论文精讲 | 一种隐私保护边云协同训练
作者:王森、王鹏、姚信、崔金凯、胡钦涛、陈仁海、张弓 |单位:2012实验室理论部
论文标题
MistNet: Towards Private Neural Network Training with Local Differential Privacy
论文链接
https://github.com/TL-System/plato/blob/main/docs/papers/MistNet.pdf
代码链接
Plato: https://github.com/TL-System/plato
Sedna: https://github.com/kubeedge/sedna
01
研究背景
在边缘AI领域,联邦学习概念最先由google提出并在学界和业界得到广泛的讨论和发展。对于边缘AI,数据异构和数据隐私是两个主要的挑战,而将联邦学习应用在边缘计算中,可以协助解决这些挑战。FedAvg通过主动选择每一轮参与训练的clients,避免了通信不可靠的问题,减少了通信过程中的压力。同时client只需要上传训练的gradients,防止了用户原生数据的泄露。但FedAvg仍然具备三个主要缺点:
(1) 随着模型size的增加,传输量仍然会不断增长,成为系统性能的主要瓶颈之一。
(2) 一些深度学习研究表明, gradients仍然部分包含原生数据的信息,攻击者可以通过它反推用户的隐私数据。
(3) 边缘计算能力差异过大,一部分设备因算力不够,无法进行完整的训练过程或者会拖慢整个联邦学习的同步进度。
02
论文主要内容简介
为了解决前文中针对现有架构FedAvg提出的三个主要问题,我们提出了MistNet算法。MistNet算法将一个已完成预训练的DNN模型分割成两部分。一部分作为特征提取器放在边缘侧;一部分作为预测器放在云上。根据深度学习的训练规律, 我们发现新加入的数据往往对特征提取器部分的参数更新很少,而主要将更新预测器的参数。因此,我们可以固定住边缘侧的参数部分,并将输入的数据通过特征提取器进行处理获得到对应的表征数据。然后我们将表征数据从client发送到server,并对预测器在云端进行训练。MistNet算法针对边缘场景进行了如下优化:
(1) 减少边云网络传输通信量:将提取后的表征数据传输到云端进行表征数据聚合训练,而无须像传统联邦学习那样进行多轮的云边之间梯度的传输,减少了云边之间网络传输频次,从而减少了边云网络传输通信量。
(2) 加强隐私保护效果:通过对表征数据的量化、加噪,完成表征数据的压缩和扰动,增大通过云端表征数据反推原始数据的难度,实现对数据的加强隐私保护效果。
(3) 减少边侧计算资源需求:通过对预训练模型进行切割将模型的前几层作为表征提取器,减少在客户端的计算量。由于边侧的表征提取相当于是推理过程,因此通过这种方式可以实现仅具备推理能力的边侧硬件完成联邦学习。
实验证明MistNet算法可以较FedAvg算法减少5倍通信开销,边缘计算量较FedAvg降低10倍。训练精度优于FedAvg,目标检测类学习任务自动化训练收敛效率较FedAvg提升30%。
03
算法框架与技术要点
技术要点1:模型切割和表征迁移方案
利用深度神经网络前几层特征的可迁移性,服务器通过本领域或者相似领域现有数据训练模型,并提取前几层作为特征提取器。客户端从安全第三方或者服务器获得特征提取器,并可随机选择特征提取器和选择本地数据进行fine tune。
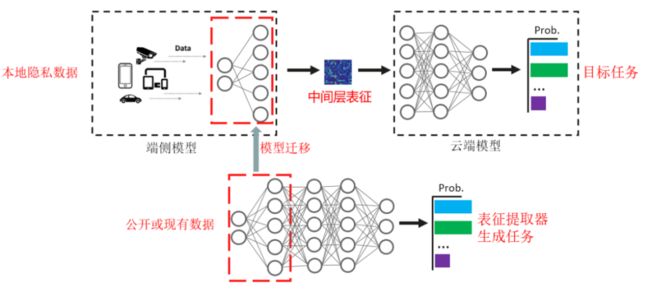
图一:表征提取技术示意图
技术要点2:表征数据的量化方案
对中间层表征进行量化压缩处理可以有效的减少通信量。这里采用的是极致量化方案:对激活函数输出进行1 bit 量化。1 bit量化丢失了大部分的表征数据内容,有效地避免了信息泄露。
