答疑解惑:开发者必须了解的Unicode和字符编码系统
目录
前言
ASCII
Unicode
UTF-8
C#中的字符串类型
UTF-16
String.Length 返回的是字符个数吗?
问题与答案
总结
参考
前言
请大家先思考几个问题
- 为什么有时候页面文本全是“锟斤拷”等乱码,有时候是个别字符别被替换为了�呢?
- 有了解过ASCII, UTF-8, UTF-16, Latin1等字符集的设计原理与应用吗?
- 开发过程中是否思考过字符串编码解码问题,文本都可以用UTF-8解码吗?
- mysql默认字符集为什么是Latin1?
- 网页,邮箱等互联网通信是如何确定内容的编码格式的?
请先不要着急知道答案,这篇博客不会从计算机编码系统历史讲起,也不会详细讲解每种编码方案的具体实现。
我会以尽量简洁的语言来描述计算机字符编码系统,以及和我们软件开发者的关系。
ASCII
相信每位开发者都知道ASCII。ASCII是一种早期基于拉丁语而设计的单字节编码方案,因此能表示的符号上限为256种。很明显,这种编码规则不能满足全世界人民的使用。
Unicode
Unicode 是一种表达范围更广泛的国际编码标准。它拥有110多万个码位,几乎可以表示地球上所有语言系统, 码位是一个整数值,范围从 0 到 U+10FFFF(十进制 1,114,111), 除了汉字,日语等, 像 这种表情符号, 少见的突厥文字也都有对应的编码表示。
通常使用语法
U+xxxx来表示码位,其中xxxx是十六进制编码的整数值。整个码位范围包含两个子范围:
U+0000..U+FFFF这个 16 位范围提供 65,536 个码位,足以涵盖世界上大多数编写系统。U+10000..U+10FFFF范围内的补充码位。 这个 21 位范围提供了超过一百万个额外的码位,可用于不太知名的语言和其他用途,例如表情符号。
UTF-8
但是最初很多人对Unicode的设计并不满意,因为世界上有很多软件是不需要考虑国际化的,尤其是英语国家,他们没有理由接受一种更复杂的编码方案,并且要花原先两倍的空间去存储“A, B, c, d...”。
后来出现的UTF-8成功的解决了这个问题,它是针对Unicode而设计的一种可变长度字符编码。
我们通过C#的方法来测试:可以看到字符“A” 经过UTF-8编码后得到的字节数是1,而汉字 “郭” 编码后的字节长度则是3。
这一点我们通过查阅UTF-8详细的编码标准可以证实。
C#中的字符串类型
UTF-16
有传言说C#当中的字符串就是Unicode,这其实是一个非常容易混淆的概念,或许java, python等其它语言也有过类似的讨论。
Unicode只是将数字和字符逻辑映射的概念编码,它并没有指定字符是如何在计算机上存储的。
假如你不太理解这句话,我们接着往下看。
在认识字符串编码之前,我们需要清楚:C#中的string实际上是一种16位的值序列,也就是我们熟悉的char数组,1个char占有2个字节的空间。
在C#中使用Encoding.Unicode可以得到一个静态对象:以小端字节序获取UTF-16格式的编码器。
我们可以使用该编码器提供的Api,对常见的字符串进行编码测试。
我们下面来看段C#代码:
using System.Text;
var utf16 = Encoding.Unicode;
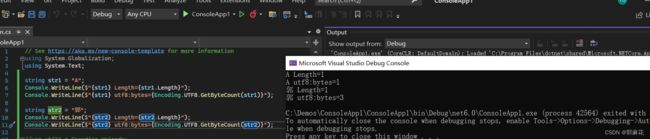
string str1 = "A";
Console.WriteLine($"{str1} Length={str1.Length}");
Console.WriteLine($"{str1} utf16:bytes={utf16.GetByteCount(str1)}");这我们获取到:字符串“A” 经过utf-16编码得到的字节数组长度为2,这与使用UTF-8编码器得到的结果并不相同。
UTF-16也属于变长编码,也就是说并不是所有的符号编码后的字节长度都是2。比如:“” 这种表情符号。
String.Length 返回的是字符个数吗?
我们再来测试当一个C#字符串中包含特殊字符时,比如:,字符串长度是多少
var utf16 = Encoding.Unicode;
//string str1 = "A";
//Console.WriteLine($"{str1} Length={str1.Length}");
//Console.WriteLine($"{str1} utf16:bytes={utf16.GetByteCount(str1)}");
string str2 = "";
Console.WriteLine($"{str2} Length={str2.Length}, Length表示字符串中的char个数");
Console.WriteLine($"{str2} utf16:bytes={utf16.GetByteCount(str2)}");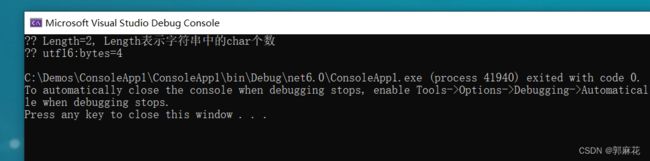 标Windows控制台依然采用GDI+的方式渲染输出, 表情等特殊字符无法被渲染题
标Windows控制台依然采用GDI+的方式渲染输出, 表情等特殊字符无法被渲染题
我们可以看到尽管第二个字符串只有一个玫瑰符号,但string.Length的值却是2,这意味着它是两个char,占了四个字节。
这可能会给我们的开发工作带来一些问题,例如:当你将一个string当作char[] 进行处理时。
最佳实践原则:在涉及字符串编码问题时,永远将字节流看作是一个整体进行操作。
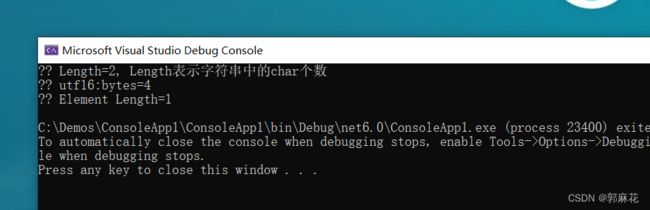
不过,假如你必须对包含特殊符号的字符串进行逐字符的处理,那么你可以使用下面这种方法,使用StringInfo.GetTextElementEnumerator可以完整的识别出文本中的字符元素:
string str2 = ""; Console.WriteLine($"{str2} Length={str2.Length}, Length表示字符串中的char个数"); Console.WriteLine($"{str2} utf16:bytes={utf16.GetByteCount(str2)}"); var enumerator = StringInfo.GetTextElementEnumerator(str2); int lenght = 0; while (enumerator.MoveNext()) { lenght++; } Console.WriteLine($"{str2} Element Length={lenght}");
问题与答案
那么,假如你理解了我上面所讲的内容,开头的那几个问题的答案大致也能想出来了。
1. 为什么有些时候页面文本全是“锟斤拷”等乱码,有些时候是个别字符别替换为了�呢?
答:当出现大面积乱码时,往往是因为编码和解码使用的方案不同。比如将文本通过GB2312编码,但解码时却是使用UTF-8,UTF-8就会将字节流以它的方式来解码,因此页面上就出现了乱码。而很多编码系统在字符集上是有重叠部分的,尤其是前127个用来表示英语字母的部分,因此假如你使用Latin1来编码一段英语文本,使用UTF-8来解码,大部分字符都将是正常的,但是127之后的特殊字符有可能就会解码失败。至于那些解码失败的字符是被替换成什么,或是是直接抛出异常,取决于具体的代码实现。
2. MySQL的默认编码为什么是Latin1?
答:Latin1编码范围使用了单字节内的所有空间。计算机最终存储的都将是字节序列流,而任何文本/字节流都可以被当作Latin1来编码/解码。
MySql默认编码是Latin1就是利用了这个特性。
3. 我能否在不知道编码方式的情况下对字符串进行解码?
答:因为每种人类语言都有不同的字母使用特征直方图,因此可以根据各种字节在各种语言的文本中出现的频率来猜测使用了哪种语言和编码,事实上IE浏览器就是这么做的。一些编程语言也提供了类似的api来做,但.NET并不支持这种模糊的做法。
4.如何在开发时解决可能出现的乱码问题?
答:约定。在Html最开始的地方约定当前网页的编码方案,当浏览器解析到编码方案时,会使用该方案重新解析。使用Http请求头中的Content-Type,XML中的encoding属性等。
总结
Unicode只是将数字和字符逻辑映射的概念编码,它并没有指定字符是如何在计算机上存储的。
所以问 “一个Unicode字符会占几个字节”是没有意义的。
在Unicode官方资料中,Unicode的编码方式有三种:UTF-8、UTF-16、UTF-32。由于UTF-8与字节序无关,同时兼容ASCII编码,使得UTF-8编码成为现今互联网信息编码标准而被广泛使用,而C#中的string类型则默认使用了UTF-16。
到这里,我不知道有没有把字符编码系统的基本概念讲明白,但请记住最重要的一句话:
无论在什么情况下,不清楚编码方式的字符串是没有意义的,计算机没有“纯文本”这种概念。
参考
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) – Joel on Software
Introduction to character encoding in .NET | Microsoft Learn