Pytorch的学习——U-Net语义分割
U-Net
UNet是通过自编码的形式实现物体的分类与预测,其主体由一个编码器与一个解码器组成,结构如下图。
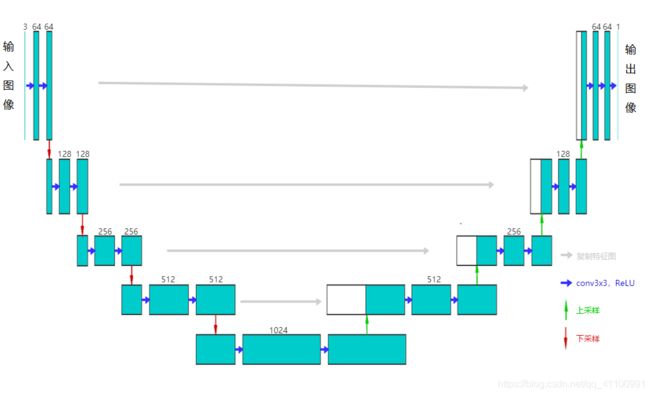
该网络先对维度为(3,H,W)的图像进行4次下采样,再进行上采样,用之前的低层特征图,与上采样后的特征图进行融合,重复上采样和融合过程直到得到与输入图像尺寸相同的分割图,输出结果图的维度为(1,H,W),最后通过sigmoid()函数将数值化为(0,1)区间,得到输出图。
模型代码
import torch.nn as nn
import torch
class DoubleConv(nn.Module):
def __init__(self, in_ch, out_ch):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1), # in_ch、out_ch是通道数
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, in_ch, out_ch):
super(UNet, self).__init__()
# 编码器
self.conv1 = DoubleConv(in_ch, 64)
self.pool1 = nn.MaxPool2d(2) # 池化,每次把图像尺寸缩小一半
self.conv2 = DoubleConv(64, 128)
self.pool2 = nn.MaxPool2d(2)
self.conv3 = DoubleConv(128, 256)
self.pool3 = nn.MaxPool2d(2)
self.conv4 = DoubleConv(256, 512)
self.pool4 = nn.MaxPool2d(2)
self.conv5 = DoubleConv(512, 1024)
# 解码器
self.up6 = nn.ConvTranspose2d(1024, 512, 2, stride=2)
self.conv6 = DoubleConv(1024, 512)
self.up7 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.conv7 = DoubleConv(512, 256)
self.up8 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.conv8 = DoubleConv(256, 128)
self.up9 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.conv9 = DoubleConv(128, 64)
self.conv10 = nn.Conv2d(64, out_ch, 1)
def forward(self, x):
c1 = self.conv1(x)
p1 = self.pool1(c1)
c2 = self.conv2(p1)
p2 = self.pool2(c2)
c3 = self.conv3(p2)
p3 = self.pool3(c3)
c4 = self.conv4(p3)
p4 = self.pool4(c4)
c5 = self.conv5(p4)
up_6 = self.up6(c5)
'''
将底层特征图c4与当前层特征图合并,这里c4的通道数为512,up_6的通道数
也为512,合并后的通道数变为1024,其他不变
'''
merge6 = torch.cat([up_6, c4], dim=1)
c6 = self.conv6(merge6)
up_7 = self.up7(c6)
merge7 = torch.cat([up_7, c3], dim=1)
c7 = self.conv7(merge7)
up_8 = self.up8(c7)
merge8 = torch.cat([up_8, c2], dim=1)
c8 = self.conv8(merge8)
up_9 = self.up9(c8)
merge9 = torch.cat([up_9, c1], dim=1)
c9 = self.conv9(merge9)
c10 = self.conv10(c9)
out = nn.Sigmoid()(c10) # 化成(0~1)区间
return out
训练
神经网络离不开样本集、模型、训练以及对训练完的模型的调用。
本文是火焰识别的一个样列,其部分样本集如下图。

样本集主要由三通道的彩图以及单通道的二值图组成,其中二值图白色为原图中火焰部分对应的位置,黑色为非火焰部分对应的位置,训练的时候以彩图为数据,二值图为标签。
样本集准备好了,那么如何读取就是个问题,这里官方提供了重写dataset的方法,代码如下:
import torch.utils.data as data
import os
import cv2
# data.Dataset:所有子类必须重写__len__和__getitem__方法,前者提供了数据集的大小,后者支持整数索引,范围从0到len(self)
class MyDataset(data.Dataset):
# root表示图片路径,transform,target_transform为tensor提供的图像处理的一些方法
def __init__(self, root, transform=None, target_transform=None):
files = os.listdir(root)
imgs = []
'''
将原图与二值图一一对应,并生成对应的列表即[[[img1],[mask1]],[[img2],[mask2]],...]