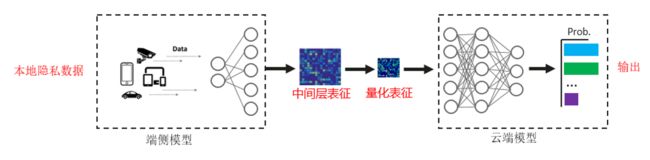
图二:通过量化技术减少表征数据的传输,并截断大部分数据信息
技术要点3:加噪量化表征隐私保护
这里提出了两个解决方案:
1. 对量化表征做符合LDP(本地差分隐私)的处理
2. 随机响应:一种对0和1二值数据实现LDP的方法
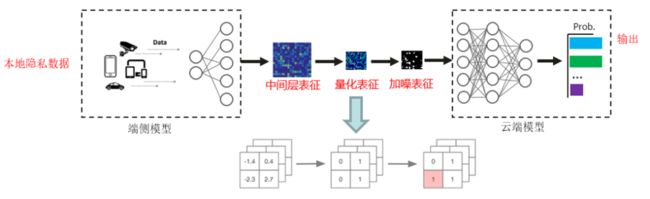
图三:通过加噪技术进一步混淆表征数据内容,使得数据难以恢复
04
实验部署与结果

图四:通过Sedna平台一键部署隐私保护边云协同训练框架
01.软硬件环境
硬件:Atlas 800 90000 + Atlas 500 3000
软件:Ubuntu 18.04.5 LTS x86_64 + Euler OS V2R8 + CANN 5.0.2 + Kubeedge 1.8.2 + Sedna 0.4.0
02. 测试结果
表1. FedAvg训练每batch耗时包括数据处理耗时且占比较大,针对Mistnet由于其数据预处理在边侧做完,中心侧训练则没有这部分操作以及耗时。
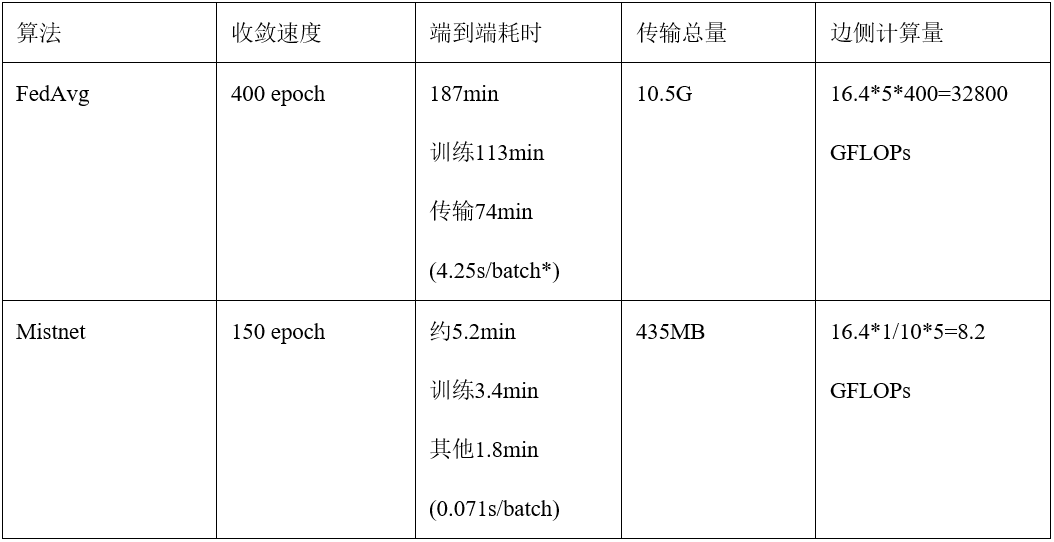
表2. GPU+Pytorch+Yolov5在MistNet框架下,在不同数据集上的mAP实验结果,其中Yolov5s代表原始的模型,Yolov-NA代表关闭数据增强的模型,Yolov5s-F代表用特征图训练的模型,Yolov5s-Q(1bit)代表增加1bit量化的模型,Yolov5s-QN( ϵ=10)代表即使用量化又添加噪声的模型,ϵ表示增加噪声的强度,ϵ越小代表添加噪声的强度越大。
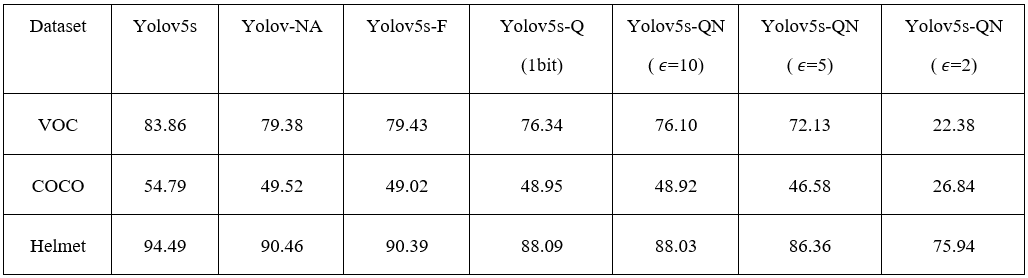

图五:输入图像与表征提取后的图像对比, 提取特征后利用隐私保护技术进行加密后传输,难以还原并识别原始图像,满足强隐私保护需求。
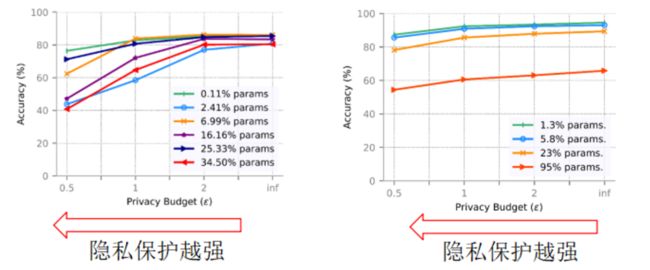
图六:我们分别对一个简单的神经网络(左图)和ResNet18(右图)在CIFAR10上进行了训练,展示了模型大小、隐私和准确率的关系。
从实验结果我们可以看出:
(1)LDP噪声越大,泄露敏感信息越少,对精度的影响越大。
(2)对于0.11%和6.99%的特征提取器在Ɛ=1是取得了较好的隐私保护和精度的平衡。
(3)复杂的模型对噪声具有更强的抵抗能力;对于1.3%和5.8%的特征提取器在Ɛ=1时取得了较好的隐私保护和精度的平衡。
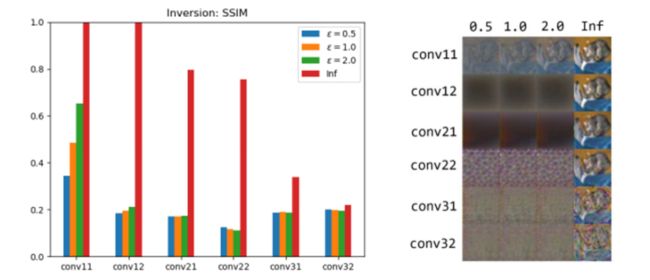
图七:针对模型反转攻击的防御效果。
我们使用白盒子Model Inversion攻击,并使用SSIM来验证效果。其中SSIM小于0.3的时候,我们认为原始图像是无法识别的。从上面的图表可以看出:通过1-bit量化和LDP的保护,对于多数特征提取器都可以有效的抵抗模型反转攻击。
05
NPU+MindSpore+Yolov5的代码实现
代码主要包括以下模块:数据加载、网络设计、数据隐私保护设计、损失函数设计与训练器。
01. 数据加载:
def _has_only_empty_bbox(anno):
return all(any(o <= 1 for o in obj["bbox"][2:]) for obj in anno)
def _count_visible_keypoints(anno):
return sum(sum(1 for v in ann["keypoints"][2::3] if v > 0) for ann in anno)
def has_valid_annotation(anno):
"""Check annotation file."""
# if it's empty, there is no annotation
if not anno:
return False
# if all boxes have close to zero area, there is no annotation
if _has_only_empty_bbox(anno):
return False
# keypoints task have a slight different criteria for considering
# if an annotation is valid
if "keypoints" not in anno[0]:
return True
# for keypoint detection tasks, only consider valid images those
# containing at least min_keypoints_per_image
if _count_visible_keypoints(anno) >= min_keypoints_per_image:
return True
return False
class COCOYoloDataset:
"""YOLOV5 Dataset for COCO."""
def __init__(self, root, ann_file, remove_images_without_annotations=True,
filter_crowd_anno=True, is_training=True):
self.coco = COCO(ann_file)
self.root = root
self.img_ids = list(sorted(self.coco.imgs.keys()))
self.filter_crowd_anno = filter_crowd_anno
self.is_training = is_training
self.mosaic = True
# filter images without any annotations
if remove_images_without_annotations:
img_ids = []
for img_id in self.img_ids:
ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=None)
anno = self.coco.loadAnns(ann_ids)
if has_valid_annotation(anno):
img_ids.append(img_id)
self.img_ids = img_ids
self.categories = {cat["id"]: cat["name"] for cat in self.coco.cats.values()}
self.cat_ids_to_continuous_ids = {
v: i for i, v in enumerate(self.coco.getCatIds())
}
self.continuous_ids_cat_ids = {
v: k for k, v in self.cat_ids_to_continuous_ids.items()
}
self.count = 0
def _mosaic_preprocess(self, index, input_size):
labels4 = []
s = 384
self.mosaic_border = [-s // 2, -s // 2]
yc, xc = [int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border]
indices = [index] + [random.randint(0, len(self.img_ids) - 1) for _ in range(3)]
for i, img_ids_index in enumerate(indices):
coco = self.coco
img_id = self.img_ids[img_ids_index]
img_path = coco.loadImgs(img_id)[0]["file_name"]
img = Image.open(os.path.join(self.root, img_path)).convert("RGB")
img = np.array(img)
h, w = img.shape[:2]
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 128, dtype=np.uint8) # base image with 4 tiles
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
padw = x1a - x1b
padh = y1a - y1b
ann_ids = coco.getAnnIds(imgIds=img_id)
target = coco.loadAnns(ann_ids)
# filter crowd annotations
if self.filter_crowd_anno:
annos = [anno for anno in target if anno["iscrowd"] == 0]
else:
annos = [anno for anno in target]
target = {}
boxes = [anno["bbox"] for anno in annos]
target["bboxes"] = boxes
classes = [anno["category_id"] for anno in annos]
classes = [self.cat_ids_to_continuous_ids[cl] for cl in classes]
target["labels"] = classes
bboxes = target['bboxes']
labels = target['labels']
out_target = []
for bbox, label in zip(bboxes, labels):
tmp = []
# convert to [x_min y_min x_max y_max]
bbox = self._convetTopDown(bbox)
tmp.extend(bbox)
tmp.append(int(label))
# tmp [x_min y_min x_max y_max, label]
out_target.append(tmp) # 这里out_target是label的实际宽高,对应于图片中的实际度量
labels = out_target.copy()
labels = np.array(labels)
out_target = np.array(out_target)
labels[:, 0] = out_target[:, 0] + padw
labels[:, 1] = out_target[:, 1] + padh
labels[:, 2] = out_target[:, 2] + padw
labels[:, 3] = out_target[:, 3] + padh
labels4.append(labels)
if labels4:
labels4 = np.concatenate(labels4, 0)
np.clip(labels4[:, :4], 0, 2 * s, out=labels4[:, :4]) # use with random_perspective
flag = np.array([1])
return img4, labels4, input_size, flag
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
(img, target) (tuple): target is a dictionary contains "bbox", "segmentation" or "keypoints",
generated by the image's annotation. img is a PIL image.
