2022/12/11周报
目录
摘要
文献阅读
1、题目和摘要
2、GRU网络
3、注意力机制
4、数据处理
5、实验结果
深度学习
1、GRU
2、重置门和更新门
总结
摘要
本周在论文阅方面,阅读了一篇基于双重注意力机制和GRU网络的短期负荷预测模型的论文,GRU在能够很好的处理时序数据的同时,减少参数的使用。在深度学习上,对GRU的数学原理和重点部分展开了学习。
This week,in terms of thesis reading,i read a paper on short-term load forecasting model based on dual attention mechanism and GRU network. GRU can process time series data well and reduce the use of parameters.In depth learning,learning the mathematical principles and key parts of GRU.
文献阅读
1、题目和摘要
基于双重注意力机制和GRU网络的短期负荷预测模型
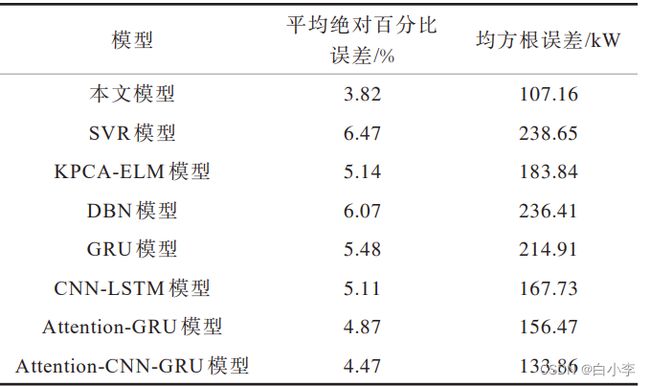
摘要:电力负荷预测对电力系统的部署、规划和运行影响重大,但目前各输入特征对电网负荷情况影响的程度不稳定,且递归神经网络捕获负荷数据的长期记忆能力差,导致预测精度下降。提出一种基于双重注意力机制和 GRU 网络的预测新模型,利用特征注意力机制自主分析历史信息与输入特征间的关联关系,提取重要特征,并通过时序注意力机制自主选取 GRU 网络中关键时间点的历史信息,提升较长时间段预测效果的稳定性。在 3个公开数据集上的实验结果表明,该模型在预测精度指标上表现良好,对比SVR、KPCA-ELM、DBN、GRU、Attention-GRU、CNN-LSTM、AttentionCNN-GRU 模型预测精度分别提高了 2.47、1.14、1.93、1.37、1.04、0.74、0.41 个百分点。
2、GRU网络
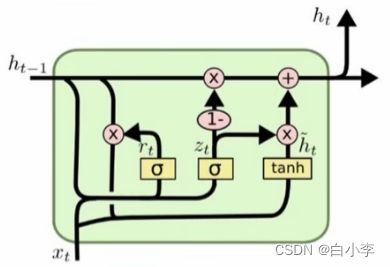
GRU 网络由 LSTM 网络改进而来,其通过减少及合并门结构单元优化 LSTM 复杂的内部结构 ,从而在保证精度的前提下提高网络的训练速度,GRU只包含更新门和重置门,减少了参数的训练。
更新门控制前一时刻状态信息保留到当前状态中的程度,值越大表示前一时刻的状态信息保留越多。
重置门控制当前信息与先前信息结合的程度,值越小说明忽略的信息越多。GRU的网络结构:
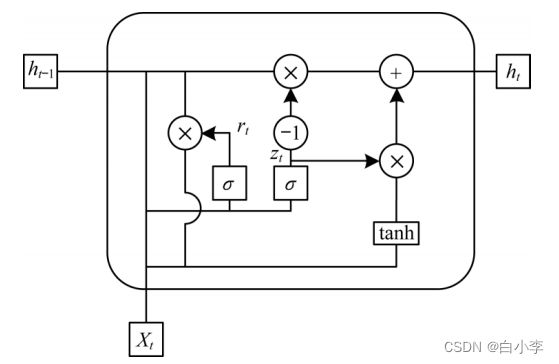
GRU 网络结构参数单据关系:
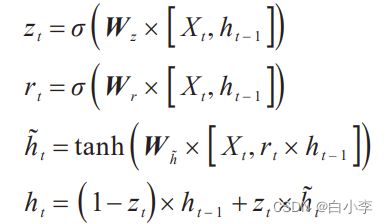
