EmotionGAN: Unsupervised Domain Adaptation for Learning Discrete Probability Distributions of Image
1.摘要
深度神经网络在具有大规模标签训练数据的各种基准视觉任务上表现良好;但是,获得这样的训练数据既昂贵又费时。由于域移动或数据集偏差,将在大规模标记的源域上训练的模型直接转移到另一个稀疏标记或未标记的目标域上通常会导致性能下降。在本文中,我们考虑了图像情感识别中的领域适应问题。
具体来说,我们研究如何以无监督的方式使图像情感从源域到目标域的离散概率分布适应。我们开发了一种用于情感分布学习的新型对抗模型,称为EmotionGAN,可交替优化生成对抗网络(GAN)的损失,语义一致性的损失和回归的损失。 EmotionGAN模型可以修改源域图像,以使其看起来像是从目标域中绘制的,同时保留注释信息。在FlickrLDL和TwitterLDL数据集上进行了广泛的实验,结果表明,与最新方法相比,该方法具有优越性。
2.介绍
在本文中,我们研究了一种非监督域适应(UDA)问题(无监督领域自适应(Unsupervised Domain Adaptation)介绍,Unsupervised Domain Adaptation by Backpropagation阅读笔记),该问题学习一个源域中图像情感的离散概率分布并将其适应目标域,同时要记住,仅预测DEC不足以实现高度主观的情感变量。开发了一种新型的对抗模型EmotionGAN,用于情感分布学习。类似于生成对抗网络(GAN),来自源域的图像由生成器修改,生成器使用对抗性损失进行训练。为了保留源图像的注释信息,我们用语义一致性损失来补充对抗性损失,这会惩罚自适应图像和源图像之间的较大语义变化。鉴别器网络用于区分图像是自适应的还是目标域的。通过这种方式,EmotionGAN模型可以修改源域图像,使其看起来好像是从目标域中绘制出来的,同时保留了注释信息。同时,对回归网络进行训练,以学习图像内容与情绪分布之间的映射。也就是说,我们交替优化GAN损失,语义一致性损失和回归损失。此外,如[31]中所述,为避免伪像,我们将辨别器的接收场限制在局部区域,从而导致每幅图像出现多个局部对抗性损失;为了稳定训练,我们使用改编图像的历史记录来更新鉴别器。在FlickrLDL和TwitterLDL数据集上的大量实验结果证明了所提出的UDA方法用于学习图像情绪分布的有效性。
本文的贡献:
(1)我们提出以一种无监督的方式使图像情感从源域到目标域的离散概率分布适应。 据我们所知,这是应用于IER任务的第一个域适应工作。
(2)我们开发了一种新的对抗模型EmotionGAN,用于情感分布学习,可以交替优化GAN损失,语义一致性损失和回归损失。 由于语义一致性的损失,改编后的图像与目标图像无法区分。 同时,保留源图像的注释信息。
(3)我们在FlickrLDL和TwitterLDL数据集上进行了广泛的实验,结果表明,提出的EmotionGAN模型明显优于最新的学习图像情感分布的UDA方法。
3.模型
EmotionGAN的主要思想是使用未标记的目标图像来学习具有参数的生成器,该参数将源图像x调整为x=(x;)。对的要求是,参数为的鉴别器不能将自适应图像x与目标图像x区分开来,并保留x的情感分布信息。给定生成器,我们可以创建任意大小的新数据集={X,Y}={((X;),Y)}。最后,我们可以在适应的数据集上训练参数为的回归器,就好像中的训练数据和中的测试数据来自同一分布一样。
 EmotionGAN:所提出的EmotionGAN模型的框架,用于从源域到目标域适应情绪分布预测。 黑色实线和蓝色虚线箭头分别表示训练和测试阶段的操作。 点划线箭头线对应于不同的损耗。
EmotionGAN:所提出的EmotionGAN模型的框架,用于从源域到目标域适应情绪分布预测。 黑色实线和蓝色虚线箭头分别表示训练和测试阶段的操作。 点划线箭头线对应于不同的损耗。
3.1GAN损失
为了训练我们的模型,我们使用生成性对抗损失来鼓励生成器生成与目标域图像相似的图像。在训练期间,(x;)→x将源图像x映射到自适应图像x。同时,训练鉴别器(x;),其输出给定图像x是自适应图像的可能性。鉴别器尝试将由生成的自适应图像和目标图像从目标域中区分出来。注意,以来自源域的图像作为输入,而传统GAN中的生成器是以噪声矢量为条件的。在GAN和SimGAN[之后,我们将其建模为两人minimax博弈,并交替更新和。
