对传统机器学习和深度学习的一些思考
文章目录
- 0.写在前面
- 1. 机器学习是什么?
- 2. 从机器学习到深度学习
-
- 2.1 机器学习的发展历史
- 2.2 到底机器学习和深度学习的关系是什么?
- 3. 传统的机器学习算法没落了么?还有必要学么?
- 4. 总结
0.写在前面
在机器学习与深度学习领域学习了一年之后,想写一篇关于自己对ML和DL的理解,因为学了这么多算法,需要跳出来看看到底在学啥?
1. 机器学习是什么?
Think the following Conversation:
朋友:你的专业方向是什么啊,小伙子?
我:机器学习!
朋友:哦,那是干啥的?
我:简单来说就是用数据去解决实际问题的
wait wait,如果行内人问你:你怎么理解机器学习
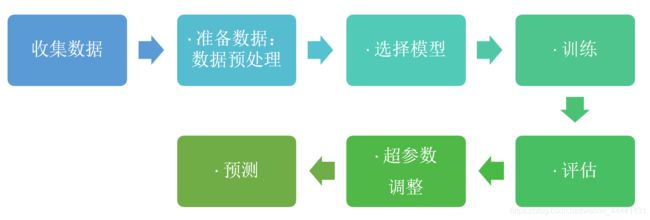
我:上图(其实就是围绕“用数据解决问题稍微展开一下”)

接着上面的对话
业内人员:你觉得机器学习应该包含哪些过程?
我:上图,对每一个步骤都可以展开聊一聊
2. 从机器学习到深度学习
2.1 机器学习的发展历史
机器学习并不是人工智能一开始就采用的方法。人工智能的发展经历了逻辑推理,知识工程,机器学习三个阶段。
1)第一阶段的重点是逻辑推理(1950s),例如数学定理的证明。这类方法采用符号逻辑来模拟人的智能
2)第二阶段的代表是专家系统(1970s),这类方法为各个领域的问题建立专家知识库,利用这些知识来完成推理和决策。如果要让人工智能做疾病诊断,那就要把医生的诊断知识建成一个库,然后用这些知识对病人进行判断,很显然,它的成本很高。
3)第三阶段就是机器学习阶段。“授人以鱼不如授人以渔“,专家系统需要人工制订一些规则,数据在根据这些规则去做出预测,有点类似if....then决策树的意思。与其请那些专家,不如让模型自己去学习这些规则,这就是机器学习:数据-->模型-->训练(学习这些数据中的规则或者规律)-->评估-->预测
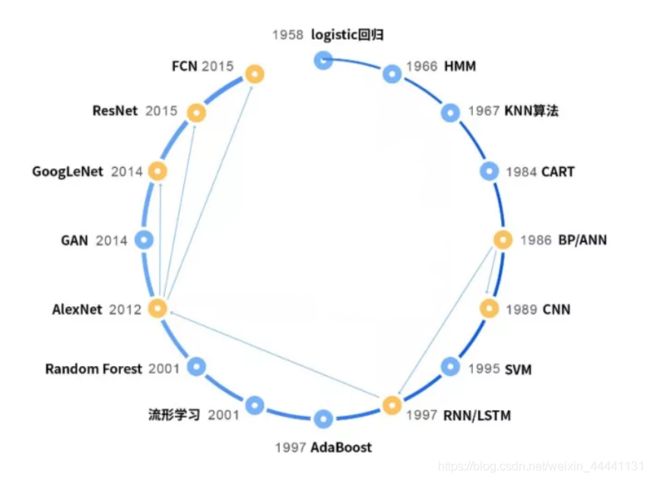
在机器学习时代(上面的第三阶段),它的发展又可以分为三个阶段。
1)1980年代正式登上历史舞台,不具备影响力,不温不火,主要原因是受限与当时的环境,典型的代表是:
1984:分类与回归树(CART)
1986:反向传播算法
1989:卷积神经网络
2)1990~2012年,走向成熟和应用。随着计算机技术的快速发展,机器学习迎来了它的春天,在此期间诞生了众多的理论和算法,并真正走向了应用工业界,实现了算法落地。典型代表算法有:
1995:支持向量机(SVM)
1997:AdaBoost算法
1997:循环神经网络(RNN)和LSTM
2000:流形学习
2001:随机森林
3)2012年~至今为深度学习时期,神经网络卷土重来。在与SVM的竞争中,神经网络长时间内处于下风,直到2012年局面才被改变,原因是计算机处理数据的能力越来越好。SVM、AdaBoost等所谓的浅层模型并不能很好的解决图像识别,语音识别等复杂的问题,在这些问题上存在严重的过拟合(过拟合的表现是在训练样本集上表现很好,在真正使用时表现很差。就像一个很机械的学生,考试时遇到自己学过的题目都会做,但对新的题目无法举一反三)。为此我们需要更强大的算法,历史又一次选择了神经网络。深度学习技术诞生并急速发展,较好的解决了现阶段AI的一些重点问题,并带来了产业界的快速发展。
深度学习的起源可以追溯到2006年的一篇文章《 Reducing the Dimensionality of Data with Neural Networks》,Hinton等人提出了一种训练深层神经网络的方法,用受限玻尔兹曼机训练多层神经网络的每一层,得到初始权重,然后继续训练整个神经网络。2012年Hinton小组发明的深度卷积神经网络AlexNet(《ImageNet Classification with Deep Convolutional Neural Networks》)首先在图像分类问题上取代成功,随后被用于机器视觉的各种问题上,包括通用目标检测,人脸检测,行人检测,人脸识别,图像分割,图像边缘检测等。在这些问题上,卷积神经网络取得了当前最好的性能。
在另一类称为时间序列分析的问题上,循环神经网络取得了成功。典型的代表是语音识别,自然语言处理,使用深度循环神经网络之后,语音识别的准确率显著提升,直至达到实际应用的要求。

