Python 字符串应用详解(全网最详)
目录
字符串编码
创建字符串
空字符串和len()函数
转义字符
字符串拼接
字符串复制
不换行打印
从控制台读取字符串
str()函数实现数字转字符串
使用[]提取字符(非常重要)
replace()实现字符串替换
字符串切片slice操作
split()函数分割和join()函数合并
字符串驻留机制和字符串比较
成员操作符
常用查找方法
去除首尾信息
大小写转换
格式排版
其他方法
字符串格式化
formt()基本用法
填充与对齐
数字格式化
可变字符串
为什么字符串要单独拿出来更新呢?
因为大多数程序员打交道的是"字符串"而不是数字,因为编程是用来解决实际问题的,当然,科研算法研究,还是和数字打交道的。那么字符串的本质是什么呢?
字符串的本质是:字符序列。Python 的字符串是不可变的,我们无法对原字符串做任何修改,我们只能再创建一个或者可以将字符串的一部分复制到新创建的字符串,达到看起来修改的效果。Python是不支持单字符类型,单字符也是作为一个字符串来使用的。
字符串编码
Python3 直接支持 Unicode编码,可以表示世界上任何书面语言的字符。Python3 的字符默认是16 位Unicode 编码。ASCALL码是Unicode 编码的子集。ASCALL码只能表示数字和英文,它是一个字节 8位。
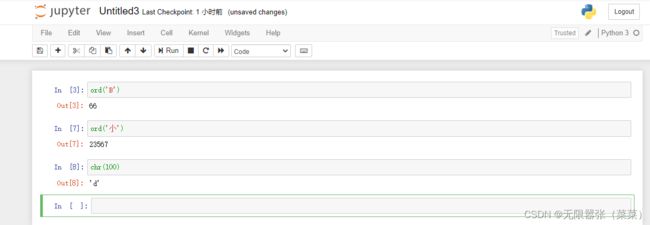
使用Python 内置函数ord()可以把字符转换成对应的Unicode码;
使用Python内置函数chr()可以把十进制数字转化成相对应的字符
eg:
创建字符串
(1)通过单引号和双引号来创建字符串,单引号和双引号字符串是一样的,他们是等价的。双引号和单引号都可以创建字符创,这就解决了字符串里边不能是单引号的问题,当然还有转义字符可以使用。eg:
 (2)连续三个单引号或者三个双引号,可以帮我们创建多个字符串。
(2)连续三个单引号或者三个双引号,可以帮我们创建多个字符串。
allchar = '''
id = '140603'
myname = '单身狗'
gender='man'
score = '100'
'''
print(allchar)
空字符串和len()函数
(1)Python 允许空字符串的存在,不包含任何字符,且长度相同.
(2)len()函数用来计算字符串的长度。
eg:
c = ''
print(c)
b = len(c)
print(b)
d = '小花我喜欢你'
print(d)
e = len(d)
print(e)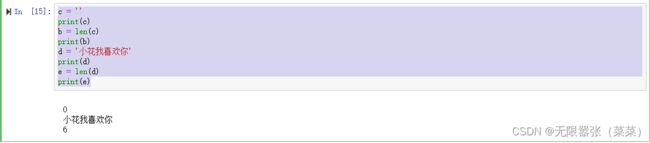
转义字符
我们可以使用“\+特殊字符”,实现某些难以用字符表示的结果。
| 转义字符 | 描述 |
| \(在行尾) | 换行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \b | 退格(Backspace) |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
eg:
# 源字符
a = "I love Xaio Hua"
# 换行
b = "I\nlov\nXaio Hua\n"
# \'
c = 'I \'m a teacher'
# 续行 \
d = 'aaaaaaaaaaaaaa\
bbbbbbbbbbbbbbbbbbb'
print(a)
print(b)
print(c)
print(d)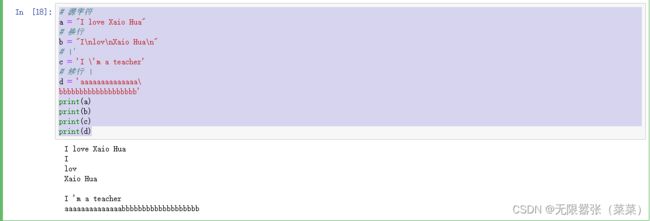
字符串拼接
1.利用+ 将多个字符串进行拼接
(1)如果+ 两边都是字符串,拼接。
(2)如果+两边都是数字,则加法运算。
(3)如果两边类型不同,则程序报错。
2.可以将多个字符串直接放到一块,实现拼接
eg:

字符串复制
使用 * 可以实现字符串复制
eg:

不换行打印
我们在前面调用print时,会自动打印一个换行符,有时我们不想要打印换行符,我们应该怎么办呢?我们在打印后边加一个end=任意字符,就不会换行了。什么意思呢?以前咱们是以\n换行符结尾,现在咱们以end=后边那个字符结尾。我下边写的是以空字符结尾。
a = 'zhangsan'
b = 'wangwu'
c = 'lisi'
print(a ,end = '')
print(b ,end = '')
print(c ,end = '')
从控制台读取字符串
有些交互程序,需要我们从控制台输入一些内容,此时,我们可以用 input() 从控制台读取字符串。
eg:

我们点回车,此时将字符串,赋值给a变量
str()函数实现数字转字符串
str可以将其他类型的函数转化为字符串。例如 str(5.20)==>'5.20'
当我们调用print()函数时,解释器自动调用了str()将非字符串的对象转成了字符串。
使用[]提取字符(非常重要)
字符串的本质就是字符序列,我们可以通过字符串后边添加[],在[]里面指定偏移量,可以提取该位置的单个字符。
正向搜索
最左边第一个字符,偏移量是0,第二个偏移量是1,以此类推,直到len(str)-1为止。
反向搜索
最右边第一个字符,偏移量是-1,第二个偏移量是-2,以此类推,直到-len(str)为止。
注意:正向搜索,其实索引为0
b = '1idffksoppaidiaooafo'
print(b)
print(b[0])
print(len(b) - 1)
print(b[-1])
print(b[-len(b)])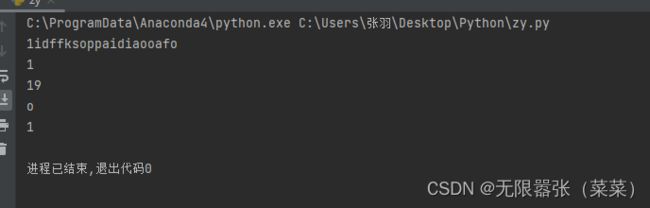
replace()实现字符串替换
字符串是不可改变的,我们通过[]可以获取字符串指定位置的字符,但是我们不能改变字符串,我们尝试改变字符串中的某个数值,会发现报错,如下:

所以,我们可以用 replace()来实现字符串的替换,对原来字符串进行修改
假设原字符串变量为:a
替换格式如下:
a.replace('原字符','要替换的字符')
eg:
a = '1khsjfjkskdfk'
b = a.replace('f','我爱你')
print(a)
print(b)
字符串切片slice操作
切片的意思是什么呢?很简单,就是截取子字符串,切片slice操作可以让我们快速的提取字符串,标准格式为:
[起始偏移量strat:终止偏移量end:步长step]
eg:按照b的顺序索引 我用的是正向索引,感兴趣可以试一下负向索引
b = 'hauihfioahfoiafhioifaihf'
#提取所有字符串
print(b[::])
#从0开始到2,步长为1
print(b[0:5:1])
#从5开始到10,步长为2
print(b[5:10:2])
split()函数分割和join()函数合并
split()可以基于指定分割符将字符串分割成多个字符串(存储到列表中),则默认使用空白字符(换行符/空格/制表符)。
eg:输入以下代码,将形成一个列表
a = 'I love you'
b = a.split()
print(b)
c = 'Xiao Hua is beautiful'
d = c.split('is')
print(d)
join()的作用和split()的作用刚好相反,它用于一系列子字符串的拼接,和列表联合起来使用。
格式如下:假设列表 a = ['I','Love','You','Xiao','Hua'],b = ‘连接符’.join(a)
eg:
a = ['I','Love','You','Xiao','Hua']
b = '*'.join(a)
print(b)
注意:
使用字符串拼接符+,会生成新的字符串对象,因此不推荐使用+来拼接字符串,推荐使用join()函数在拼接字符串之前会计算所有字符串的长度,然后逐一拷贝,仅新建一次对象。
总结:做拼接方法(3种)
(1)+ ;
(2)放在一起;
(3)join()函数;
join函数和+拼接,效率对比:
import time
# 初始化字符
a = 'a'
time01 = time.time() # 起始时刻
for i in range(1000000):
a += 'XiaoHua'
time02 = time.time() # 终止时刻
print("运算时间:"+str(((time02 - time01))))
time03 = time.time() # 起始时刻
lieBiao = []
for i in range(1000000):
lieBiao.append('XiaoHua')
a = ''.join(lieBiao)
time04 = time.time() # 终止时刻
print("运算时间:"+str(((time04 - time03))))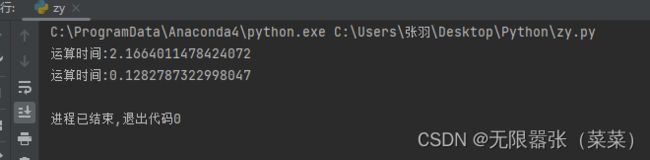
通过运行时间结果对比可知,+的拼接所用时间远远大于join()函数拼接所用时间。为什么join()函数的拼接运行时间远远小于+拼接所运行时间呢?
因为+拼接在运行过程中会创建新的对象,在引用时,所用时较长,而join()函数拼接,在运行时只有一个对象,不会创建新的对象,所以用时较少。当循环较大时,他们的区别更是明显。
字符串驻留机制和字符串比较
字符串驻机制:仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串驻留池中,Python支持字符串驻留机制,对于符号标识符规则的字符串(仅包含下划线(_)、字母和数字)会启用字符串字符串驻留机制。
怎么理解呢?
eg:
定义一个字符串对象 a = "zy000_11",在内存中将会创建一个"zy000_11"对象,当创建b = "zy000_11",他不会新创建一个"zy000_11"而是也去引用a创建的对象,相当于a 和b同时引用了一个对象。c = "zy000_11##",d = "zy000_11##"他们内容相同,但是他们不是同一对象,因为他们不满足标识符的命名规则。