鉴别器试图使其参数的跟随损失最大化:
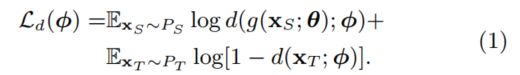
生成器试图使其参数的以下损失最小化:
![]()
具体算法过程如下:
3.2语义一致性损失
除了从源图像生成适应的图像之外,生成器还应保留源图像的情感分布。 此限制是使训练回归器的基本要素,该回归器将使用已适配的图像以及与源图像相对应的情感分布。 为此,我们建议使用语义一致性损失来最小化源图像和自适应图像的回归情绪分布之间的差异:
![]()
其中(·, ·)是测量两个概率分布之间的距离的函数。在这里,我们采用对称的Kullback-Leibler散度()。 因此,EmotionGAN的整体生成损失为:
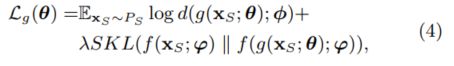
是控制语义一致性损失相对于对抗性损失的重要性的正则化系数,而(p‖q)定义为:

3.3回归损失
SimGAN模型分别训练回归器(仅)和GAN(和)。相反,所提出的情感是用回归因子(x;)→yˆ来增加的,回归因子将情感分布yˆ分配给适应的图像x。类似于基于CNN的情绪分布学习方法,参数通过最小化以下损失来优化:
![]()
3.4EmotionGAN学习过程
在我们的实现中,生成器是具有残差连接的卷积神经网络,可保持原始图像的分辨率。鉴别器和回归器也是卷积神经网络。 通过在两个随机梯度下降(SGD)步骤之间交替来实现所提出的EmotionGAN模型的优化。 在第一步中,我们使用SGD更新和,,同时保持固定。在第二步中,我们修复和,并使用SGD更新。 算法1中总结了该训练过程。

4.实验
4.1数据集
在中发布了两个用于离散情绪分布学习的图像数据集。一个是FlickrLDL数据集,FlickrCC的一个子集。FlickrLDL包含10700张图片,由11位观众使用Mikels的情感模型标记。
另一个数据集是twitterld,通过从Twitter中搜索不同的情感关键词,收集了30000张图片。删除复制后,图像由8个查看器标记。这样,TwitterLDL数据集由10045个图像组成。在这两个数据集中,通过整合工作人员的投票,得到每个图像的基本真实情感分布。例如,假设在8种情绪类别中,40名被试对一幅图像的感知情绪数量为=[6,12,0,14,3,6,0,9],则可通过/∑︀()=[0.12,0.24,0,0.28,0.06,0.12,0,0.18]得到离散的情绪分布。注意,一个受试者可能从同一个图像中感知到不止一种情绪。图3显示了不同情绪数的图像分布,这清楚地显示了情绪感知的主观性。
其他三个具有离散情绪分布信息的数据集是(1)抽象数据集,其中279幅抽象绘画基于Mikels的情绪模型;(2)情感数据集,其中1980幅图片来自Flickr,基于Ekman的6种基本情绪和中性情绪;(3)IESN数据集,其中1012幅,基于Mikels的情感模型,从Flickr中提取901幅图像,从中选取3792幅图像进行情感分布学习。由于数据集规模小,情感模型不同,社会形象的主观性较低,我们不使用Abstract,Emotion6和IESN数据集。应对这些挑战仍然是我们未来的工作。
4.2评价指标
与[41,42]类似,我们使用平方差之和()[43]、库尔贝克-莱布勒散度()、巴特查里亚系数1()和决定系数2(2)作为评估指标。0≤≤1,≥0,数值越低,性能越好。的范围从0到1,值越大表示效果越好。
0≤2≤1,数值越大,说明两种分布之间的线性关系越强。测量回归方面的性能,而、和2测量两个分布之间的距离。和强调每个单独的元素,而2考虑DPD中所有元素之间的差异。
4.3具体实现