"""
coco = self.coco
img_id = self.img_ids[index]
img_path = coco.loadImgs(img_id)[0]["file_name"]
if not self.is_training:
img = Image.open(os.path.join(self.root, img_path)).convert("RGB")
return img, img_id
input_size = [640, 640]
if self.mosaic and random.random() < 0.5:
return self._mosaic_preprocess(index, input_size)
img = np.fromfile(os.path.join(self.root, img_path), dtype='int8')
ann_ids = coco.getAnnIds(imgIds=img_id)
target = coco.loadAnns(ann_ids)
# filter crowd annotations
if self.filter_crowd_anno:
annos = [anno for anno in target if anno["iscrowd"] == 0]
else:
annos = [anno for anno in target]
target = {}
boxes = [anno["bbox"] for anno in annos]
target["bboxes"] = boxes
classes = [anno["category_id"] for anno in annos]
classes = [self.cat_ids_to_continuous_ids[cl] for cl in classes]
target["labels"] = classes
bboxes = target['bboxes']
labels = target['labels']
out_target = []
for bbox, label in zip(bboxes, labels):
tmp = []
# convert to [x_min y_min x_max y_max]
bbox = self._convetTopDown(bbox)
tmp.extend(bbox)
tmp.append(int(label))
# tmp [x_min y_min x_max y_max, label]
out_target.append(tmp)
flag = np.array([0])
return img, out_target, input_size, flag
def __len__(self):
return len(self.img_ids)
def _convetTopDown(self, bbox):
x_min = bbox[0]
y_min = bbox[1]
w = bbox[2]
h = bbox[3]
return [x_min, y_min, x_min+w, y_min+h]
def create_yolo_dataset(image_dir, anno_path, batch_size, max_epoch, device_num, rank,
config=None, is_training=True, shuffle=True):
"""Create dataset for YOLOV5."""
cv2.setNumThreads(0)
de.config.set_enable_shared_mem(True)
if is_training:
filter_crowd = True
remove_empty_anno = True
else:
filter_crowd = False
remove_empty_anno = False
yolo_dataset = COCOYoloDataset(root=image_dir, ann_file=anno_path, filter_crowd_anno=filter_crowd,
remove_images_without_annotations=remove_empty_anno, is_training=is_training)
distributed_sampler = DistributedSampler(len(yolo_dataset), device_num, rank, shuffle=shuffle)
yolo_dataset.size = len(distributed_sampler)
hwc_to_chw = CV.HWC2CHW()
config.dataset_size = len(yolo_dataset)
cores = multiprocessing.cpu_count()
num_parallel_workers = int(cores / device_num)
if is_training:
multi_scale_trans = MultiScaleTrans(config, device_num)
yolo_dataset.transforms = multi_scale_trans
dataset_column_names = ["image", "annotation", "input_size", "mosaic_flag"]
output_column_names = ["image", "annotation", "bbox1", "bbox2", "bbox3",
"gt_box1", "gt_box2", "gt_box3"]
map1_out_column_names = ["image", "annotation", "size"]
map2_in_column_names = ["annotation", "size"]
map2_out_column_names = ["annotation", "bbox1", "bbox2", "bbox3",
"gt_box1", "gt_box2", "gt_box3"]
ds = de.GeneratorDataset(yolo_dataset, column_names=dataset_column_names, sampler=distributed_sampler,
python_multiprocessing=True, num_parallel_workers=min(4, num_parallel_workers))
ds = ds.map(operations=multi_scale_trans, input_columns=dataset_column_names,
output_columns=map1_out_column_names, column_order=map1_out_column_names,
num_parallel_workers=min(12, num_parallel_workers), python_multiprocessing=True)
ds = ds.map(operations=PreprocessTrueBox(config), input_columns=map2_in_column_names,
output_columns=map2_out_column_names, column_order=output_column_names,
num_parallel_workers=min(4, num_parallel_workers), python_multiprocessing=False)
mean = [m * 255 for m in [0.485, 0.456, 0.406]]
std = [s * 255 for s in [0.229, 0.224, 0.225]]
ds = ds.map([CV.Normalize(mean, std),
hwc_to_chw], num_parallel_workers=min(4, num_parallel_workers))
def concatenate(images):
images = np.concatenate((images[..., ::2, ::2], images[..., 1::2, ::2],
images[..., ::2, 1::2], images[..., 1::2, 1::2]), axis=0)
return images
ds = ds.map(operations=concatenate, input_columns="image", num_parallel_workers=min(4, num_parallel_workers))
ds = ds.batch(batch_size, num_parallel_workers=min(4, num_parallel_workers), drop_remainder=True)
else:
ds = de.GeneratorDataset(yolo_dataset, column_names=["image", "img_id"],
sampler=distributed_sampler)
compose_map_func = (lambda image, img_id: reshape_fn(image, img_id, config))
ds = ds.map(operations=compose_map_func, input_columns=["image", "img_id"],
output_columns=["image", "image_shape", "img_id"],
column_order=["image", "image_shape", "img_id"],
num_parallel_workers=8)
ds = ds.map(operations=hwc_to_chw, input_columns=["image"], num_parallel_workers=8)
ds = ds.batch(batch_size, drop_remainder=True)
ds = ds.repeat(max_epoch)
return ds, len(yolo_dataset)02. 网络设计:
BackBone:切割为两部分,其中一部分在client端,另一部分在server端
class YOLOv5Backbone_from(nn.Cell):
def __init__(self):
super(YOLOv5Backbone_from, self).__init__()
self.tenser_to_array = P.TupleToArray()
self.focusv2 = Focusv2(3, 32, k=3, s=1)
self.conv1 = Conv(32, 64, k=3, s=2)
self.C31 = C3(64, 64, n=1)
self.conv2 = Conv(64, 128, k=3, s=2)
def construct(self, x, input_shape):
"""construct method"""
#img_hight = P.Shape()(x)[2] * 2
#img_width = P.Shape()(x)[3] * 2
input_shape = F.shape(x)[2:4]
input_shape = F.cast(self.tenser_to_array(input_shape) * 2, ms.float32)
fcs = self.focusv2(x)
cv1 = self.conv1(fcs)
bcsp1 = self.C31(cv1)
cv2 = self.conv2(bcsp1)
return cv2, input_shape
class YOLOv5Backbone_to(nn.Cell):
def __init__(self):
super(YOLOv5Backbone_to, self).__init__()
self.C32 = C3(128, 128, n=3)
self.conv3 = Conv(128, 256, k=3, s=2)
self.C33 = C3(256, 256, n=3)
self.conv4 = Conv(256, 512, k=3, s=2)
self.spp = SPP(512, 512, k=[5, 9, 13])
self.C34 = C3(512, 512, n=1, shortcut=False)
def construct(self, cv2):
"""construct method"""
bcsp2 = self.C32(cv2)
cv3 = self.conv3(bcsp2)
bcsp3 = self.C33(cv3)
cv4 = self.conv4(bcsp3)
spp1 = self.spp(cv4)
bcsp4 = self.C34(spp1)
return bcsp2, bcsp3, bcsp4Server端整体网络架构:
class YOLOV5s(nn.Cell):
"""
YOLOV5 network.
