卷积网络和卷积神经网络
关于这个项目 (About this project)
This project is part of the Algorithms for Massive Data course organized by the University of Milan, that I recently had the chance to attend. The task is to develop the Deep Learning model able to recognize eye diseases, from eye-fundus images using the TensorFlow library. An important requirement is to make the training process scalable, so create a data pipeline able to handle massive amounts of data points. In this article, I summarize my findings on convolutional neural networks and methods of building efficient data pipelines using the Tensorflow dataset object. Entire code with reproducible experiments is available on my Github repository: https://github.com/GrzegorzMeller/AlgorithmsForMassiveData
该项目是我最近有幸参加的由米兰大学组织的“海量数据算法”课程的一部分。 任务是开发使用TensorFlow库从眼底图像识别眼睛疾病的深度学习模型。 一个重要的要求是使培训过程具有可扩展性,因此创建一个能够处理大量数据点的数据管道。 在本文中,我总结了有关卷积神经网络和使用Tensorflow数据集对象构建有效数据管道的方法的发现。 我的Github存储库中提供了具有可重复实验的整个代码: https : //github.com/GrzegorzMeller/AlgorithmsForMassiveData
介绍 (Introduction)
Early ocular disease detection is an economic and effective way to prevent blindness caused by diabetes, glaucoma, cataract, age-related macular degeneration (AMD), and many other diseases. According to World Health Organization (WHO) at present, at least 2.2 billion people around the world have vision impairments, of whom at least 1 billion have a vision impairment that could have been prevented[1]. Rapid and automatic detection of diseases is critical and urgent in reducing the ophthalmologist’s workload and prevents vision damage of patients. Computer vision and deep learning can automatically detect ocular diseases after providing high-quality medical eye fundus images. In this article, I show different experiments and approaches towards building an advanced classification model using convolutional neural networks written using the TensorFlow library.
早期眼病检测是预防由糖尿病,青光眼,白内障,年龄相关性黄斑变性(AMD)和许多其他疾病引起的失明的经济有效方法。 根据世界卫生组织(WHO)的目前,全世界至少有22亿人有视力障碍,其中至少有10亿人本来可以预防[1]。 快速和自动检测疾病对于减轻眼科医生的工作量并防止患者视力损害至关重要。 提供高质量的医学眼底图像后,计算机视觉和深度学习可以自动检测眼部疾病。 在本文中,我展示了使用使用TensorFlow库编写的卷积神经网络构建高级分类模型的不同实验和方法。
数据集 (Dataset)
Ocular Disease Intelligent Recognition (ODIR) is a structured ophthalmic database of 5,000 patients with age, color fundus photographs from left and right eyes, and doctors’ diagnostic keywords from doctors. This dataset is meant to represent the ‘‘real-life’’ set of patient information collected by Shanggong Medical Technology Co., Ltd. from different hospitals/medical centers in China. In these institutions, fundus images are captured by various cameras in the market, such as Canon, Zeiss, and Kowa, resulting in varied image resolutions. Annotations were labeled by trained human readers with quality control management[2]. They classify patients into eight labels including normal (N), diabetes (D), glaucoma (G), cataract (C), AMD (A), hypertension (H), myopia (M), and other diseases/abnormalities (O).
眼病智能识别(ODIR)是一个结构化的眼科数据库,包含5,000名年龄的患者,左眼和右眼的彩色眼底照片以及医生的医生诊断关键字。 该数据集旨在代表由上工医疗技术有限公司从中国不同医院/医疗中心收集的“真实”患者信息集。 在这些机构中,眼底图像由市场上的各种相机(例如佳能,蔡司和Kowa)捕获,从而产生不同的图像分辨率。 注释由经过培训的人类读者进行质量控制管理来标记[2]。 他们将患者分为八个标签,包括正常(N),糖尿病(D),青光眼(G),白内障(C),AMD(A),高血压(H),近视(M)和其他疾病/异常(O) 。
After preliminary data exploration I found the following main challenges of the ODIR dataset:
经过初步的数据探索,我发现了ODIR数据集的以下主要挑战:
· Highly unbalanced data. Most images are classified as normal (1140 examples), while specific diseases like for example hypertension have only 100 occurrences in the dataset.
·高度不平衡的数据。 大多数图像被归类为正常图像(1140个示例),而特定疾病(例如高血压)在数据集中仅出现100次。
· The dataset contains multi-label diseases because each eye can have not only one single disease but also a combination of many.
·数据集包含多标签疾病,因为每只眼睛不仅可以患有一种疾病,而且可以患有多种疾病。
· Images labeled as “other diseases/abnormalities” (O) contain images associated to more than 10 different diseases stretching the variability to a greater extent.
·标记为“其他疾病/异常”(O)的图像包含与10多种不同疾病相关的图像,这些图像在更大程度上扩展了变异性。
· Very big and different image resolutions. Most images have sizes of around 2976x2976 or 2592x1728 pixels.
·非常大且不同的图像分辨率。 大多数图像的大小约为2976x2976或2592x1728像素。
All these issues take a significant toll on accuracy and other metrics.
所有这些问题都会对准确性和其他指标造成重大损失。
数据预处理 (Data Pre-Processing)
Firstly, all images are resized. In the beginning, I wanted to resize images “on the fly”, using TensorFlow dataset object. Images were resized while training the model. I thought it could prevent time-consuming images resizing at once. Unfortunately, it was not a good decision, execution of one epoch could take even 15 minutes, so I created another function to resize images before creating the TensorFlow dataset object. As a result, data are resized only once and saved to a different directory, thus I could experiment with different training approaches using much faster training execution. Initially, all images were resized to 32x32 pixels size, but quickly I realized that compressing to such a low size, even though it speeds up the training process significantly, loses a lot of important image information, thus accuracy was very low. After several experiments I found that size of 250x250 pixels was the best in terms of compromising training speed and accuracy metrics, thus I kept this size on all images for all further experiments.
首先,调整所有图像的大小。 一开始,我想使用TensorFlow数据集对象“即时”调整图像大小。 在训练模型时调整图像大小。 我认为这可以防止耗时的图像立即调整大小。 不幸的是,这不是一个好的决定,一个纪元的执行甚至可能花费15分钟,因此我创建了另一个函数来调整图像大小,然后再创建TensorFlow数据集对象。 结果,数据仅调整一次大小并保存到其他目录,因此我可以使用更快的训练执行速度来尝试不同的训练方法。 最初,所有图像的大小都调整为32x32像素,但是很快我意识到压缩到这么小的尺寸,即使它可以显着加快训练过程,也会丢失很多重要的图像信息,因此准确性非常低。 经过几次实验,我发现250x250像素的尺寸在降低训练速度和准确性指标方面是最好的,因此我将所有图片的尺寸都保留下来,以进行进一步的实验。
Secondly, images are labeled. There is a problem with images annotations in the data.csv file because the labels relate to both eyes (left and right) at once whereas each eye can have a different disease. For example, if the left eye has a cataract and right eye has normal fundus, the label would be a cataract, not indicating a diagnosis of the right eye. Fortunately, the diagnostic keywords relate to a single eye. Dataset was created in a way to provide to the model as input both left and right eye images and return overall (for both eyes) cumulated diagnosis, neglecting the fact that one eye can be healthy. In my opinion, it does not make sense from a perspective of a final user of such a model, and it is better to get predictions separately for each eye, to know for example which eye should be treated. So, I enriched the dataset by creating a mapping between the diagnostic keywords to disease labels. This way, each eye is assigned to a proper label. Fragment of this mapping, in the form of a dictionary, is presented in the Fig. 1. Label information is added by renaming image names, and more specifically, by adding to the image file name one or more letters corresponding to the specific diseases. I applied this solution because this way I do not need to store any additional data frame with all labels. Renaming files is a very fast operation and in the official TensorFlow documentation, TensorFlow datasets are created simply from files, and label information is retrieved from the file name[3]. Moreover, some images that had annotations not related to the specific disease itself, but to the low quality of the image, like “lens dust” or “optic disk photographically invisible” are removed from the dataset as they do not play a decisive role in determining patient’s disease.