其中img代表原图的绝对路径,mask代表原图对应的二值图的绝对路径
'''
img = ""
mask = ""
for file in files:
if file.find("jpg") != -1:
img = os.path.join(root, file)
if file.find("png") != -1:
mask = os.path.join(root, file)
if mask != "":
imgs.append([img, mask])
mask = ""
img = ""
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
'''
这里是图片读取方法,本文用的是opencv
这里需要注意,opencv与PIL不能混合使用,因为两种库的读取图像的算法不一样,
会有误差,并造成最后识别效果差,所以一般在识别的时候用到哪个库就使用哪种库。
'''
x_path, y_path = self.imgs[index]
img_x = cv2.imread(x_path)
img_x = cv2.resize(img_x, (352, 288))
img_y = cv2.imread(y_path, cv2.IMREAD_GRAYSCALE)
img_y = cv2.resize(img_y, (352, 288))
if self.transform is not None:
img_x = self.transform(img_x)
if self.target_transform is not None:
img_y = self.target_transform(img_y)
return img_x, img_y # 返回的是图片
def __len__(self):
return len(self.imgs)
数据读取准备好后就到训练了
import torch
from torchvision.transforms import transforms as T
from other.UNet.UNet import UNet
from torch import optim
from other.UNet.Dataset import MyDataset
from torch.utils.data import DataLoader
x_transform = T.ToTensor()
y_transform = T.ToTensor()
# 训练模型
def train():
model = UNet(3, 1).cuda()
batch_size = 16
num_epochs = 100
# 损失函数
loss_func = torch.nn.BCELoss()
# 梯度下降
optimizer = optim.Adam(model.parameters(), lr=0.0001)
# 加载数据集
my_dataset = MyDataset("[数据集的路径]", transform=x_transform, target_transform=y_transform)
dataload = DataLoader(my_dataset, batch_size=batch_size, shuffle=True)
# DataLoader:该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor
# batch_size:how many samples per minibatch to load,这里为16,数据集大小400,所以一共有100个minibatch
# shuffle:True代表从数据集中一次随机抽取batch_size个数据进行训练,False就是按顺序抽取数据
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
dataset_size = len(dataload.dataset)
epoch_loss = 0
for step, (x, y) in enumerate(dataload):
if torch.cuda.is_available():
with torch.no_grad():
b_x = x.cuda()
b_y = y.cuda()
output = model(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print("%d/%d,train_loss:%0.3f" % (step, dataset_size // dataload.batch_size, loss.item()))
print("epoch %d loss:%0.3f" % (epoch, epoch_loss))
torch.save(model.cpu(), './unet_448.pkl') # 返回模型的所有内容
if __name__ == '__main__':cc
train()
训练中如图:
测试
import cv2
import os
import torch.nn as nn
import numpy as np
import torch
import torchvision.transforms as transforms
if __name__ == '__main__':
model = torch.load('../network/unet_448.pkl').cuda()
preprocess_transform = transforms.Compose([
transforms.ToTensor(),
])
capture = cv2.VideoCapture(r"C:\Study\Python\Projects\FireRecognition\medias\videos\1.mp4")
while True:
ret, frame = capture.read()
if not ret:
break
frame = cv2.resize(frame, (352, 288)) # 归一化大小
frame = preprocess_transform(frame) # 转换为tensor
frame.unsqueeze_(0) # 将维度变为[1, 352, 288, 3]
outputs = model(frame1.cuda())
mask = outputs.cpu().detach().numpy()[0].reshape(288, 352, 1)
cv2.imshow("mask", mask)
# 二值化
ret, a = cv2.threshold(mask, 0.9, 255, cv2.THRESH_BINARY)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
a = cv2.morphologyEx(a, cv2.MORPH_CLOSE, kernel)
a = np.uint8(a)
# 寻找轮廓图
contours, hierarchy = cv2.findContours(a, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for c in contours:
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 1)
cv2.imshow("frame", frame)
cv2.waitKey(10)
效果如下图所示:
