Elasticsearch技术总结笔记
目录
一、概述
1.1、介绍及特性
1.2、ES和solr的对比
二、Elasticsearch 架构与原理(重点)
2.1、ElasticSearch中的核心名词概念(重点)索引、类型、文档、映射、分片、副本是什么?
索引(index)
类型(type)——7已经废弃
文档(document)
映射(mapping)
分片(shards)
副本(repica)
三、Elasticsearch结合Kinaba安装
3.1、elasticsearch、kibana安装包下载
3.2、elasticsearch安装
3.3、elasticsearch-head可视化工具安装
3.4、安装kibana
3.5、安装IK分词器
3.6、自定义扩展热词
四、语法使用(重点)
4.1、ElasticSearch 常用字段类型
4.2、Restful Api风格操作文档语法
4.2.1、使用kibana操作文档
4.2.2、高级操作
五、SpringBoot操作Elasticsearch的Api接口(重点)
六、疑问(重点)
6.1、什么是全文索引
6.2、什么是倒排索引?怎么实现的?有什么作用?
6.3、Elasticsearch走那个节点的路由规则是怎样的?
6.4、ES写入数据的工作过程?
6.5、如何提高elasticsearch的查询性能?为什么?
6.6、Node主从节点数据是怎么同步的?
6.7、Elasticsearch集群是如何选举主节点的?
6.8、怎么查看ES的索引大小?
七、安装常见问题
7.1、Linxu安装elasticsearch启动时“elasticsearch max virtual memory areas vm.max_map_count [65530] is too low......报错”
7.2、inux安装elasticsearch一直启动失败:max file descriptors [4096] for elasticsearch process is too low, incr...
7.3、添加用户命令:
7.4、目录赋予指定用户权限:
一、概述
小故事:
多年前,一个叫做Shay Banon的程序员失业后,跟随其媳妇去伦敦学习厨师。在他找工作的过程中为妻子写了一个食谱的搜索引擎,他开始使用早期版本的Lucene。后来他认为基于Lucene开发比较困难,所以开始抽象Lucene代码以便Java程序员可以在应用中添加搜索功能。他发布了第一个开源项目,叫做”Compass”;后来他又重新写了Compass使其成为一个高性能、实施的、分布式搜索引擎, 并且可以独立部署的服务,叫做Elasticsearch。
受欢迎程度:
- 维基百科使用:类似百度百科,全文搜索、高亮、搜索推荐。
- The Guardian(国外新闻网站),类似搜索新闻:用户行为日志、数据分析、作者新闻推荐等。
- Stack Overflow(国外的程序异常讨论论坛):IT问题、全文搜索
- GitHub(开源代码管理),搜索上千亿行代码。
- 国内各大电商网站:检索商品
- 企业日志数据分析:logstash采集日志(elasticsearch+logstash+kibana)
1.1、介绍及特性
Elasticsearch(ES)是一个基于 Lucene 构建的开源 分布式搜索分析引擎,可以近实时的索引、检索数据。具备高可靠、易使用、社区活跃等特点,在全文检索、日志分析、监控分析等场景具有广泛应用。
由于高可扩展性,集群可扩展至百节点规模,处理PB级数据。通过简单的 RESTful API 即可实现写入、查询、集群管理等操作。
除了检索,还提供丰富的统计分析功能。以及官方功能扩展包 XPack 满足其他需求,如数据加密、告警、机器学习等。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr。
中文文档地址:Elasticsearch: 权威指南 | Elastic。
1.2、ES和solr的对比
首先 Lucene 是一款高性能的信息检索库,提供索引和检索基本功能。ES和Solr都是 在此基础上解决可靠性、分布式集群管理等问题最终形成产品化的全文检索系统。
Elasticsearch和Solr比较:
- 当单纯的对已有的数据进行搜索时,Solr更快。
- 当实时建立索引时,Solr会产生IO阻塞,查询性能较差,Elasticsearch具有明星的优势。
- 随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
- es基本是开箱即用,非常简单。Solr安装较为复杂。
- Solr利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能。
- Solr支持更多格式的数据,比如Json、XML、CSV,而Elasticsearch仅支持json文件格式。
- Solr在传统的搜索应用中表现好于Elasticsearch, 但在处理实时搜索应用时效率明显低于Elasticsearch。
- Solr是传统搜索应用的有力解决方案,但Elasticsearch更适用与新兴的实时搜索应用。
二、Elasticsearch 架构与原理(重点)
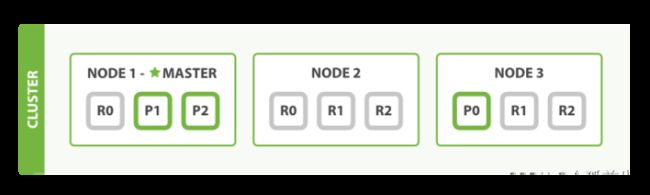
基本概念 :
- Cluster「集群」:由部署在多个机器的ES节点组成,以处理较大数据集和实现高可用;
- Node「节点」:机器上的ES进程,可配置不同类型的节点;
- Master Node「主节点」:用于集群选主。由其中一个节点担任主节点,负责集群元数据管理,如索引创建,节点离开加入集群等;
- Data Node「数据节点」:负责索引数据存储;
- Index「索引」:索引数据的逻辑集合,可类比关系型数据的DataBase;
- Shard「分片」:索引数据子集,通过将分片分配至集群不同节点,实现数据横向扩展。以解决单个节点CPU、内存、磁盘处理能力不足的情况;
- Primary Shard「主分片」:数据分片采用主从模式,由分片接收索引操作;
- Replica Shard「副本分片」:主分片的拷贝,以提高查询吞吐量和实现数据高可靠。主分片异常时,其中一个副本分片会自动提升为新的主分片。
2.1、ElasticSearch中的核心名词概念(重点)索引、类型、文档、映射、分片、副本是什么?
Elasticsearch是面向文档,json格式存储:ElasticSearch类比传统数据库
| Relational DB |
Elasticsearch |
| 数据库(Databases) |
索引(Indices) |
| 表(Tables) |
类型(Types)——7版本已经弃用 |
| 行(Rows) |
文档(Documents) |
| 字段(Columns) |
域 (Fields) |
Elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型中又包含多个文档(行),每个文档中又包含多域(列)。
-
索引(index)
一个索引就是一个文档的集合。每个索引的名字都是唯一的,通过索引名字可以来操作索引。一个集群中可以有任意多个索引。
-
类型(type)——7已经废弃
类型是索上的逻辑分类或分区。在ES6之前,一个索引可以存放多个类型,比如一个索引存放用户数据,也可存放博客数据;但从ES7开始,一个索引中只能有一个类型。新版本类型已经被废弃。
-
文档(document)
一个可以被索引的数据单元。例如一个用户的文档、一个产品的文档等。文档以json格式存储或展现。一个文档里面有多个field,每个field就是一个数据字段。
-
映射(mapping)
mapping是用来定义个文档(document),以及它所包含的属性(field)是如何存储和索引的。
-
分片(shards)
单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个分片,分布在多台服务器上存储。有了分片就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上执行,提升吞度量和性能。每个分片都是一个lunene index。创建索引时可指定分片数量。
-
副本(repica)
任何一个服务器随时可能故障或宕机。副本可以在分片故障时提供备用服务,保证数据不丢失,多个副本还可以提升搜索操作的吞度量和性能。新增副本数,分片重分配。
三、Elasticsearch结合Kinaba安装
3.1、elasticsearch、kibana安装包下载
- Elasticsearch安装包
声明:JDK >=1.8。
安装包地址:Download Elasticsearch | Elastic
解压安装包后目录启动:
-
- Window系统启动脚本:bin\elasticsearch.bat
- Linux系统启动脚本:bin/elasticsearch
- kibana安装包
下载kinaba地址:Download Kibana Free | Get Started Now | Elastic
解压安装包后目录启动:
-
- Window系统启动脚本:bin\kibana.bat
- Linux系统启动脚本:bin/kibana
- 或者直接列表页页面查询
链接地址:Past Releases of Elastic Stack Software | Elastic

3.2、elasticsearch安装
- 解压安装包:
# tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz
- 新建一个用户(elasticsearch不允许root用户操作)
- # useradd elastic
- 将opt文件夹权限赋予新建的用户
# chown -R elastic:elastic /opt
- 切到elastic用户
# su elastic
- 进入解压后的目录
# cd elasticsearch-7.2.0
# ls
![]()
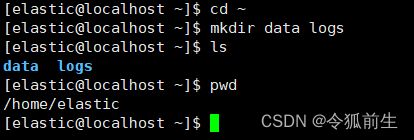
- 到自己的账号的文件加下新增数据文件夹data和日志文件加logs
# mkdir data logs
- 回到elasticsearch解压后的文件夹,进入config,编辑elasticsearch.yml(只改黄色的文字地方)

# vim elasticsearch.yml
| # ======================== Elasticsearch Configuration ========================= # # NOTE: Elasticsearch comes with reasonable defaults for most settings. # Before you set out to tweak and tune the configuration, make sure you # understand what are you trying to accomplish and the consequences. # # The primary way of configuring a node is via this file. This template lists # the most important settings you may want to configure for a production cluster. # # Please consult the documentation for further information on configuration options: # https://www.elastic.co/guide/en/elasticsearch/reference/index.html # # ---------------------------------- Cluster ----------------------------------- # # Use a descriptive name for your cluster: # 集群名称 cluster.name: my-application # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: # #node.name: node-1 # # Add custom attributes to the node: #自定义节点名称(集群时,节点名称不能一样) node.name: node-1 # # Add custom attributes to the node: # #node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): # 设置数据目录 path.data: /home/elastic/data # # Path to log files: # 设置日志目录 path.logs: /home/elastic/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # #bootstrap.memory_lock: true # # Make sure that the heap size is set to about half the memory available # on the system and that the owner of the process is allowed to use this # limit. # # Elasticsearch performs poorly when the system is swapping the memory. # # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # 设置绑定主机ip(4个0表示主机,且任何机器都可以访问本机的ip) network.host: 0.0.0.0 # # Set a custom port for HTTP: # http访问端口 http.port: 9200 # # For more information, consult the network module documentation. # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when this node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # discovery.seed_hosts: ["192.168.48.129", "192.168.48.130","192.168.48.131"] # # Bootstrap the cluster using an initial set of master-eligible nodes: # cluster.initial_master_nodes: ["node-1"] # # For more information, consult the discovery and cluster formation module documentation. # # ---------------------------------- Gateway ----------------------------------- # # Block initial recovery after a full cluster restart until N nodes are started: # #gateway.recover_after_nodes: 3 # # For more information, consult the gateway module documentation. # # ---------------------------------- Various ----------------------------------- # # Require explicit names when deleting indices: # #action.destructive_requires_name: true |
- 进入bin目录,执行启动文件elasticsearch
# cd /opt/elasticsearch-7.2.0/bin
# ./elasticsearch
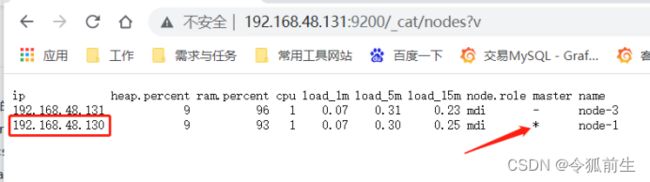
- 浏览器验证集群配置是否生效:
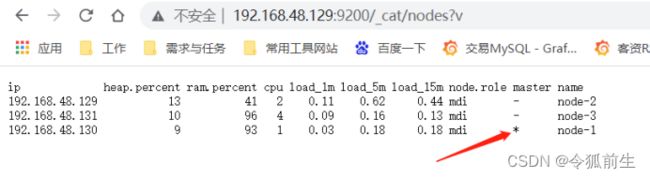
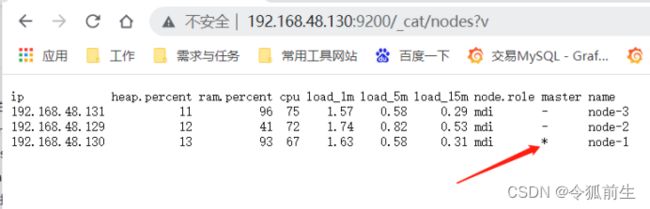
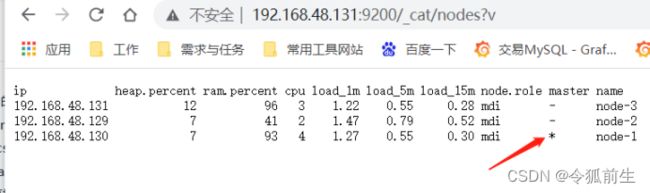
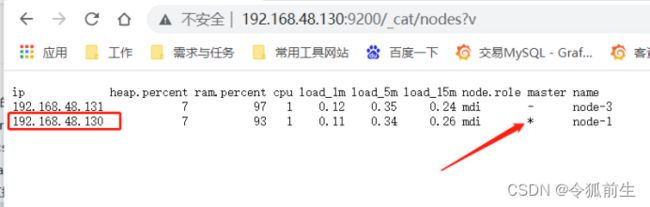
验证集群高可用:停掉机器(192.168.48.129)的elasticsearch服务,再看主节点(已经变成了130机器):
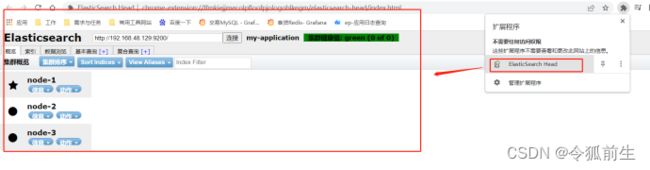
3.3、elasticsearch-head可视化工具安装
备注:elasticsearch5之后可以直接安装chrome插件使用,无需独立部署。
- 安装下载地址:es-head/elasticsearch-head.crx at master · liufengji/es-head · GitHub
- 安装chrome插件
浏览器打开一个新的窗口时,选择扩展程序的对应elasticsearch head插件启动使用。
3.4、安装kibana
- 在opt目录下解压安装包
# tar -zxvf kibana-7.2.0-linux-x86_64.tar.gz
- 进入config目录编辑kibana.yml配置
# cd /opt/kibana-7.2.0-linux-x86_64/config

# vim kibana.yml
备注:server.name指定的时部署的机器,easticsearch.hosts是链接的elasticsearch服务的http访问地址,数组形,如果集群则配置多个。

![]()
- 进入bin目录,执行kibana启动文件,启动kibana。
浏览器访问kibana, 默认访问端口5601:
http://192.168.48.129:5601/
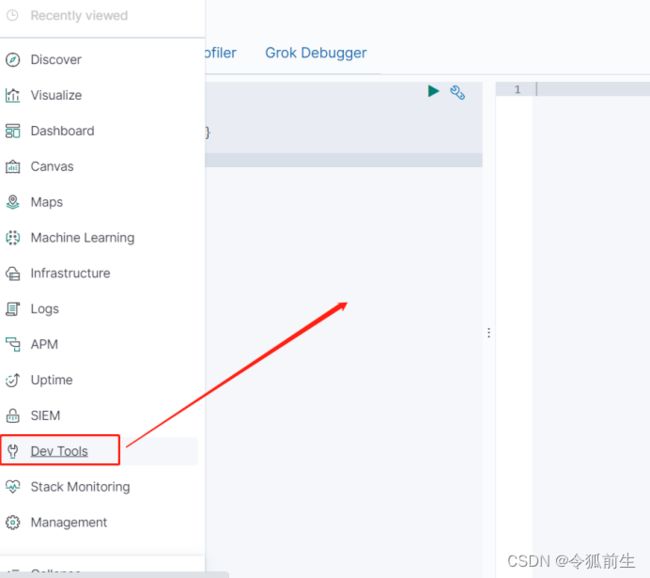
点击左边菜单栏”dev_tools”进入es索引操作界面:
3.5、安装IK分词器
安装包下载地址:Releases · medcl/elasticsearch-analysis-ik · GitHub
注意:IK的版本一定要与elasticsearch的版本一致,否则elasticsearch无法启动。
- 到elasticsearch的plugins目录下新建ik目录,将安装包放入此目录解压:
#mkdir ik
# unzip elasticsearch-analysis-ik-7.2.0.zip
- 解压后,重新启动elasticsearch。
- 验证分词器是否生效:
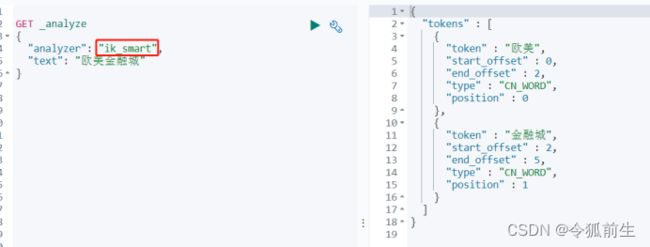
3.6、自定义扩展热词
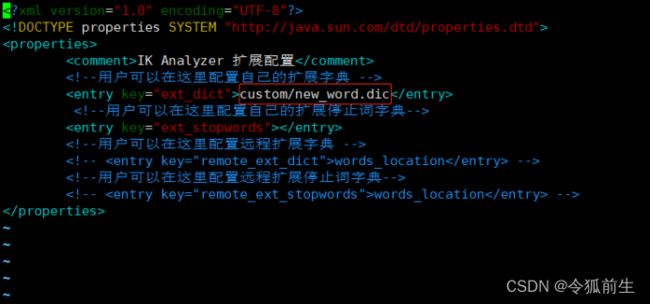
找到elasticsearch的ik目录,在该目录下新建一个自定义的目录扩展热词的目录,并新建一个文件,以”.dic”结尾(如下目录为custom, 文件名为new_word.dic, 输入自定义热词”斗罗大陆”):


配置自定义热词文件的加载(编辑文件ik/config/IKAnalyzer.cfg.xml, 在key=”ext_dict”的地方配置自定义热词文件的加载的路径, 该文件默认地址在ik目录下寻找):
重启elasticsearch,可以看到加载了自定义热词文件:
![]()
测试效果:

四、语法使用(重点)
4.1、ElasticSearch 常用字段类型
- 字符串类型
- text ⽤于全⽂索引,搜索时会自动使用分词器进⾏分词再匹配,支持模糊、精确查询
不支持聚合。
- Keyword不分词,搜索时需要匹配完整的值。
- 数值型类型
- 整型: byte,short,integer,long
- 浮点型: float, half_float, scaled_float,double
- 日期类型类型
- Date
| #插入|更新此字段的值时,有3种表示方式
"2020-04-18"、"2020/04/18 09:00:00"
1610350870
1641886870000 |
- 范围型类型
- integer_range
- long_range
- float_range
- double_range
- date_range
| 比如招聘要求年龄在[20, 40]上,mapping: age:{ "type" : "integer_range" } 插入|更新文档|字段时,值写成json对象的形式: "age" : { "gte" : 20, "lte" : 40 } gt是大于,lt是小于,e是equals等于。 |
- 布尔类型
- boolean #true、false
- ⼆进制类型
- binary 会把值当做经过 base64 编码的字符串,默认不存储,且不可搜索
4.2、Restful Api风格操作文档语法
| method |
描述 |
操作文档用法 |
| PUT |
创建文档(指定文档id) |
Ip:端口/索引名/文档id |
| POST |
更新文档 |
Ip:端口/索引名/文档id/_update |
| DELETE |
删除文档 |
IP:端口/索引名/文档id |
| GET |
查询文档 |
Ip:端口/索引名/_search |
4.2.1、使用kibana操作文档
- PUT创建索引
| PUT 索引名 |
- DELETE删除索引
| DELETE 索引名 |
- 使用PUT+mapping建立索引规则
| PUT 索引名/_mapping { "properties": { "字段名1" : { "type" : "字段类型" }, "字段名2" : { "type" : "字段类型" }, ... } } |
- 使用PUT添加文档
| PUT 索引名/_doc/文档id { "字段名":字段值, .. } |
- 使用POST更新文档
| POST 索引名/_update/文档id { "doc":{ "字段名":字段值, ... } } |
备注:如果使用put更新,没传值的字段则会被覆盖置为空值,推荐使用post更新。
- 使用GET查询所有文档
| GET 索引名/_search |
- 查看所有索引
| GET _cat/indices |
- 查看指定索引信息
| GET 索引名 |
备注:只看索引结构,可以使用“GET 索引名/_mapping?pretty”。
- 根据文档id查询文档
| GET 索引名/_doc/文档id |
- 条件查询文档
| GET 索引名/_search { "query":{ "match":{ "字段名":字段值 } } } 或 GET 索引名/_search { "query": { "match":{ "字段名":"条件1 条件2" } } } |
备注:query 表示查询;match 要匹配的条件信息,支持模糊查询左右或中间模糊)。一个字段如果匹配多条件,则空格隔开条件值(支持数组模糊查询)。
4.2.2、高级操作
- 指定条件查询,并限制返回的字段
| GET 索引名/_search { "query": { "match":{ "字段名":字段值} }, "_source":["展示的字段名1","展示的字段名2","展示的字段名3"] } |
备注:_source的值可以时单个字符串,也可以是字符串数组。
- 使用“_bulk”批量操作
| POST _bulk {"index":{"_index":"索引名","_id":文档id }} {"字段名1":字段值,"字段名2":"字段值"} {"index":{"_index":"索引名","_id":文档id }} {"字段名1":字段值,"字段名2":"字段值"} |
备注:id不存在则写入,已存在则更新。
- 使用“_update_by_update”批量更新
| POST 索引名/_update_by_query { "query": { "match": { "字段名":字段值 } }, "script": { "source":"ctx._source['字段名']=字段值;" } } |
- 使用“_update_by_update”并带script脚本操作
| POST 索引名/_update_by_query { "script": { "lang": "painless", "inline": "if(ctx._source.字段名== 条件值){ctx._source.字段名= 新值}" } } |
备注:inline表示脚本写在查询语句内,“lang”:“painless”表示脚本语言为painless(es5推出了简单安全且高效的painless脚本替代原有的一些脚本语言)。
- 分页查询排序
| GET 索引名/_search { "from": 2, "size": 2 } |
备注:“from”——起始值,下标0开始;“size”——页大小
- 排序
| GET 索引名/_search { "sort":{ "字段名":{"order":"desc"} } } |
备注:order的值:desc倒序,asc正序。”text”类型默认是不支持排序的,如果要支持排序则要设置Fielddata值为true。 但Fielddata是没有限制的,并且它的结果会被缓存在堆中,并且不会被GC掉。
- 布尔值查询——must
| GET 索引名/_search { "query": { "bool": { "must": [ {"match": {"字段名1":字段值} }, {"match":{"字段名2":字段值} } ] } } } |
备注:must是并且逻辑, 是个数组类型,里面可以跟多个条件,多个条件都满足才匹配; must_not是相反逻辑,不满足条件里的才匹配。
- 布尔值查询——should
| GET 索引名/_search { "query": { "bool": { "should": [ {"match": {"字段名1":字段值} }, {"match":{"字段名2":字段值} } ] } } } |
备注:shoud是或逻辑, 是个数组类型,里面只要其中一个条件符合就会匹配。
- 布尔值查询——filter
| GET 索引名/_search { "query": { "bool": { "filter": { "range": { "字段名": { "gte": 条件1, "lte": 条件2 } } } } } } |
备注:range里可以添加多个条件;gte(大于等于),lte(小于等于),gt(大于),lt(小于)。
- 使用term精确查询
| GET 索引/_search { "query":{ "term":{ "字段名":字段值 } } } 或 GET user/_search { "query":{ "bool":{ "should": [ {"term":{"字段名1":字段值} }, {"term":{"字段名2":字段值} } ] } } } |
备注:term是精确查询,使用倒排索引精确查询。
- 范围查询
| GET 索引名/_search { "query":{ "bool":{ "must":[ { "range": { "字段名": { "gte": 21, "lte":22 }}} ] } } } |
备注:gte(大于等于),lte(小于等于),gt(大于),lt(小于)
- 高亮查询
| GET 索引名/_search { "query": { "match": { "字段名": 字段值 } }, "highlight": { "fields": { "字段名": {} } } } 或自定义hmtl标签 GET 索引名/_search { "query": { "match": { "字段名": 字段值 } }, "highlight": { "pre_tags": "", "post_tags": "", "fields": { "字段名": {} } } } |
备注:匹配到的值会以html的em标签包装返回。使用“pre_tags”和“post_tags”可以自定义高亮标签。
- Kibana的查询结果解析

这里在user索引下创建了8个文档。
| #新建索引 PUT user #新建索引规则 PUT user/_mapping { "properties":{ "name":{"type":"keyword"}, "age":{"type":"long"}, "address":{"type":"text","fielddata":true}, "birthday":{"type":"date"}, "sort":{"type":"long"}, "level":{"type":"long"}, "tags":{"type":"text"} } } #添加数据 PUT user/_doc/1 { "name":"唐三", "age":23, "address":"斯莱克学院", "birthday":"1999-01-01", "sort":"1", "level": "102", "tags":["控制系魂师","强攻系魂师","敏功系魂师","蓝银草","昊天锤"] } PUT user/_doc/2 { "name":"小舞", "age":22, "address":"斯莱克学院", "birthday":"2000-01-01", "create_time":1657261332, "sort":"7", "level": "100", "tags":["敏功系魂师","柔骨兔"] } PUT user/_doc/3 { "name":"戴沐白", "age":25, "address":"斯莱克学院", "birthday":"2007-01-01", "create_time":1657261359, "sort":"2", "level": "100", "tags":["强攻系魂师", "白虎"] } PUT user/_doc/4 { "name":"朱竹青", "age":21, "address":"斯莱克学院", "birthday":"2002-01-01", "create_time":1657261371, "sort":"4", "level": "100", "tags":["敏攻系魂师", "幽冥灵猫"] } PUT user/_doc/5 { "name":"宁荣荣", "age":21, "address":"斯莱克学院", "birthday":"2001-01-01", "create_time":1657261382, "sort":"6", "level": "100", "tags":["辅助系魂师", "九宝琉璃塔"] } PUT user/_doc/6 { "name":"奥斯卡", "age":24, "address":"斯莱克学院", "birthday":"1998-01-01", "create_time":1657261382, "sort":"5", "level": "100", "tags":["食物系魂师","香肠"] } PUT user/_doc/7 { "name":"马红俊", "age":22, "address":"河南", "birthday":"2000-01-01", "create_time":1657261382, "sort":"3", "level": "100", "tags":["敏攻系魂师", "火凤凰"] } PUT user/_doc/10 { "name":"唐昊", "age":45, "address":"昊天宗", "birthday":"1977-01-01", "create_time":1657261382, "sort":"10", "level": "97", "tags":["强攻系魂师","昊天锤"] } |
- PUT创建索引时指定分片数量和副本数量
| PUT 索引名 { “settings”:{ “number_of_shards”:5, “number_of_replicas”:1 } } |
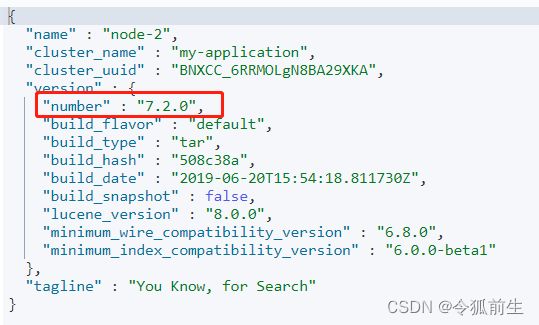
- 查看elasticsearch版本
| GET / |
-
五、SpringBoot操作Elasticsearch的Api接口(重点)
官方javadoc文档地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.2/java-rest-high.html
- 配置准备
Maven配置:
|
|
elasticsearch-rest-high-level-client内部依赖两个核心jar,如下:
- org.elasticsearch.client:elasticsearch-rest-client
- org.elasticsearch:elasticsearch
Java配置类准备:
| @Configuration public class ElasticSearchClientConfig { @Bean public RestHighLevelClient restHighLevelClient(){ return new RestHighLevelClient( RestClient.builder( new HttpHost("192.168.48.129", 9200, "http"), new HttpHost("192.168.48.130", 9200, "http"), new HttpHost("192.168.48.131", 9200, "http"))); } } |
- Api使用示例
| @SpringBootTest(classes = SpringbootEsApplication.class) class SpringbootEsApplicationTests { @Autowired private RestHighLevelClient restHighLevelClient; private static final String STUDY_INDEX_NAME = "study_index"; private static final String USER_INDEX_NAME = "user"; /** * 功能描述:创建索引 */ @Test public void createIndexTest() throws IOException { //1、创建索引请求 CreateIndexRequest createIndexRequest = new CreateIndexRequest(STUDY_INDEX_NAME); //2、客户端执行请求 IndicesClient,请求后获得响应 CreateIndexResponse response = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT); System.out.println(response); } /** * 功能描述:判断索引是否存在 */ @Test public void isExistIndexTest() throws IOException { GetIndexRequest getIndexRequest = new GetIndexRequest(STUDY_INDEX_NAME); boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT); } /** * 功能描述:删除索引 */ @Test public void deleteIndexTest() throws IOException { DeleteIndexRequest getIndexRequest = new DeleteIndexRequest(STUDY_INDEX_NAME); AcknowledgedResponse response = restHighLevelClient.indices().delete(getIndexRequest, RequestOptions.DEFAULT); System.out.println(response); } /** * 功能描述:创建文档 */ @Test public void createDocTest() throws IOException, ParseException { //创建对象 SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd"); Date birthday = simpleDateFormat.parse("1978-01-01"); User user = User.builder() .name("比比东") .age(44) .address("武魂殿") .birthday(birthday) .sort(9) .level(99) .tags(new String[]{"强攻系魂师","死亡蛛皇","噬魂蛛皇"}) .createTime(new Date()) .build(); //创建请求 IndexRequest request = new IndexRequest(USER_INDEX_NAME); //设置请求规则 request.id("9"); request.timeout("1s"); //将对象转换成json字符串放入请求 String value = JSON.toJSONString(user); request.source(value, XContentType.JSON); //客户端发送请求 IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT); System.out.println(response + ">>" + response.status()); } /** * 功能描述:判断文档是否存在 */ @Test public void isExistDocTest() throws IOException { GetRequest getRequest = new GetRequest(USER_INDEX_NAME, "9"); //不获取返回的_source的上下文了 // getRequest.fetchSourceContext(new FetchSourceContext(false)); // getRequest.storedFields("_none"); boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT); System.out.println(exists); } /** * 功能描述:获取文档 */ @Test public void getDocTest() throws IOException { GetRequest getRequest = new GetRequest(USER_INDEX_NAME, "9"); GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); //打印文档数据内容 System.out.println(response.getSourceAsString()); //打印文档全部内容 System.out.println(response); } /** * 功能描述:更新文档 */ @Test public void updateDocTest() throws IOException { UpdateRequest updateRequest = new UpdateRequest(USER_INDEX_NAME, "9"); // updateRequest.timeout("1s"); User user = new User(); user.setAddress("武魂帝国"); updateRequest.doc(JSON.toJSONString(user), XContentType.JSON); UpdateResponse response = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT); System.out.println(response + ">>" + response.status()); } /** * 功能描述:删除文档 */ @Test public void deleteDocTest() throws IOException { DeleteRequest deleteRequest = new DeleteRequest(USER_INDEX_NAME, "9"); // deleteRequest.timeout("1s"); DeleteResponse response = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT); System.out.println(response + ">>" + response.status()); } /** * 功能描述:批量插入文档 */ @Test public void bulkDocTest() throws IOException, ParseException { SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd"); Date tangchengBirthday = simpleDateFormat.parse("1958-01-01"); Date ayingBirthday = simpleDateFormat.parse("1978-01-01"); BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("1s"); ArrayList User tangchengUser = User.builder() .name("唐晨") .age(66) .address("昊天宗") .birthday(tangchengBirthday) .sort(8) .level(99) .tags(new String[]{"强攻系魂师","昊天锤"}) .createTime(new Date()) .build(); User ayingUser = User.builder() .name("阿银") .age(44) .address("斗罗森林") .birthday(ayingBirthday) .sort(11) .level(75) .tags(new String[]{"控制系魂师","蓝银草"}) .createTime(new Date()) .build(); arrayList.add(tangchengUser); arrayList.add(ayingUser); arrayList.stream().forEach(user ->{ IndexRequest source = new IndexRequest(USER_INDEX_NAME) .id(user.getSort() + "") .source(JSON.toJSONString(user), XContentType.JSON); bulkRequest.add(source); }); BulkResponse response = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); System.out.println(response.hasFailures() + ">>" + response.status()); } /** * 功能描述:查询文档 */ @Test public void searchDocTest() throws IOException { SearchRequest searchRequest = new SearchRequest(USER_INDEX_NAME); //构建查询条件 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // TermQueryBuilder queryBuilder = QueryBuilders.termQuery("address", "斯莱克学院"); QueryBuilder queryBuilder = QueryBuilders.matchQuery("address", "斯莱克学院"); sourceBuilder.query(queryBuilder); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); System.out.println(JSON.toJSONString(searchResponse.getHits())); System.out.println("-------------------------"); for (SearchHit fields : searchResponse.getHits().getHits()) { System.out.println(fields.getSourceAsMap()); } } } |
-
六、疑问(重点)
6.1、什么是全文索引
答:通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数。用户搜索时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户。
6.2、什么是倒排索引?怎么实现的?有什么作用?
答:请看ES的倒排索引介绍。
6.3、Elasticsearch走那个节点的路由规则是怎样的?
答:有个公式:shard = hash(routing) % number_of_primary_shards.
- routing: 默认值就是文档id, 也可以采用自定义值。
- number_of_primary_shards : 主分片的数量。shard : 取值从0开始。
6.4、ES写入数据的工作过程?
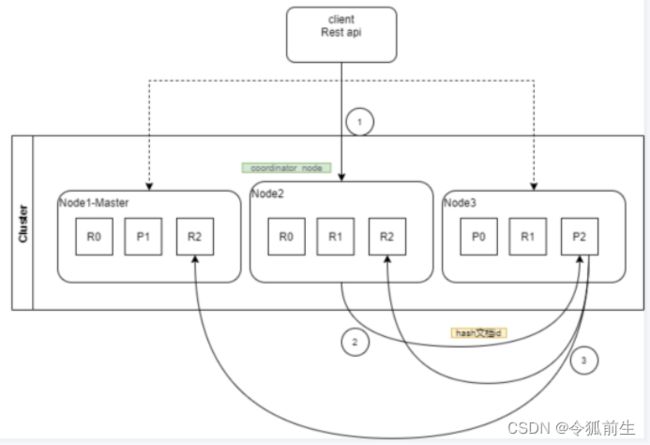
答:
- 客户端发送请求给任意节点,这个节点就成为协调节点。
- 协调节点将查询请求广播到每隔数据节点,这些数据节点的分片就会处理该查询请求。
- 每隔分片进行数据查询,将符合条件的数据放在一个队列中,并将这些数据的文档id、节点信息、分片信息都返回协调节点。
- 由协调节点将所有的结果进行汇总,并排序。
- 协调节点向包含这些文档id的分片发送get请求,对应的分片将文档数据返回给协调节点,最由协调节点将数据返回给客户端。
6.5、如何提高elasticsearch的查询性能?为什么?
答:
- 用好filesystem cache,不要什么数据都仍进ES。经常使用的索引数据最好控制不要大于filesystem cache总内存。如果大于可以考虑冷热数据分离(如ES+Hbase)。
- 数据预热:对热数据每隔一段时间,预先访问,让数据进入 filesystem cache 。
- 适当配置索引主从节点和增加索引副本,可以均衡节点的负载。
一个好的分片策略,首先要对业务和增长有一个预先的预判:首先控制每个分片的占用硬盘空间,不能超过es最大jvm的堆空间设定,一般是不超过32G。第二考虑一下node节点的数量,一般设定分片数不超过节点数的3倍,假如节点数是3,那么分片数最多不能超过9,是节点数的倍数。
副本数的个数,一方面考虑高可用让容灾,另一方面副本数可以根据请求流量的qps等参数,适当的提高副本数,来提高读性能。
- 尽量避免深度分页查询,使用scroll api(游标)。
6.6、Node主从节点数据是怎么同步的?
答:ES内部集成了文件复制的算法,通过PacificA是微软亚洲研究院提出的一种用于日志复制系统的分布式一致性算法。es的master监控集群和健康状态,分发索引分片到集群节点。
扩展:
当一个Replica故障时,ES会将其移除,当故障超过一定时间,ES会分配一个新的Replica到新的Node上,此时需要全量同步数据。但是如果之前故障的Replica回来了,就可以只回补故障之后的数据,追平后加回来即可,实现快速故障恢复。实现快速故障恢复的条件有两个,一个是能够保存故障期间所有的操作以及其顺序,另一个是能够知道从哪个点开始同步数据。
6.7、Elasticsearch集群是如何选举主节点的?
答:Elasticsearch的选主是Zen Discovery(集群发现机制)模块负责的, Zen Discovery封装了节点发送(ping)。
- 对所有可以成为master的节点,根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
- 如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
扩展:
发现新节点:ES内置自动发现实现 Zen discovery,当一个节点启动后,通过联系集群成员列表即可加入集群。集群中由其中一个节点担任主节点,用于集群元数据管理,维护分片在节点间的分配关系。当新节点加入集群后,Master 节点会自动迁移部分分片至新节点,均衡集群负载。
移除故障节点:分布式集群难免有节点故障。主节点会定期探测集群其他节点存活状态,当节点故障后,会将节点移出集群,并自动在其他节点上恢复故障节点上的分片。
6.8、怎么查看ES的索引大小?
答:在kibana上可以通过“GET _cat/indices?v”查看。

七、安装常见问题
7.1、Linxu安装elasticsearch启动时“elasticsearch max virtual memory areas vm.max_map_count [65530] is too low......报错”
问题因素:虚拟机内存太小。
解决办法:
- 配置/etc/sysctl.conf:添加vm.max_map_count = 262144
- 添加后执行生效命令:sysctl -p
![]()
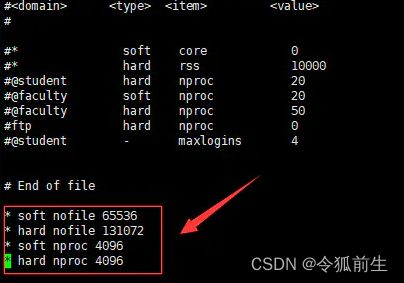
7.2、inux安装elasticsearch一直启动失败:max file descriptors [4096] for elasticsearch process is too low, incr...
问题因素:原因是进程不够用了
解决方法:
(1)切换到root用户,修改文件/etc/security/limits.conf
| //在文件末尾添加下面的参数值,注意前面带*号 * soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096 |
7.3、添加用户命令:
切换到root: useradd 用户名
7.4、目录赋予指定用户权限:
切换到root: chown -R elasticsearch:elasticsearch /opt