Args:
is_training: Bool. Whether train or not.
Returns:
Cell, cell instance of YOLOV5 neural network.
Examples:
YOLOV5s(True)
"""
def __init__(self, is_training):
super(YOLOV5s, self).__init__()
self.config = ConfigYOLOV5()
# YOLOv5 network
self.feature_map = YOLOv5(backbone=YOLOv5Backbone_to(),
out_channel=self.config.out_channel)
# prediction on the default anchor boxes
self.detect_1 = DetectionBlock('l', is_training=is_training)
self.detect_2 = DetectionBlock('m', is_training=is_training)
self.detect_3 = DetectionBlock('s', is_training=is_training)
def construct(self, x, img_hight, img_width, input_shape):
small_object_output, medium_object_output, big_object_output = self.feature_map(x, img_hight, img_width)
output_big = self.detect_1(big_object_output, input_shape)
output_me = self.detect_2(medium_object_output, input_shape)
output_small = self.detect_3(small_object_output, input_shape)
# big is the final output which has smallest feature map
return output_big, output_me, output_small
class YOLOv5(nn.Cell):
def __init__(self, backbone, out_channel):
super(YOLOv5, self).__init__()
self.out_channel = out_channel
self.backbone = backbone
#print("self.backbone: ", self.backbone)
self.conv1 = Conv(512, 256, k=1, s=1) # 10
self.C31 = C3(512, 256, n=1, shortcut=False) # 11
self.conv2 = Conv(256, 128, k=1, s=1)
self.C32 = C3(256, 128, n=1, shortcut=False) # 13
self.conv3 = Conv(128, 128, k=3, s=2)
self.C33 = C3(256, 256, n=1, shortcut=False) # 15
self.conv4 = Conv(256, 256, k=3, s=2)
self.C34 = C3(512, 512, n=1, shortcut=False) # 17
self.backblock1 = YoloBlock(128, 255)
self.backblock2 = YoloBlock(256, 255)
self.backblock3 = YoloBlock(512, 255)
self.concat = P.Concat(axis=1)
def construct(self, x, img_hight, img_width):
"""
input_shape of x is (batch_size, 3, h, w)
feature_map1 is (batch_size, backbone_shape[2], h/8, w/8)
feature_map2 is (batch_size, backbone_shape[3], h/16, w/16)
feature_map3 is (batch_size, backbone_shape[4], h/32, w/32)
"""
#img_hight = P.Shape()(x)[2] * 2
#img_width = P.Shape()(x)[3] * 2
backbone4, backbone6, backbone9 = self.backbone(x)
cv1 = self.conv1(backbone9) # 10
ups1 = P.ResizeNearestNeighbor((img_hight / 16, img_width / 16))(cv1)
concat1 = self.concat((ups1, backbone6))
bcsp1 = self.C31(concat1) # 13
cv2 = self.conv2(bcsp1)
ups2 = P.ResizeNearestNeighbor((img_hight / 8, img_width / 8))(cv2) # 15
concat2 = self.concat((ups2, backbone4))
bcsp2 = self.C32(concat2) # 17
cv3 = self.conv3(bcsp2)
concat3 = self.concat((cv3, cv2))
bcsp3 = self.C33(concat3) # 20
cv4 = self.conv4(bcsp3)
concat4 = self.concat((cv4, cv1))
bcsp4 = self.C34(concat4) # 23
small_object_output = self.backblock1(bcsp2) # h/8, w/8
medium_object_output = self.backblock2(bcsp3) # h/16, w/16
big_object_output = self.backblock3(bcsp4) # h/32, w/32
return small_object_output, medium_object_output, big_object_output03. 数据隐私保护设计:
def encode_1b(x):
x[(x <= 0)] = 0
x[(x > 0)] = 1
return x
def randomize_1b(bit_tensor, epsilon):
"""
The default unary encoding method is symmetric.