生成器是一个残差网络(ResNet)[15],每个块由具有64个特征图的两个卷积层组成。输入图像的大小调整为64x64,然后与输出64个特征图的3x3滤镜进行卷积。输出通过12个ResNet块传递。最后一个ResNet块的输出传递到1x1卷积层,生成1个对应于适应图像的特征图。鉴别器包含7个卷积层和2个最大合并层,如下所示:(1)Conv3x3,步幅= [1,2],特征图= 96; (2)Conv3x3,步幅= [1,2],特征图= 96; (3)Conv3x3,步幅= 2,特征图= 64; (4)Conv3x3,步幅= 2,特征图= 64; (5)MaxPool3x3,步幅= 1; (6)Conv3x3,步幅= 1,特征图= 32; (7)Conv1x1,步幅= 1,特征图= 32; (8)Conv1x1,步幅= 1,特征图= 2; (9)Softmax。回归器f基于Inception-v3模型[33],该模型使用针对ImageNet分类训练的权重进行初始化。最后一个FL层的输出更改为,这可以在个情感类别上产生概率分布。原始损耗层将替换为第4.3节中的回归损耗。与SimGAN [31]相似,我们设计输出属于适应类的×ℎ个补丁的×ℎ维概率图,而不是整个图像的一个概率。这样,的接收场被限制在局部区域,这导致每个图像出现多个局部对抗性损失。另外,是使用精细图像的历史记录更新的,而不是仅使用当前迷你批处理中的图像。添加由先前网络生成的自适应图像的缓冲区,在每次训练迭代后将替换其中的50%。最初,我们训练为1,000步,为200步,为500步。然后在算法1中将,和分别设置为5、1和2。以恒定的0.001学习率,= 0.1和批处理大小512训练所有3个网络,直到验证误差收敛为止。实验是在4个具有32 GB CPU内存的NVIDIA TITAN Xp GPU上进行的。
4.4结果及分析
(1) 纯源方法,即直接将在源域上训练的模型转移到目标域,在两种适应环境下都表现得最差,由于域偏移或数据集偏差的影响,观测数据和情感分布标签的联合概率分布在两个域上有很大的差异。这导致模型从源域到目标域的可传输性较低。
(2) SimGAN和EmotionGAN这两种自适应方法都优于纯源方法,EmotionGAN的性能更好。这证明了EmotionGAN在无监督领域适应学习图像情感分布的有效性。
具体来说,与源代码twitter相比,EmotionGAN和SimGAN的性能分别提高了14.54%、17.83%、3.17%、18.03%和8.17%、8.50%、1.66%、9.68%,分别提高了37.90%、34.66%、5.68%、19.92%和21.11%、16.45%、2.60%、10.00%分别指向目标FlickrLDL。这些结果表明,所提出的EmotionGAN模型比目前最先进的方法具有更好的性能。性能的提高得益于情绪学中对GAN丢失、语义一致性丢失和回归丢失的交替探索。
(3) oracle方法,即使用在同一域上训练的模型在目标域上进行测试,取得了最佳的性能。然而,该模型是利用目标域的真实情感分布来训练的,而在无监督的域适应中是不可用的。
图5显示了一些预测情绪分布的示例。从结果中,我们可以看到EmotionGAN预测的分布比source only和SimGAN预测的分布更接近于基本事实。
这进一步证明了所提出的情绪模型的有效性。
消融术:没有语义一致性。我们还考虑了在不损失语义一致性的情况下进行学习的结果。结果见表5和表6。
我们观察到,在所有指标上,性能都显著下降。例如,与EmotionGAN SC相比,EmotionGAN从源域FlickrLDL到目标域twitterdl和从源域twitterdl到目标域FlickrLDL的性能增益分别为13.81%和26.08%。这是合理的,因为没有语义一致性的损失,自适应图像就不能保证保留对应源图像的情感分布标签。因此,经过训练的回归者并不是那么可靠。
参数敏感性。我们研究了方程(4)中超参数的影响。图6给出了由测量的情绪分布预测性能的变化。我们可以观察到,随着的变化,性能先增大后减小。这证实了交替优化语义一致性损失和GAN损失的有效性,因为它们之间的良好权衡可以增强可传递性。
5.总结
在本文中,我们解决了具有离散概率分布的学习图像情绪的无监督域自适应问题。这个问题有一个相关的挑战:感知主观性。开发了一种新型的对抗模型EmotionGAN,用于情感分布学习。通过交替优化GAN损失,语义一致性损失和回归损失,EmotionGAN可以调整源域图像,使其看起来好像是从目标域中提取出来的,并保留了注释信息。在FlickrLDL和TwitterLDL数据集上的实验结果表明,所提出的方法明显优于当前基准。
为了进一步研究,我们计划将提议的EmotionGAN模型扩展到其他图像情感识别(IER)任务,例如情感图像分类和回归。
联合施加多级约束(例如低级外观,中级功能和高级语义)可以更好地保留源图像的结构和属性。我们还旨在研究即使在源域和目标域使用不同的情感模型时也能很好适应的方法。