成员操作符
in/not in 关键字,判断某个字符(字符串)是否存在于字符串中

前边方法已经全部讲解完毕 ,接下来对字符串常用方法进行汇总(比较简单)
常用查找方法
我们以一段文本做测试
a = "今天我好饿,我去问隔壁小花家要了6个馒头,可是她太小气了,嫌弃我长得丑,只给了我5个馒头,我很开心,因为我吃了2个,给我家小黄还留了3个"
| 方法使用和示例 | 说明 | 结果 |
| len(a) | 字符串长度 | 68 |
| a.startswith(‘今天我好饿’) | 以指定字符串开头 | True |
| a.endswith(‘3个’) | 以指定字符串结尾 | True |
| a.find('馒头') | 第一次出现指定字符串的位置 | 18 |
| a.rfind('馒头') | 最后一次出现指定字符串的位置 | 42 |
| a.count('我') | 指定字符串出现了几次 | 7 |
| a.isalnum() | 所有字符全是字母或者数字 | False |

去除首尾信息
我们可以通过strip()去除字符串首位指定信息。通过lstrip()去除字符串左边指定信息,rstrip()去除字符串右边指定信息。如果不写去除的地方,将默认去除首位的空格。

大小写转换
假设一个变量:a = "Good good study,Day day up"
| 示例 | 说明 |
| a.capitalize() | 产生新的字符串,首字母大写 |
| a.title() | 产生新的字符串每个单词首字母都大写 |
| a.upper() | 产生新的字符串,所有字符全转成大写 |
| a.lower() | 产生新的字符串,所有字符全转成小写 |
| a.swapcase() | 产生新的字符串,所有字符大小写转换 |

格式排版
center()、ljust()、rjust() 这三个函数用于对字符串实现排版,分别是居中,左对齐,右对齐。
eg:

其他方法
1.isalnum() 是否为字母或者数字
2.isalpha() 检测字符串是否只由字母组成(含汉字)
3.isdigit() 检测字符串是否只由数字组成
4.isspace() 检测是否为空白符
5.isupper() 检测是否为大写字母
6.islower() 检测是否为小写字母
字符串格式化
formt()基本用法
子Python 2.6 版本以后开始,新增加了一种格式化字符串的函数 str.format(),他增强了字符串格式化功能。
基本语法是通过{}和:来替代原来的%。
format函数可以接受不限个参数,位置可以不按顺序。
格式如下:
a = "名字是:{0},年龄是:{1}",此时 0 和 1那里不知道是多少,我们只是占位,之后通过format()函数来填充。eg: a.format("小花",18),这样需要关注顺序,传入的第一个必须是0,第二个必须是1.
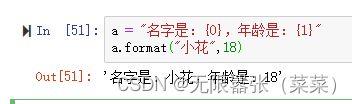
a = "名字是:{name},年龄是:{age}",此时 name 和 age那里不知道是多少,我们只是占位,之后通过format()函数来填充。eg: a.format(age=18,name='小花'),直接替换,这样不需要关注顺序。

填充与对齐
填充常和对齐一起使用
^、<、>分别是居中、左对齐、右对齐,后面带宽度
:后边带填充的字符,只能是一个字符,不指定默认是以空格填充
a = "小花不给我吃{steamed_bread},我不喜欢她,我喜欢{dog:h^10}"
a.format(steamed_bread="馒头", dog="狗")
数字格式化
浮点数通过f,整数通过d进行需要格式化:
a = "{name}的存款有{num:2f}"
a.format(name = '小花',num = 2000)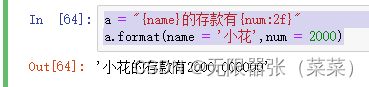
可变字符串
前边我们介绍,字符串属于不可变对象,不支持原地修改,如果要修改其中的值,智能创建新的字符串对象,但是,我们经常需要原地修改字符串,可以用io.strigIO对象或array模块。当字符串修改频繁,我们可以用此方法。
import io
s = 'good good study,day day up'
sio = io.StringIO(s)
sio.getvalue()
sio.seek(len(s))
sio.write('okkkkk')
print(sio.getvalue())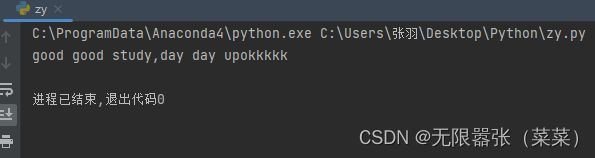
创作不易,如果您感觉有用,记得关注,点赞,收藏哦!!!