利用自己构建的网络进行鼾声识别
1 目前的工作
1.1 数据
5692条3s且采集率为8000hz的鼾声与6824条3s且采集率为8000hz的其他类音频。通过FFT频谱转换为300个(30,513,1)的矩阵。训练集与测试集的比例为9:1。数据集来源为google开源的数据集。
1.2 模型
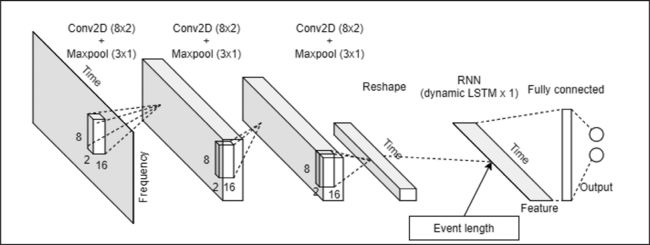
layer2: Conv2D(1, (3, 3), strides=(1, 1))。第二层为卷积核为3,步长为1的卷积层,输入为(28,511,1)的矩阵,输出为(26,509,1)的矩阵。
layer3: Conv2D(1, (3, 3), strides=(1, 1))。第三层为卷积核为3,步长为1的卷积层,输入为(26,509,1)的矩阵,输出为(24,507,1)的矩阵。
layer4: Reshape((24, 507),通过reshape给矩阵降维,将(24,507,1)转换为(24,507)。
Layer5: LSTM(2).输出为(2)的长短期记忆网络,输入为(24,507)的矩阵,输出为(2)的矩阵,再接一个softmax激活函数。
1.3 优化器与损失函数
优化器:选择的是学习率为0.0001的Adam优化器。
损失函数:二分类交叉熵。
1.4 评价指标
预测正确的个数/总的测试样本个数。
1.5 测试结果
训练轮数为500轮,采用10倍交叉验证得到最终测试结果为0.75。
2 下一步工作
2.1 数据
按鼾声、咳嗽、梦话、喷嚏收集数据(负责人:梁翔宇,彭子峰,最后梁翔宇汇总,完成时间:2021.10.26)
2.2 语音预处理
调研语音事件检测方法,对收集好的语音进行分割。(方法调研并完成测试:樊俊,完成时间2021.10.26)
2.3 模型优化
对现有模型进一步完善和优化(比如将现在的FFT模型改为Q转换,并能对网络有一定物理解释),并思考Android端代码的开发。(负责人:容斌元,完成时间:2021.10.26)