zt 为更新门;rt 为重置门;Xt为当前输入;h_t为输入和过去隐层状态的汇总;ht 为隐藏层输出;Wz、Wr、Wh_均为可训练参数矩阵。
3、注意力机制
深度学习中的注意力机制是根据人们在处理全局图像时,自主增强焦点区域信息通过抑制其他冗余区域表达的选择性来反映全局信息,而衍生出的以从众多信息中自主选择对当前任务更关键信息的一种信息处理方式。文章针对短期负荷预测深受实时变化的环境因素与居民自身主观因素影响的问题,设计出特征注意力机制和时序注意力机制,利用特征注意力机制来分析不同输入参量对负荷的重要程度,挖掘出关联关系。同时,利用时序注意力机制分析各历史时刻的负荷对待预测时刻负荷的重要程度,来选择关键时间点数据,从而提高预测精度。
特征注意力机制:
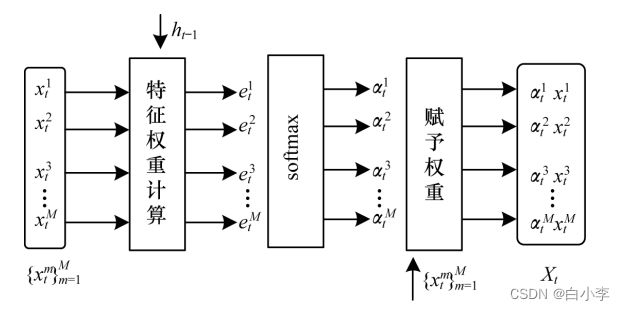
通过特征注意力机制学习当前时刻各输入特征与待预测负荷信息的相关性,并自适应处理原始输入的特征,以强化相关特征影响力及弱化不相关特征。
时序注意力机制:
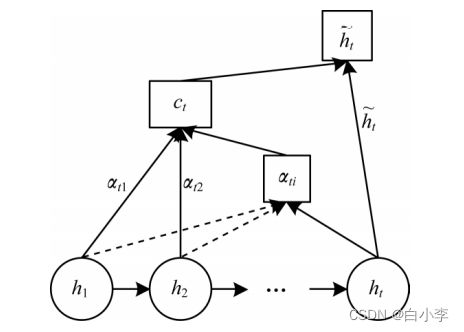
包含各历史时刻信息的最后一层隐层状态作为时序注意力机制的输入,分析历史状态与当前状态的关联性,并赋予影响权重,计算公式:
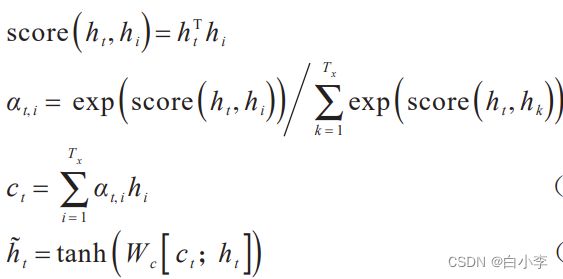
score 评分函数采用点积;αt,i 为历史输入的隐藏层状态对当前输入的注意力权重;ct 是中间向量; h_t表示最终输出的当前时刻的隐藏层状态值。
基于双重注意力机制的 GRU 模型:
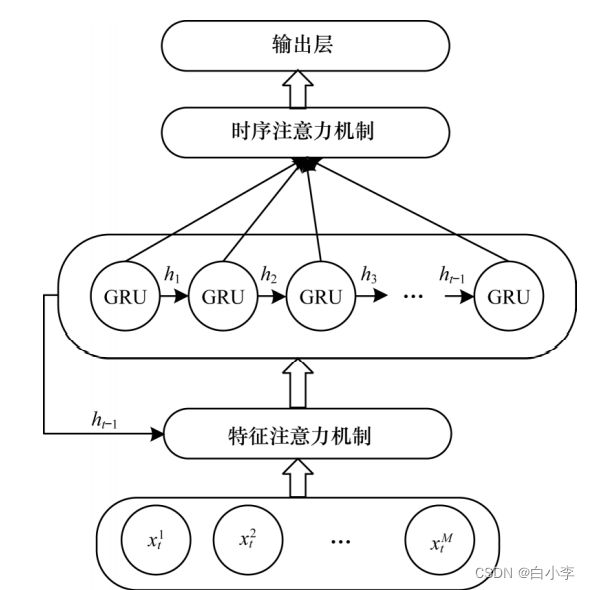
将原始输入信息和前一时刻 GRU 网络的输出通过注意力机制进行计算,并得出当前时刻输入的特征对本次预测的权重,赋予原始输入信息对应权重,得到新的输入信息。
4、数据处理
采用3个真实的电力负荷数据集验证模型性能:Mendeley 数据集、Kaggle 数据集、ERCOT 数据集。
包括:24 点负荷数据,温度,湿度,光强,降雨量,节假日情况(工作日为1,休息日为0),并间隔1h采集1次数据 。
对比模型:SVR、KPCA-ELM、DBN、GRU、Attention-GRU、CNNLSTM、Attention-CNN-GRU 。
误差指标采用平均绝对百分比误差和均方根误差。
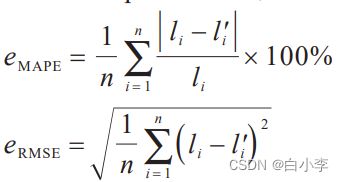
n 为预测点个数;li 表示第 i 点的真实值;l′i 表示第 i点的预测值。
5、实验结果
Mendeley 数据集上的实验结果对比
Kaggle 数据集上的实验结果对比:
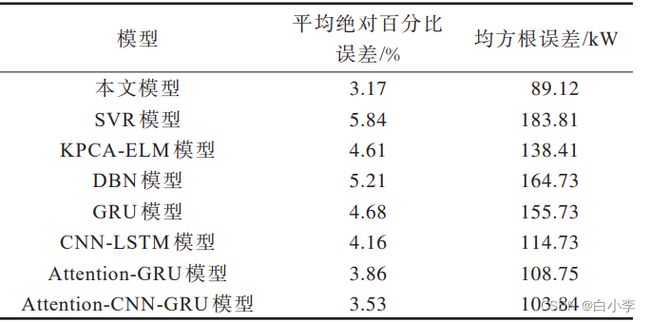
ERCOT 数据集上的实验结果对比:
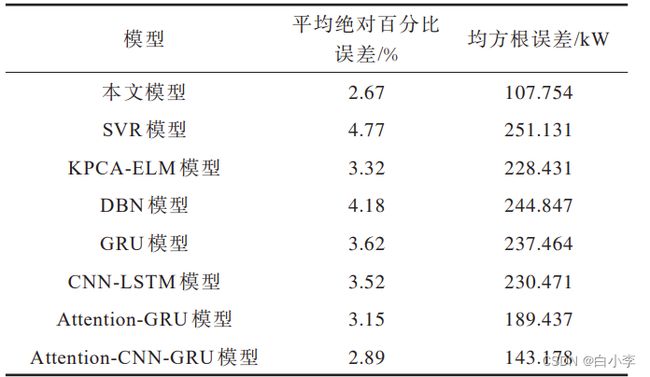
文章模型比传统机器学习、深度学习方法有更好的预测效果。此外,相比于传统关联分析与神经网络相结合的模型,本文模型取得的预测效果更好。
优化方向:引入特征选择算法以寻找更优的参考特征,并通过加深 GRU 网络隐藏层的深度,优化注意力模型,提高关联分析能力与短期负荷预测精度。
深度学习
1、GRU
GRU(Gated Recurrent Unit)也称门控循环单元结构, 是RNN的一种变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 它的核心结构可以分为两个部分去解析:更新门和重置门
优点:GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小。
缺点:GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算。
与LSTM相比:GRU的参数较少,因此其训练速度更快,或需要归纳的数据更少。相对应的,如果有足够的训练数据,表达能力更强的LSTM或许效果更佳。并且能降低过拟合风险。
单元结构:
数学表达式:
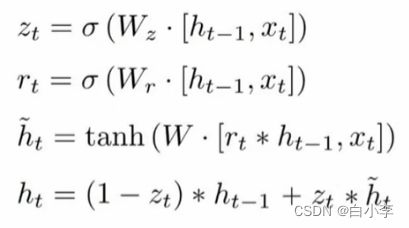
2、重置门和更新门
重置门决定了如何将新的输入信息与前面的记忆相结合
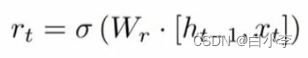
这里 并不是一个值,而是一个权重矩阵。用这个权重矩阵对
并不是一个值,而是一个权重矩阵。用这个权重矩阵对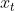 和
和 拼接而成的矩阵进行线性变换(两个矩阵相乘)。然后将两个矩阵相乘得到的值投入sigmoide函数,会得到
拼接而成的矩阵进行线性变换(两个矩阵相乘)。然后将两个矩阵相乘得到的值投入sigmoide函数,会得到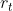 的值。
的值。
的值越小说明上一时刻需要遗忘的越多,丢弃的越多,越大说明上一时刻需要记住的越多,新的输入信息(也就是当前的输入信息)与前面的记忆相结合的越多。
重置门有助于捕捉时间序列里短期的依赖关系。
更新门公式:
![]()
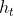 忘记传递下来的 中的某些信息,并加入当前节点输入的某些信息。这就是最终的记忆。
忘记传递下来的 中的某些信息,并加入当前节点输入的某些信息。这就是最终的记忆。
门控循环单元GRU不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元。
总结
本周学习了GRU的相关知识,针对GRU的原理部分学习的不是很清楚,作为RNN的变形和LSTM具有相似的结构,对于处理时序型数据上具有独特优势。接下来继续对RNN相关知识进行学习。
2022