"""
#assert isinstance(bit_tensor, tensor), 'the type of input data is not matched with the expected type(tensor)'
return symmetric_tensor_encoding_1b(bit_tensor, epsilon)
def symmetric_tensor_encoding_1b(bit_tensor, epsilon):
p = mnp.exp(epsilon / 2) / (mnp.exp(epsilon / 2) + 1)
q = 1 / (mnp.exp(epsilon / 2) + 1)
return produce_random_response_1b(bit_tensor, p, q)
def produce_random_response_1b(bit_tensor, p, q=None):
"""
Implements random response as the perturbation method.
when using torch tensor, we use Uniform Distribution to create Binomial Distribution
because torch have not binomial function
"""
q = 1 - p if q is None else q
uniformreal = mindspore.ops.UniformReal(seed=2)
binomial = uniformreal(bit_tensor.shape)
zeroslike = mindspore.ops.ZerosLike()
oneslike = mindspore.ops.OnesLike()
p_binomial = mnp.where(binomial > q, oneslike(bit_tensor), zeroslike(bit_tensor))
q_binomial = mnp.where(binomial <= q, oneslike(bit_tensor), zeroslike(bit_tensor))
return mnp.where(bit_tensor == 1, p_binomial, q_binomial) 04. 损失函数设计:
class YoloWithLossCell(nn.Cell):
"""YOLOV5 loss."""
def __init__(self, network):
super(YoloWithLossCell, self).__init__()
self.yolo_network = network
self.config = ConfigYOLOV5()
self.loss_big = YoloLossBlock('l', self.config)
self.loss_me = YoloLossBlock('m', self.config)
self.loss_small = YoloLossBlock('s', self.config)
def construct(self, x, y_true_0, y_true_1, y_true_2, gt_0, gt_1, gt_2, img_hight, img_width, input_shape):
yolo_out = self.yolo_network(x, img_hight, img_width, input_shape)
loss_l = self.loss_big(*yolo_out[0], y_true_0, gt_0, input_shape)
loss_m = self.loss_me(*yolo_out[1], y_true_1, gt_1, input_shape)
loss_s = self.loss_small(*yolo_out[2], y_true_2, gt_2, input_shape)
return loss_l + loss_m + loss_s * 0.2
class TrainingWrapper(nn.Cell):
"""Training wrapper."""
def __init__(self, network, optimizer, sens=1.0):
super(TrainingWrapper, self).__init__(auto_prefix=False)
self.network = network
self.network.set_grad()
self.weights = optimizer.parameters
self.optimizer = optimizer
self.grad = C.GradOperation(get_by_list=True, sens_param=True)
self.sens = sens
self.reducer_flag = False
self.grad_reducer = None
self.parallel_mode = context.get_auto_parallel_context("parallel_mode")
if self.parallel_mode in [ParallelMode.DATA_PARALLEL, ParallelMode.HYBRID_PARALLEL]:
self.reducer_flag = True
if self.reducer_flag:
mean = context.get_auto_parallel_context("gradients_mean")
if auto_parallel_context().get_device_num_is_set():
degree = context.get_auto_parallel_context("device_num")
else:
degree = get_group_size()
self.grad_reducer = nn.DistributedGradReducer(optimizer.parameters, mean, degree)
def construct(self, *args):
weights = self.weights
loss = self.network(*args)
sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens)
grads = self.grad(self.network, weights)(*args, sens)
if self.reducer_flag:
grads = self.grad_reducer(grads)
return F.depend(loss, self.optimizer(grads))
class Giou(nn.Cell):
"""Calculating giou"""
def __init__(self):
super(Giou, self).__init__()
self.cast = P.Cast()
self.reshape = P.Reshape()
self.min = P.Minimum()
self.max = P.Maximum()
self.concat = P.Concat(axis=1)
self.mean = P.ReduceMean()
self.div = P.RealDiv()
self.eps = 0.000001
def construct(self, box_p, box_gt):
"""construct method"""
box_p_area = (box_p[..., 2:3] - box_p[..., 0:1]) * (box_p[..., 3:4] - box_p[..., 1:2])
box_gt_area = (box_gt[..., 2:3] - box_gt[..., 0:1]) * (box_gt[..., 3:4] - box_gt[..., 1:2])
x_1 = self.max(box_p[..., 0:1], box_gt[..., 0:1])
x_2 = self.min(box_p[..., 2:3], box_gt[..., 2:3])
y_1 = self.max(box_p[..., 1:2], box_gt[..., 1:2])
y_2 = self.min(box_p[..., 3:4], box_gt[..., 3:4])
intersection = (y_2 - y_1) * (x_2 - x_1)
xc_1 = self.min(box_p[..., 0:1], box_gt[..., 0:1])
xc_2 = self.max(box_p[..., 2:3], box_gt[..., 2:3])
yc_1 = self.min(box_p[..., 1:2], box_gt[..., 1:2])
yc_2 = self.max(box_p[..., 3:4], box_gt[..., 3:4])
c_area = (xc_2 - xc_1) * (yc_2 - yc_1)
union = box_p_area + box_gt_area - intersection
union = union + self.eps
c_area = c_area + self.eps
iou = self.div(self.cast(intersection, ms.float32), self.cast(union, ms.float32))
res_mid0 = c_area - union
res_mid1 = self.div(self.cast(res_mid0, ms.float32), self.cast(c_area, ms.float32))
giou = iou - res_mid1
giou = C.clip_by_value(giou, -1.0, 1.0)
return giou
class Iou(nn.Cell):
"""Calculate the iou of boxes"""
def __init__(self):
super(Iou, self).__init__()
self.min = P.Minimum()
self.max = P.Maximum()
def construct(self, box1, box2):
"""
box1: pred_box [batch, gx, gy, anchors, 1, 4] ->4: [x_center, y_center, w, h]
box2: gt_box [batch, 1, 1, 1, maxbox, 4]
convert to topLeft and rightDown
"""
box1_xy = box1[:, :, :, :, :, :2]
box1_wh = box1[:, :, :, :, :, 2:4]
box1_mins = box1_xy - box1_wh / F.scalar_to_array(2.0) # topLeft
box1_maxs = box1_xy + box1_wh / F.scalar_to_array(2.0) # rightDown
box2_xy = box2[:, :, :, :, :, :2]
box2_wh = box2[:, :, :, :, :, 2:4]
box2_mins = box2_xy - box2_wh / F.scalar_to_array(2.0)
box2_maxs = box2_xy + box2_wh / F.scalar_to_array(2.0)
intersect_mins = self.max(box1_mins, box2_mins)
intersect_maxs = self.min(box1_maxs, box2_maxs)
intersect_wh = self.max(intersect_maxs - intersect_mins, F.scalar_to_array(0.0))
# P.squeeze: for effiecient slice
intersect_area = P.Squeeze(-1)(intersect_wh[:, :, :, :, :, 0:1]) * \
P.Squeeze(-1)(intersect_wh[:, :, :, :, :, 1:2])
box1_area = P.Squeeze(-1)(box1_wh[:, :, :, :, :, 0:1]) * P.Squeeze(-1)(box1_wh[:, :, :, :, :, 1:2])
box2_area = P.Squeeze(-1)(box2_wh[:, :, :, :, :, 0:1]) * P.Squeeze(-1)(box2_wh[:, :, :, :, :, 1:2])
iou = intersect_area / (box1_area + box2_area - intersect_area)
# iou : [batch, gx, gy, anchors, maxboxes]
return iou
class YoloLossBlock(nn.Cell):
"""
Loss block cell of YOLOV5 network.