其次,图像被标记。 data.csv文件中的图像注释存在问题,因为标签一次涉及到两只眼睛(左右),而每只眼睛可能患有不同的疾病。 例如,如果左眼患有白内障而右眼具有正常眼底,则标签将是白内障,并不表示对右眼的诊断。 幸运的是,诊断关键字与一只眼睛有关。 数据集的创建方式是向模型提供输入作为左眼和右眼图像,然后返回整体(对于双眼)累积的诊断,而忽略了一只眼睛可以健康的事实。 我认为,从这种模型的最终用户的角度来看,这是没有意义的,最好分别为每只眼睛进行预测,以了解例如应治疗哪只眼睛。 因此,我通过在诊断关键字与疾病标签之间创建映射来丰富了数据集。 这样,每只眼睛都被分配了一个适当的标签。 该映射的片段以字典的形式呈现在图1中。通过重命名图像名称来添加标签信息,更具体地说,是通过在图像文件名称中添加一个或多个对应于特定疾病的字母来添加标签信息。 我之所以应用此解决方案,是因为这样一来,我不需要存储带有所有标签的任何其他数据框。 重命名文件是一项非常快速的操作,在TensorFlow官方文档中,仅从文件创建TensorFlow数据集,并从文件名中检索标签信息[3]。 此外,一些注释与特定疾病本身无关,但与图像质量低下有关的图像(例如“镜头尘”或“照相上看不见的光盘”)会从数据集中删除,因为它们在图像处理中不起决定性作用。确定患者的疾病。

Thirdly, the validation set is created by randomly selecting 30% of all available images. I chose 30% because this dataset is relatively small (only 7000 images in total), but I wanted to make my validation representative enough, not to have a bias when evaluating model, related to the fact, that many image variants or classes could not have their representation in the validation set. The ODIR dataset provides testing images, but unfortunately, no labeling information is provided to them in the data.csv file, thus I could not use available testing images to evaluate the model.
第三,通过随机选择所有可用图像的30%来创建验证集。 我选择30%是因为该数据集相对较小(总共仅7000张图像),但是我想使我的验证具有足够的代表性,而在评估模型时不要有偏见,这与事实有关,即许多图像变体或类不能在验证集中具有它们的表示形式。 ODIR数据集提供测试图像,但是不幸的是,在data.csv文件中没有为它们提供标签信息,因此我无法使用可用的测试图像来评估模型。
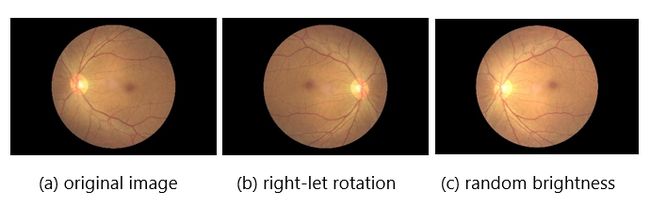
Next, data augmentation on minority classes was applied on the training set to balance the dataset. Random zoom, random rotation, flip left-right, flip top-bottom were applied. In the beginning, I used the TensorFlow dataset object for applying data augmentation “on the fly” while training the model[4] in order to keep my solution as scalable as possible. Unfortunately, it lacks many features like random rotation, therefore I performed data augmentation before creating the TensorFlow dataset object using other libraries for image processing like OpenCV. In the beginning, I also considered enhancing all images by applying contrast-limited adaptive histogram equalization (CLAHE) in order to increase the visibility of local details of an image, but since it was adding a lot of extra noise to the images (especially to the background, which originally is black) I decided not to follow that direction. Examples of data augmentation using my function written using PIL and OpenCV libraries is presented in Fig. 2.
接下来,将少数群体类别的数据增强应用于训练集以平衡数据集。 应用了随机缩放,随机旋转,左右翻转,上下翻转。 最初,我在训练模型时使用TensorFlow数据集对象“动态”应用数据增强[4],以使我的解决方案尽可能地可扩展。 不幸的是,它缺少许多功能,例如随机旋转,因此我在使用其他库(如OpenCV)创建TensorFlow数据集对象之前执行了数据扩充。 刚开始时,我还考虑过通过应用对比度限制的自适应直方图均衡化(CLAHE)来增强所有图像,以提高图像局部细节的可见度,但是由于这样做会给图像增加很多额外的噪音(尤其是背景(本来是黑色的))我决定不遵循这个方向。 使用PIL和OpenCV库编写的函数进行数据扩充的示例如图2所示。
Finally, the TensorFlow dataset object is created. It is developed very similarly to the one presented in official TensorFlow documentation for loading images[5]. Since the library is complicated, and not easy to use for TensorFlow beginners, I would like to share here a summary of my findings on building scalable and fast input pipelines. The tf.data API enables you to build complex input pipelines from simple, reusable pieces. For example, the pipeline for an image model might aggregate data from files in a distributed file system. The tf.data API introduces a tf.data.Dataset abstraction that represents a sequence of elements, in which each element consists of one or more components. For example, in my image pipeline, an element is a single training example, with a pair of tensor components representing the image and its label[6]. With the idea of creating mini-batches, TensorFlow introduces the so-called iterative learning process which is feeding to the model some portion of data (not entire dataset), training, and repeating with another portion, which are called batches. Batch size defines how many examples will be extracted at each training step. After each step, weights are updated. I selected batch size equal to 32, in order to avoid the overfitting problem. With small batch size, weights keep updating regularly and often. The downside of having a small batch size is that training takes much longer than with the bigger size. One important element of tf.data is the ability of the shuffling dataset. In shuffling, the dataset fills a buffer with elements, then randomly samples elements from this buffer, replacing the selected elements with new elements[7]. It prevents situations when images of the same class will be repetitively filled to the batch, which is not beneficial for training the model.
最后,创建TensorFlow数据集对象。 它的开发与TensorFlow官方文档中介绍的用于加载图像的开发非常相似[5]。 由于该库很复杂,而且对于TensorFlow初学者来说不容易使用,因此我想在此分享我在构建可扩展和快速输入管道方面的发现的摘要。 使用tf.data API,您可以从简单,可重用的片段中构建复杂的输入管道。 例如,图像模型的管道可能会聚合分布式文件系统中文件中的数据。 tf.data API引入了tf.data.Dataset抽象,它表示一系列元素,其中每个元素由一个或多个组件组成。 例如,在我的图像管道中,一个元素是一个单独的训练示例,其中有一对张量分量表示图像及其标签[6]。 TensorFlow基于创建迷你批的想法,引入了所谓的迭代学习过程,该过程将部分数据(不是整个数据集)馈入模型,进行训练并与另一部分重复进行,这称为批处理。 批次大小定义了每个训练步骤将提取多少个示例。 每一步之后,权重都会更新。 为了避免过度拟合的问题,我选择了等于32的批量大小。 批量较小时,重量会定期且经常更新。 批量较小的缺点是培训所需的时间比批量较大的要长得多。 tf.data的一个重要元素是改组数据集的功能。 在改组中,数据集用元素填充缓冲区,然后从该缓冲区中随机采样元素,用新元素替换所选元素[7]。 这样可以防止将相同类别的图像重复填充到批次中的情况,这不利于训练模型。
建立卷积神经网络 (Building Convolutional Neural Network)
In deep learning, a convolutional neural network (CNN) is a class of deep neural networks, most commonly applied to analyzing visual imagery[8]. Input layer takes 250x250 RGB images. The first 2D convolution layer shifts over the input image using a window of the size of 5x5 pixels to extract features and save them on a multi-dimensional array, in my example number of filters for the first layer equals 32, so to (250, 250, 32) size cube.
在深度学习中,卷积神经网络(CNN)是一类深度神经网络,最常用于分析视觉图像[8]。 输入层可拍摄250x250 RGB图像。 第一2D卷积层使用5x5像素大小的窗口在输入图像上移动以提取特征并将其保存在多维数组中,在我的示例中,第一层的过滤器数量等于32,因此等于(250, 250,32)尺寸的立方体。
After each convolution layer, a rectified linear activation function (ReLU) is applied. Activation has the authority to decide if neuron needs to be activated or not measuring the weighted sum. ReLU returns the value provided as input directly, or the value 0.0 if the input is 0.0 or less. Because rectified linear units are nearly linear, they preserve many of the properties that make linear models easy to optimize with gradient-based methods. They also preserve many of the properties that make the linear model generalize well[9].
在每个卷积层之后,都应用了整流线性激活函数(ReLU)。 激活有权决定是否需要激活神经元或不测量加权和。 ReLU直接返回作为输入提供的值,如果输入等于或小于0.0,则返回值0.0。 由于整流线性单位几乎是线性的,因此它们保留了许多特性,这些特性使线性模型易于使用基于梯度的方法进行优化。 它们还保留了许多使线性模型泛化的属性[9]。
To progressively reduce the spatial size of the input representation and minimize the number of parameters and computation in the network max-pooling layer is added. In short, for each region represented by the filter of a specific size, in my example it is (5, 5), it will take the max value of that region and create a new output matrix where each element is the max of the region in the original input.
为了逐步减小输入表示的空间大小并最大程度地减少参数的数量,并添加了网络最大池化层中的计算。 简而言之,对于由特定大小的过滤器表示的每个区域,在我的示例中为(5,5),它将采用该区域的最大值并创建一个新的输出矩阵,其中每个元素为该区域的最大值在原始输入中。
To avoid overfitting problems, two dropouts of 45% layers were added. Several batch normalization layers were added to the model. Batch normalization is a technique for improving the speed, performance, and stability of artificial neural networks[10]. It shifts the distribution of neuron output, so it better fits the activation function.
为避免过度拟合的问题,添加了两个45%的滤除层。 几个批处理归一化层已添加到模型中。 批处理规范化是一种用于提高人工神经网络的速度,性能和稳定性的技术[10]。 它改变了神经元输出的分布,因此更适合激活功能。
Finally, the “cube” is flattened. No fully connected layers are implemented to keep the simplicity of the network and keep training fast. The last layer is 8 dense because 8 is the number of labels (diseases) present in the dataset. Since we are facing multi-label classification (data sample can belong to multiple instances) sigmoid activation function is applied to the last layer. The sigmoid function converts each score to the final node between 0 to 1, independent of what other scores are (in contrast to other functions like, for example, softmax), that is why sigmoid works best for the multi-label classification problems. Since we are using the sigmoid activation function, we must go with the binary cross-entropy loss. The selected optimizer is Adam with a low learning rate of 0.0001 because of the overfitting problems that I was facing during the training. The entire architecture of my CNN is presented in Fig.3.
最后,“立方体”被展平。 没有实现完全连接的层来保持网络的简单性并保持快速的培训。 最后一层是8致密的,因为8是数据集中存在的标记(疾病)的数量。 由于我们面临着多标签分类(数据样本可以属于多个实例),因此将S型激活函数应用于最后一层。 sigmoid函数将每个分数转换为0到1之间的最终节点,而与其他分数无关(与诸如softmax之类的其他函数相反),这就是为什么sigmoid最能解决多标签分类问题。 由于我们使用的是S型激活函数,因此必须考虑二进制交叉熵损失。 所选的优化器是Adam,学习速度为0.0001,因为我在培训过程中遇到了过度拟合的问题。 我的CNN的整个架构如图3所示。

实验与结果 (Experiments and Results)
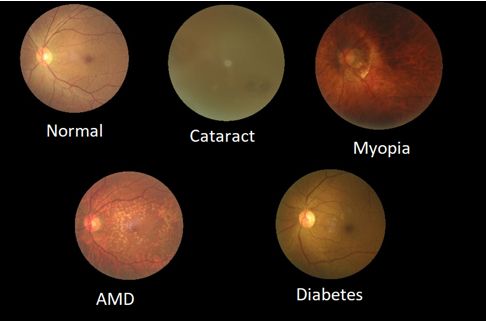
For simplicity, I wanted to start my research with easy proof-of-concept experiments, on less challenging and smaller datasets, to test if all previous assumptions were correct. Thus, I started training a simple model to detect if an eye has normal fundus or cataract, training only on images labeled as N (normal) or C (cataract). The results were very satisfactory, using a relatively simple network in 12 epochs my model got 93% on validation accuracy. This already shows that using CNN it is possible to automatically detect eye cataracts! In each next experiment, I was adding to the dataset images of another class. The fourth experiment is performed on the entire ODIR dataset, achieving almost 50% validation accuracy. Results from the experiments are presented in Table 1. As we can clearly see the overall model has low results because it is hard to train it to detect diabetes correctly since the eye with diabetes looks almost the same as the eye with normal fundus. Detecting myopia or cataract is a much easier task because these images vary a lot from each other and from the normal fundus. Illustration of different selected diseases is presented in the Fig. 4.
