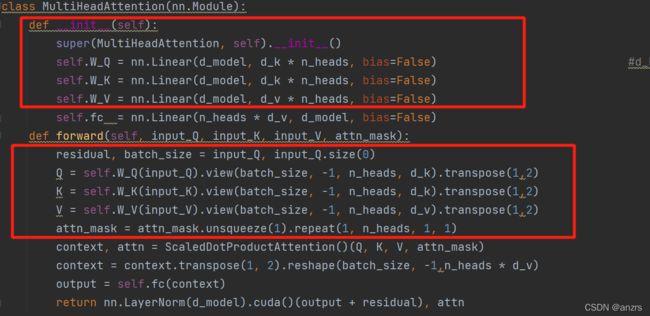
一直到红色的部分,只是获得了Q(2,8,6,64),K和V分别是(2,8,5,64)。
attn_mask的维度是(2,8,6,5)。
接下来又到了绿色的部分,也就是获得内积的部分。

传入的Q是(2,8,6,64),而K和V分别是(2,8,5,64)。

(1)scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)这一步的维度变化是(2,8,6,64)*(2,8,64,5)=(2,8,6,5)和mask_attn的维度正好是一样的。
(2)scores.masked_fill_(attn_mask, -1e9) attn = nn.Softmax(dim=-1)(scores) 同样经过处理,获得一个attn
(3)context = torch.matmul(attn, V),(2,8,6,5)*(2,8,5,64)=(2,8,6,64)
然后又经过了transpose,和reshape维度(2,8,6,64)-》(2,6,8,64)-》(2,6,512)再经过全连接层返回的就是一个(2,6,512)的结果。
第三次的PoswiseFeedForwardNet
经过激活函数以及Linear层,最终的输出的维度还是(2,6,512)