"""
def __init__(self, scale, config=ConfigYOLOV5()):
super(YoloLossBlock, self).__init__()
self.config = config
if scale == 's':
# anchor mask
idx = (0, 1, 2)
elif scale == 'm':
idx = (3, 4, 5)
elif scale == 'l':
idx = (6, 7, 8)
else:
raise KeyError("Invalid scale value for DetectionBlock")
self.anchors = Tensor([self.config.anchor_scales[i] for i in idx], ms.float32)
self.ignore_threshold = Tensor(self.config.ignore_threshold, ms.float32)
self.concat = P.Concat(axis=-1)
self.iou = Iou()
self.reduce_max = P.ReduceMax(keep_dims=False)
self.confidence_loss = ConfidenceLoss()
self.class_loss = ClassLoss()
self.reduce_sum = P.ReduceSum()
self.giou = Giou()
def construct(self, prediction, pred_xy, pred_wh, y_true, gt_box, input_shape):
"""
prediction : origin output from yolo
pred_xy: (sigmoid(xy)+grid)/grid_size
pred_wh: (exp(wh)*anchors)/input_shape
y_true : after normalize
gt_box: [batch, maxboxes, xyhw] after normalize
"""
object_mask = y_true[:, :, :, :, 4:5]
class_probs = y_true[:, :, :, :, 5:]
true_boxes = y_true[:, :, :, :, :4]
grid_shape = P.Shape()(prediction)[1:3]
grid_shape = P.Cast()(F.tuple_to_array(grid_shape[::-1]), ms.float32)
pred_boxes = self.concat((pred_xy, pred_wh))
true_wh = y_true[:, :, :, :, 2:4]
true_wh = P.Select()(P.Equal()(true_wh, 0.0),
P.Fill()(P.DType()(true_wh),
P.Shape()(true_wh), 1.0),
true_wh)
true_wh = P.Log()(true_wh / self.anchors * input_shape)
# 2-w*h for large picture, use small scale, since small obj need more precise
box_loss_scale = 2 - y_true[:, :, :, :, 2:3] * y_true[:, :, :, :, 3:4]
gt_shape = P.Shape()(gt_box)
gt_box = P.Reshape()(gt_box, (gt_shape[0], 1, 1, 1, gt_shape[1], gt_shape[2]))
# add one more dimension for broadcast
iou = self.iou(P.ExpandDims()(pred_boxes, -2), gt_box)
# gt_box is x,y,h,w after normalize
# [batch, grid[0], grid[1], num_anchor, num_gt]
best_iou = self.reduce_max(iou, -1)
# [batch, grid[0], grid[1], num_anchor]
# ignore_mask IOU too small
ignore_mask = best_iou < self.ignore_threshold
ignore_mask = P.Cast()(ignore_mask, ms.float32)
ignore_mask = P.ExpandDims()(ignore_mask, -1)
# ignore_mask backpro will cause a lot maximunGrad and minimumGrad time consume.
# so we turn off its gradient
ignore_mask = F.stop_gradient(ignore_mask)
confidence_loss = self.confidence_loss(object_mask, prediction[:, :, :, :, 4:5], ignore_mask)
class_loss = self.class_loss(object_mask, prediction[:, :, :, :, 5:], class_probs)
object_mask_me = P.Reshape()(object_mask, (-1, 1)) # [8, 72, 72, 3, 1]
box_loss_scale_me = P.Reshape()(box_loss_scale, (-1, 1))
pred_boxes_me = xywh2x1y1x2y2(pred_boxes)
pred_boxes_me = P.Reshape()(pred_boxes_me, (-1, 4))
true_boxes_me = xywh2x1y1x2y2(true_boxes)
true_boxes_me = P.Reshape()(true_boxes_me, (-1, 4))
ciou = self.giou(pred_boxes_me, true_boxes_me)
ciou_loss = object_mask_me * box_loss_scale_me * (1 - ciou)
ciou_loss_me = self.reduce_sum(ciou_loss, ())
loss = ciou_loss_me * 4 + confidence_loss + class_loss
batch_size = P.Shape()(prediction)[0]
return loss / batch_size
05. 训练器设计:
def linear_warmup_lr(current_step, warmup_steps, base_lr, init_lr):
"""Linear learning rate."""
lr_inc = (float(base_lr) - float(init_lr)) / float(warmup_steps)
lr = float(init_lr) + lr_inc * current_step
return lr
def warmup_step_lr(lr, lr_epochs, steps_per_epoch, warmup_epochs, max_epoch, gamma=0.1):
"""Warmup step learning rate."""