为简单起见,我想从简单的概念验证实验开始研究,以减少挑战性和缩小数据集的方式来测试所有先前的假设是否正确。 因此,我开始训练一个简单的模型来检测眼睛是否具有正常的眼底或白内障,仅对标记为N(正常)或C(白内障)的图像进行训练。 结果非常令人满意,在12个时间段内使用相对简单的网络,我的模型的验证准确性达到93%。 这已经表明,使用CNN可以自动检测眼睛白内障! 在接下来的每个实验中,我都将另一个类的图像添加到数据集中。 第四个实验是在整个ODIR数据集上进行的,验证精度几乎达到50%。 实验结果列于表1。我们可以清楚地看到整个模型的结果很低,因为很难训练它正确地检测出糖尿病,因为糖尿病眼与眼底正常的眼几乎一样。 检测近视或白内障是一个容易得多的任务,因为这些图像彼此之间以及与正常眼底之间存在很大差异。 图4给出了不同选定疾病的图示。

For all experiments, the same neural network architecture was used. The only difference is the number of epochs each experiment needed to get to the presented results (some needed to be early stopped, others needed more epochs to learn). Also, for experiments that did not include the entire dataset, softmax activation function, and categorical cross-entropy loss were used since they are multi-class, not multi-label classification problems.
对于所有实验,使用相同的神经网络架构。 唯一的区别是每个实验达到提出的结果所需的时期数(有些需要提前停止,其他的则需要更多的时期来学习)。 另外,对于不包含整个数据集的实验,使用softmax激活函数和分类交叉熵损失,因为它们属于多类而非多标签分类问题。
关于模型可伸缩性的最终考虑 (Final Considerations on Model Scalability)
Nowadays, in the world of Big Data, it is crucial to evaluate every IT project, based on its scalability and reproducibility. From the beginning of the implementation of this project, I put a lot of emphasis on the idea, that even though it is a research project, maybe in the future with more data points of eye diseases the model could be re-trained, and certainly will achieve much better results having more images to train on. So, the main goal was to build a universal data pipeline that is able to handle many more datapoints. This goal was mostly achieved by using advanced TensorFlow library, especially with the dataset object, that supports ETL processes (Extract, Transform, Load) on large datasets. Unfortunately, some transformations were needed to be done before creating the TensorFlow dataset object, which are image resizing and augmenting minority classes. Maybe in the future, it will be possible to resize images “on the fly” faster, and more augmentation functions would be added like random rotation, which was already mentioned before. But if we consider having more data points in the future, possibly it would not be necessary to perform any augmentations, as sufficiently enough image variations would be provided. From the perspective of other popular datasets used in deep learning projects, ODIR would be considered as a small one. That is the reason why data points had to be augmented and oversampled in order to achieve sensible results.
如今,在大数据世界中,至关重要的是根据其可伸缩性和可再现性评估每个IT项目。 从这个项目的实施开始,我就非常强调这个想法,即使这是一个研究项目,也许将来在有更多眼病数据点的情况下,该模型可以重新训练,当然可以训练更多图像,效果会更好。 因此,主要目标是建立一个能够处理更多数据点的通用数据管道。 此目标主要是通过使用高级TensorFlow库(尤其是与支持大型数据集上的ETL流程(提取,转换,加载)的数据集对象)来实现的。 不幸的是,在创建TensorFlow数据集对象之前需要进行一些转换,这些转换是图像大小调整和增强少数类。 也许在将来,可以更快地“即时”调整图像大小,并且将添加更多的增强功能,例如之前已经提到的随机旋转。 但是,如果我们考虑在将来拥有更多的数据点,则可能不需要进行任何扩充,因为将提供足够的图像变化。 从深度学习项目中使用的其他流行数据集的角度来看,ODIR将被视为一小部分。 这就是为什么必须对数据点进行扩充和过采样才能获得合理的结果的原因。
摘要 (Summary)
In this project, I have proved that it is possible to detect various eye diseases using convolutional neural networks. The most satisfying result is detecting cataracts with 93% accuracy. Examining all the diseases at one time, gave significantly lower results. With the ODIR dataset providing all-important variations of a specific disease to the training model was not always possible, which affects the final metrics. Although, I am sure that having a bigger dataset, would increase the accuracy of predictions and finally automate the process of detecting ocular diseases.
在这个项目中,我证明了可以使用卷积神经网络检测各种眼部疾病。 最令人满意的结果是以93%的准确度检测白内障。 一次检查所有疾病,结果明显偏低。 利用ODIR数据集,不可能总是向训练模型提供特定疾病的所有重要变化,这会影响最终指标。 虽然,我相信拥有更大的数据集会提高预测的准确性,并最终使眼部疾病的检测过程自动化。
翻译自: https://towardsdatascience.com/ocular-disease-recognition-using-convolutional-neural-networks-c04d63a7a2da
卷积网络和卷积神经网络