历史选择了深度神经网络作为解决图像、声音识别、围棋等复杂AI问题的方法并非偶然,神经网络在理论上有万能逼近定理(universal approximation),文章来自《Multilayer feedforward networks are universal approximators》):
只要神经元的数量足够,激活函数满足某些数学性质,至少包含一个隐含层的前馈型神经网络可以逼近闭区间上任意连续函数到任意指定精度。即用神经网络可以模拟出任意复杂的函数。我们要识别的图像、语音数据可以看做是一个向量或者矩阵,识别算法则是这些数据到类别值的一个映射函数。
2016年3月份,震惊世界的AlphaGo以4:1的成绩战胜李世石,将深度学习技术(具体来讲是强化学习)推向高潮,让越来越多的人了解到深度学习的魅力,也让更多的人加入深度学习的研究。
下图展示了这些年的经典算法:
2.2 到底机器学习和深度学习的关系是什么?
其实可以从特征提取的角度考虑问题,机器学习对数据的特征需要一定的洞察能力,到底什么是好的特征,这是ML要思考的问题。而深度学习相当于把数据放在了黑盒子中,然后”摇一摇“,就能自动学习到有用的特征,可以说DL是一种端到端的学习(end-to-end).

3. 传统的机器学习算法没落了么?还有必要学么?
有时候学习深度学习学的陷进去了,慢慢地,觉得既然有了深度学习,那我们还学习机器学习干什么,除了工作实习面试需要。不知道你们是否有这样的疑惑?
后来跳出来想一想,学习机器学习非常必要,相当必要!
首先,考虑深度学习与机器学习的关系,深度学习是机器学习的一部分,所以说机器学习是深度学习的基石。
其次,深度学习占据统治地位的多数是在计算机视觉领域、自然语言处理领域。而且深度学习是 data driven 的,需要大量的数据,数据是其燃料,没了燃料,深度学习也巧妇难为无米之炊。如图像分类任务中,就需要大量的标注数据,因为有了 ImageNet 这样 百万量级,并带有标注 的数据,CNN 才能大显神威。
事实上,在实际的问题中,我们可能并不会有海量级别的、带有标注的数据。如你在做医学方面的一些模型,能拿到病人的信息数据少之又少。所以说在小数据集上,深度学习还取代不了诸如 非线性和线性核 SVM,贝叶斯分类器 方法。实际操作来看,SVM 只需要很小的数据就能找到数据之间分类的 超平面,得到很不错的分类结果。
所以,根据奥卡姆剃刀原理,能用 Linear regression、Logistic regression 能解决的问题,还干嘛一定要用深度学习算法呢?
所以,虽然深度学习发展如火如荼,但是其他机器学习算法并不会因此而没落。
4. 总结
-
深度学习是 data driven 的,需要大量的数据,而传统的机器学习算法通常不需要;
-
深度学习本质上可以看作一个特征学习器,在无需另构特征情况下,传统的机器学习算法已经能够胜任日常的任务;
-
如无必要,勿增实体。能够简单的模型解决的,不必要上深度学习算法,杀鸡焉用牛刀?
参考文章:
https://blog.csdn.net/yezi_1026/article/details/52760709