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
milestones = lr_epochs
milestones_steps = []
for milestone in milestones:
milestones_step = milestone * steps_per_epoch
milestones_steps.append(milestones_step)
lr_each_step = []
lr = base_lr
milestones_steps_counter = Counter(milestones_steps)
for i in range(total_steps):
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
lr = lr * gamma**milestones_steps_counter[i]
lr_each_step.append(lr)
return np.array(lr_each_step).astype(np.float32)
def multi_step_lr(lr, milestones, steps_per_epoch, max_epoch, gamma=0.1):
return warmup_step_lr(lr, milestones, steps_per_epoch, 0, max_epoch, gamma=gamma)
def step_lr(lr, epoch_size, steps_per_epoch, max_epoch, gamma=0.1):
lr_epochs = []
for i in range(1, max_epoch):
if i % epoch_size == 0:
lr_epochs.append(i)
return multi_step_lr(lr, lr_epochs, steps_per_epoch, max_epoch, gamma=gamma)
def warmup_cosine_annealing_lr(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0):
"""Cosine annealing learning rate."""
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
lr_each_step = []
for i in range(total_steps):
last_epoch = i // steps_per_epoch
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2
lr_each_step.append(lr)
return np.array(lr_each_step).astype(np.float32)
def warmup_cosine_annealing_lr_V2(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0):
"""Cosine annealing learning rate V2."""
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
last_lr = 0
last_epoch_V1 = 0
T_max_V2 = int(max_epoch*1/3)
lr_each_step = []
for i in range(total_steps):
last_epoch = i // steps_per_epoch
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
if i < total_steps*2/3:
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2
last_lr = lr
last_epoch_V1 = last_epoch
else:
base_lr = last_lr
last_epoch = last_epoch-last_epoch_V1
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi * last_epoch / T_max_V2)) / 2
lr_each_step.append(lr)
return np.array(lr_each_step).astype(np.float32)
def warmup_cosine_annealing_lr_sample(lr, steps_per_epoch, warmup_epochs, max_epoch, T_max, eta_min=0):
"""Warmup cosine annealing learning rate."""
start_sample_epoch = 60
step_sample = 2
tobe_sampled_epoch = 60
end_sampled_epoch = start_sample_epoch + step_sample*tobe_sampled_epoch
max_sampled_epoch = max_epoch+tobe_sampled_epoch
T_max = max_sampled_epoch
base_lr = lr
warmup_init_lr = 0
total_steps = int(max_epoch * steps_per_epoch)
total_sampled_steps = int(max_sampled_epoch * steps_per_epoch)
warmup_steps = int(warmup_epochs * steps_per_epoch)
lr_each_step = []
for i in range(total_sampled_steps):
last_epoch = i // steps_per_epoch
if last_epoch in range(start_sample_epoch, end_sampled_epoch, step_sample):
continue
if i < warmup_steps:
lr = linear_warmup_lr(i + 1, warmup_steps, base_lr, warmup_init_lr)
else:
lr = eta_min + (base_lr - eta_min) * (1. + math.cos(math.pi*last_epoch / T_max)) / 2
lr_each_step.append(lr)
assert total_steps == len(lr_each_step)
return np.array(lr_each_step).astype(np.float32)
def get_lr(args):
"""generate learning rate."""
if args.lr_scheduler == 'exponential':
lr = warmup_step_lr(args.lr,
args.lr_epochs,
args.steps_per_epoch,
args.warmup_epochs,
args.max_epoch,
gamma=args.lr_gamma,
)
elif args.lr_scheduler == 'cosine_annealing':
lr = warmup_cosine_annealing_lr(args.lr, args.steps_per_epoch, args.warmup_epochs, args.max_epoch, args.T_max, args.eta_min)
elif args.lr_scheduler == 'cosine_annealing_V2':
lr = warmup_cosine_annealing_lr_V2(args.lr, args.steps_per_epoch, args.warmup_epochs, args.max_epoch, args.T_max, args.eta_min)
elif args.lr_scheduler == 'cosine_annealing_sample':
lr = warmup_cosine_annealing_lr_sample(args.lr, args.steps_per_epoch, args.warmup_epochs, args.max_epoch, args.T_max, args.eta_min)
else:
raise NotImplementedError(args.lr_scheduler)
return lr
06
总结与展望
本文提出了一种新颖的隐私保护边云协同训练方法。与以往需要边缘设备与云设备频繁通信的方法不同,MistNet只需要在训练时将中间特征从边缘上传到云端一次,显著的减少了边云网络传输通信量。本方法通过对表征数据的量化、加噪,完成表征数据的压缩和扰动,增大通过云端表征数据反推原始数据的难度,实现对数据的加强隐私保护效果。
此外,通过对预训练模型进行切割将模型的前几层作为表征提取器,减少在客户端的计算量。本文MistNet算法进一步缓解了FedAvg等联邦学习存在的缺陷。基于联邦学习的传输通信量小,隐私保护强和边侧计算量低的新算法是值得进一步的研究。